Kafka分布式事务详解与关键设计
版权申诉
124 浏览量
更新于2024-07-01
收藏 1.79MB DOC 举报
Kafka的稳定性是其作为分布式消息传递系统的关键特性之一,本文将深入探讨Kafka如何实现事务管理和确保数据一致性。首先,理解事务在Kafka中的重要性,它是处理分布式场景下的核心需求,例如应用之间的消费-处理-生产(Consume-Transform-Produce)流程,其中消息的顺序性和原子性至关重要。在出现故障时,比如producer宕机或网络中断,Kafka通过事务机制确保要么所有消息都被消费者看到,要么都不被看到,避免了数据丢失或脏数据的问题。
Kafka的事务支持基于两阶段提交(2PC),引入了TransactionCoordinator(事务协调器)来管理分布式事务的生命周期。TransactionCoordinator的角色类似于之前为了防止分区分裂和节点故障而引入的GroupCoordinator,它们在协调者选举和故障转移方面有相似的机制。事务管理中,Kafka利用内部topic来存储事务日志,仅记录最新的事务状态,以减少存储开销并简化恢复过程。
控制消息(Control Message)的存在是为了标记事务状态,区分commit和abort操作,并允许不同的隔离级别(readcommitted和read uncommitted)。这要求消息队列系统具备识别事务状态的能力。在Kafka中,每个事务都有一个TransactionalId,这是用户预配置的唯一标识符,用于追踪和关联未完成的事务。然而,由于Kafka不支持全局有序,因此TransactionalId是本地的,由用户指定,以确保事务的正确关联。
当producer出现问题,比如重启或迁移,另一个拥有相同TransactionalId的producer可以接管并继续处理未完成的事务。为了防止多个producer同时使用相同的TransactionalId导致混乱,Kafka引入了producer id的概念,确保每个实例的唯一性。
总结来说,Kafka的事务稳定性通过分布式事务协调、事务日志、控制消息以及TransactionalId的管理来实现,保证了数据在分布式环境下的可靠性和一致性,这对于构建高可用、高性能的实时数据流应用程序至关重要。
与他们相关联)
⼀旦标记被写⼊,事务协调器将事务标记为“完成”,并且 Producer 可以开始下⼀个事务。
2. 幂等性
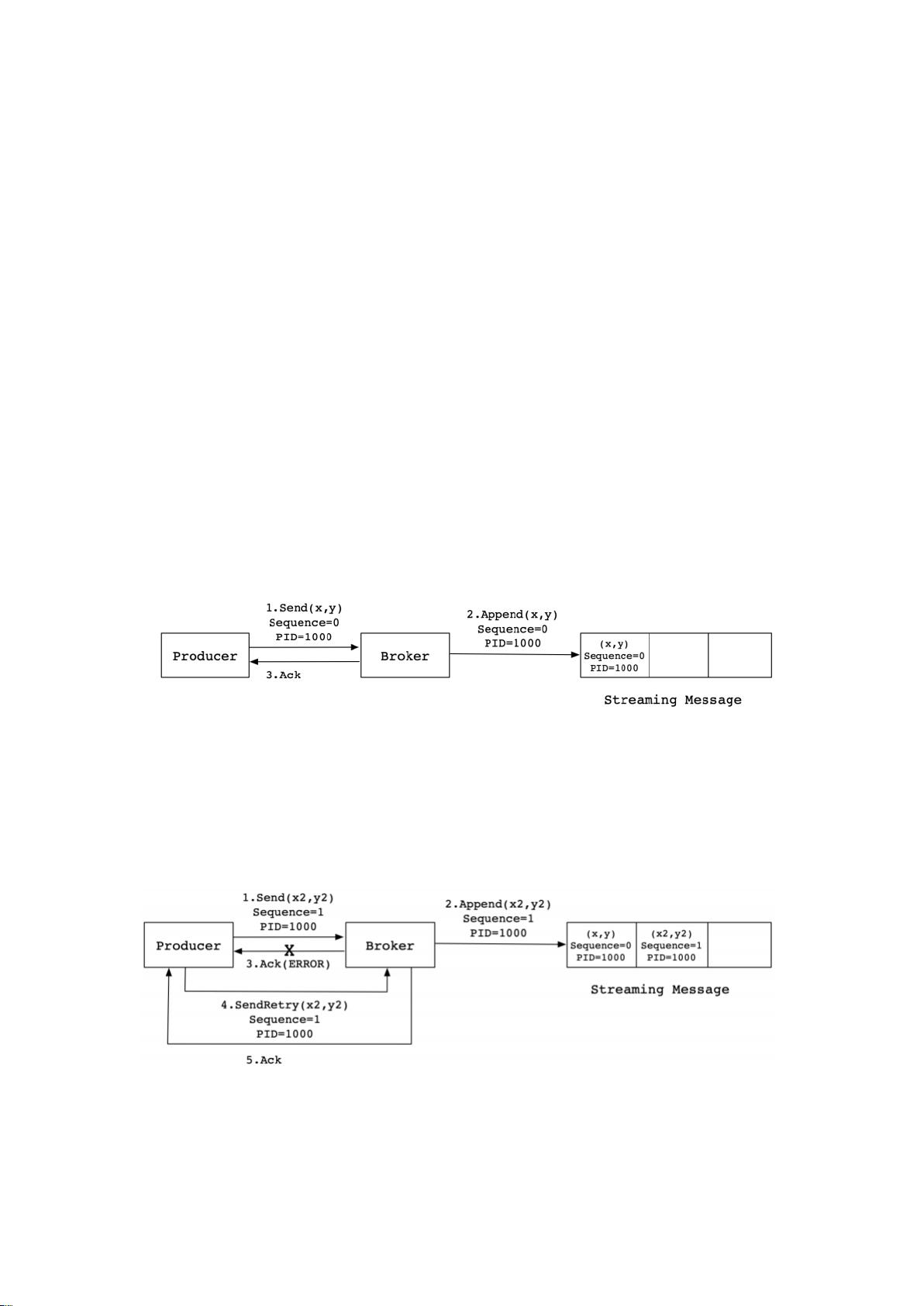
Kafka 在引⼊幂等性之前,Producer 向 Broker 发送消息,然后 Broker 将消息追加到消息
流中后给 Producer 返回 Ack 信号值。实现流程如下:
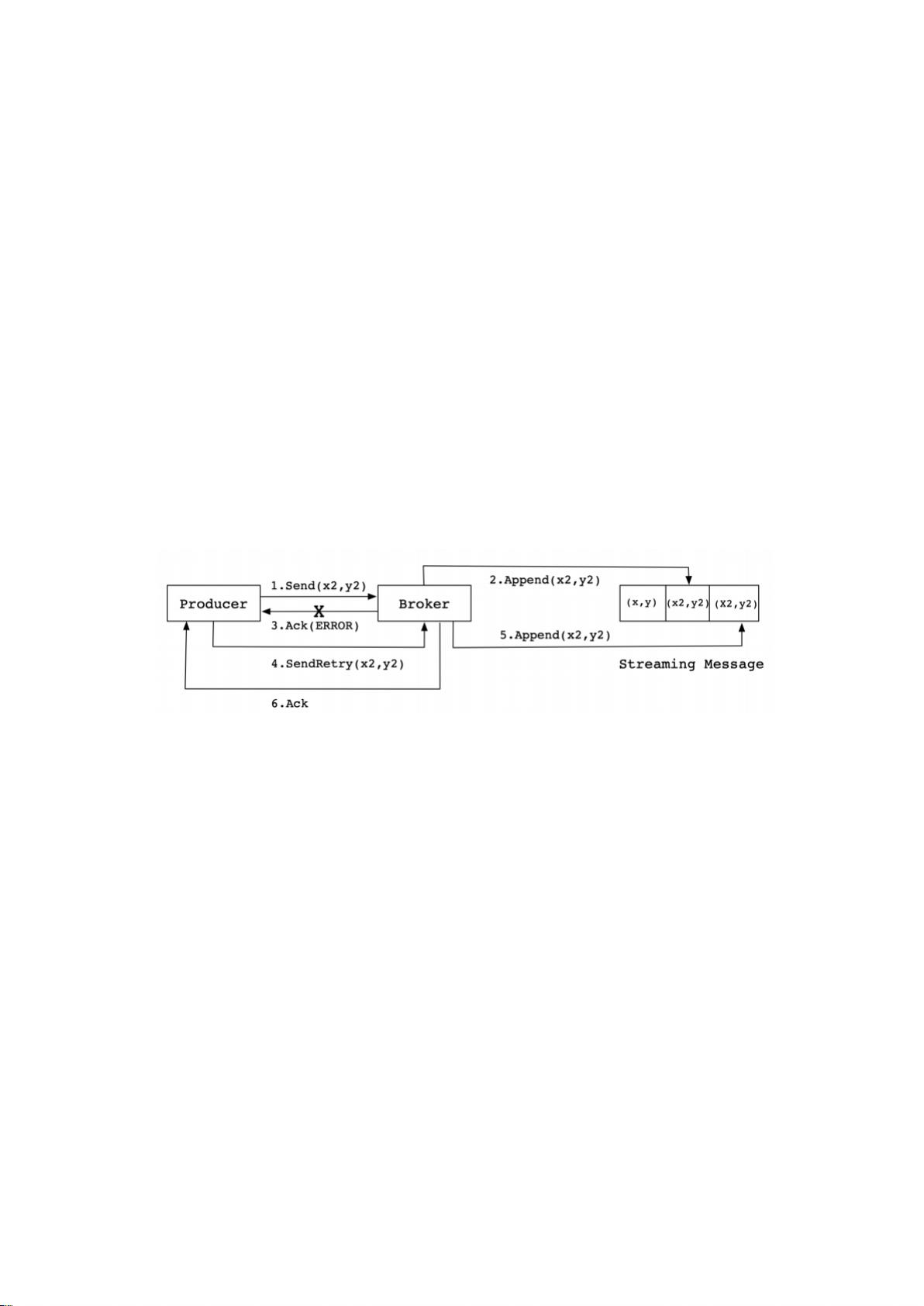
⽣产中,会出现各种不确定的因素,⽐如在 Producer 在发送给 Broker 的时候出现⽹络异
常。⽐如以下这种异常情况的出现:
上图这种情况,当 Producer 第⼀次发送消息给 Broker 时,Broker 将消息(x2,y2)追加到了
消息流中,但是在返回 Ack 信号给 Producer 时失败了(⽐如⽹络异常) 。此时,Producer
端触发重试机制,将消息(x2,y2)重新发送给 Broker,Broker 接收到消息后,再次将该消息追
加到消息流中,然后成功返回 Ack 信号给 Producer。这样下来,消息流中就被重复追加了两
条相同的(x2,y2)的消息。
幂等性
保证在消息重发的时候,消费者不会重复处理。即使在消费者收到重复消息的时候,重复
处理,也要保证最终结果的⼀致性。
所谓幂等性,数学概念就是:f(f(x)) = f(x)。f 函数表示对消息的处理。
⽐如,银⾏转账,如果失败,需要重试。不管重试多少次,都要保证最终结果⼀定是⼀致

剩余51页未读,继续阅读
2022-07-13 上传
2019-07-09 上传
2019-09-04 上传
2021-02-05 上传
2022-07-08 上传
2020-07-20 上传
2022-07-09 上传
2021-03-23 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
