HDFS体系结构解析:NameNode与DataNode详解
需积分: 0 51 浏览量
更新于2024-08-03
收藏 700KB DOCX 举报
"本文将深入探讨Java-HDFS(Hadoop Distributed File System)的体系结构与基本概念。"
在分布式计算领域,HDFS是一个关键组件,尤其在处理大数据存储和处理任务时。它是一个高度容错的系统,设计用于在廉价硬件上运行,支持一次写入、多次读取的数据模型。HDFS不支持并发写入,也不适合存储大量的小文件,因为它的设计主要是为了优化大文件的存储和检索效率。
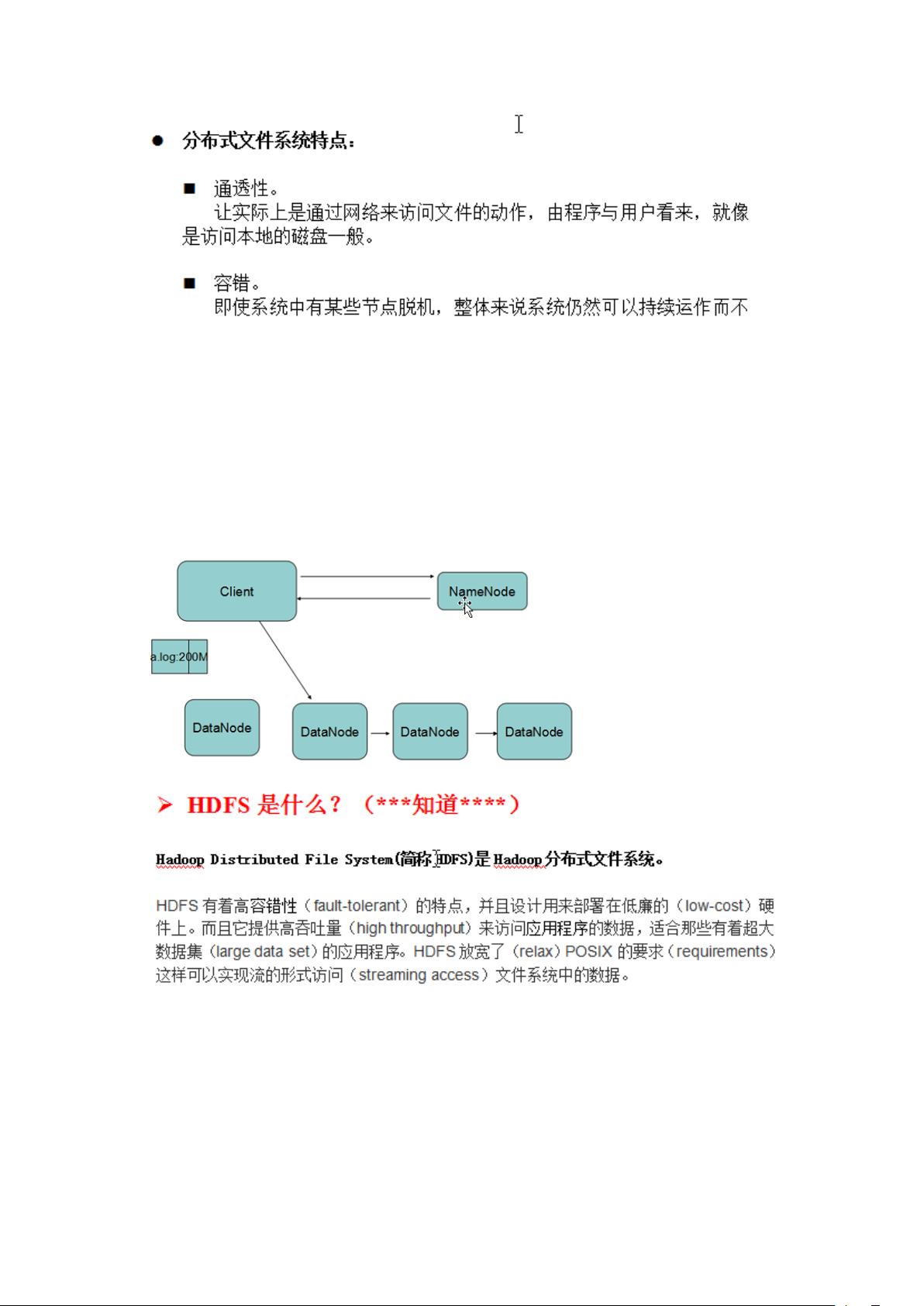
HDFS的核心由两个主要角色组成:NameNode和DataNode。
1. NameNode:作为HDFS的主节点,NameNode负责存储和管理整个文件系统的元数据。这包括文件系统命名空间(文件和目录的层次结构)以及文件块到DataNode的映射信息。NameNode并不实际存储数据,而是充当文件系统的目录服务,接收客户端的请求,如打开、关闭、重命名文件或目录,并维护这些操作的日志记录。
2. DataNode:DataNode是HDFS的工作者节点,它们存储实际的数据块。当客户端写入文件时,DataNode会接收来自NameNode的指令,接收并存储数据块。同时,DataNode也会定期向NameNode发送心跳信息,报告其健康状态和所存储的数据块信息。
在分布式开发中,考虑到IP地址可能变化的问题,通常会使用keepalived和LVS(Linux Virtual Server)这样的技术来实现IP漂移,确保服务的高可用性。心跳机制是DataNode向NameNode报告其状态的一种方式,而keepalived则可以用来监控和备份NameNode,确保在主NameNode故障时能够快速切换到备份NameNode。
在Java中与HDFS交互,需要引入相应的jar包,例如hadoop-client。开发人员可以使用Java API来执行文件操作,如创建、读取、写入和删除文件。在Eclipse中,可以通过新建Java Project,导入所需的jar包,然后编写客户端代码来实现HDFS操作。一旦代码编写完成,可以将其上传到运行Hadoop的虚拟机上,并通过JVM执行。
HDFS使用Client-Server架构,客户端(Client)通过RPC(Remote Procedure Call)与服务器端(Server)进行通信。例如,客户端可能会有一个名为`RPCClient_HdfsClient`的类,而服务器端可能有一个`mainRPCServer_NodeName`的类,用于实现Hadoop中特定的ClientProtocal接口。Hadoop允许在远程服务器上调试代码,这对于开发者来说非常有用,尤其是在处理复杂问题时。
在HDFS中,如果发生非正常关闭,可能需要清理NameNode和DataNode的数据日志文件,以便在重启时重新初始化系统。这些文件通常位于特定的目录下,如`/var/lib/hadoop-hdfs/`或`/tmp/hadoop-hdfs`。
Java-HDFS的体系结构涉及NameNode和DataNode的协同工作,通过Java API提供对HDFS的访问,采用Client-Server模式进行通信,并依赖于心跳机制和故障恢复策略来保证系统的稳定性和可靠性。对于大数据应用程序的开发者而言,理解和掌握这些基本概念至关重要。
分布式文件管理系统,包括 hdfs,适用于一次写入多次查询的情况,不支持并发写情况,小
文件不合适
2.Hdfs 体系结构与基本概念
nameNode:源数据信息。放目录索引
dataNode:真实数据
下载后可阅读完整内容,剩余9页未读,立即下载
2014-05-07 上传
2023-10-01 上传
2018-09-07 上传
2022-10-21 上传
2016-04-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

paterWang
- 粉丝: 1252
- 资源: 2211
 我的内容管理
展开
我的内容管理
展开







最新资源
- pexeso:具有用户管理功能的存储卡游戏,将考验您的智慧!
- DocMods_XpBook:一本书给你经验
- Juan-Luis-Fabrega --- PHYS3300--:PHYS3300 Juan Luis Fabrega存储库
- Excel模板00原材料明细账.zip
- PHRETS:PHP客户端库,用于与RETS服务器进行交互,以获取可从MLS系统获得的房地产清单,照片和其他数据
- picker:通过字符串路径键选择json数据中的属性
- 【地产资料】XX地产 培训体系课程分享P11.zip
- Hacko-4-code4bbs
- music_recommendation_sys:音乐推荐系统
- Android项目实战——应用市场
- vue-simple-markdown:用于Vue的简单高速Markdown解析器
- angular-2fopaf:由StackBlitz创建
- Excel模板00总账.zip
- visualizations:Endcoronavirus.org的“绿区”排名可视化
- matlab-(含教程)基于EKF扩展卡尔曼滤波的SLAM地图路线规划matlab仿真
- elm-flatris:Elm语言的Flatris克隆
