UCAS-AI课程:约束条件下聚类的挑战与方法
需积分: 0 39 浏览量
更新于2024-06-30
收藏 1.14MB PDF 举报
本章节标题为"UCAS-AI模式识别2020_13_ 聚类011", 主要内容围绕数据聚类这一主题展开,聚焦于在实际应用中遇到的具有约束条件的聚类问题。聚类是数据挖掘中的重要技术,它通过分析未标记数据,将对象划分为具有相似特性的类别,同时保持类别内部的紧密性和类别间的分离性。
在引言部分,首先介绍了聚类的基本概念,指出其目的是根据对象间的相似性将其分为不同的类别。聚类的质量依赖于度量标准的选择,不同的聚类任务可能需要不同的评价指标。例如,欧氏距离和马氏距离是常用的统计聚类方法,它们通过比较样本间的距离来确定聚类中心。
章节进一步区分了不同类型的方法,如统计聚类和概念聚类,前者基于全局数据的整体分布,后者则基于特定的准则或概念来组织数据。针对不同类型的数据,如数值型、离散型和混合型数据,也有相应的聚类策略。例如,K-means是一种基于距离的聚类算法,它假设数据点在高维空间中形成球形或椭圆形的簇,而基于密度的聚类方法如DBSCAN则关注邻域内的稠密区域,而非固定数量的中心点。
身份识别和姿态估计是实际应用中的两个例子,它们展示了聚类在计算机视觉领域的应用。聚类任务的目标是明确地定义样本集的划分,每个类别的描述可以通过类中心或边界的表示,以及聚类树这样的可视化工具来呈现。
章节还讨论了聚类方法的分类,强调了度量准则的重要性,如点对之间的距离度量或密度函数的应用。这些方法的选择取决于具体的问题需求和数据特性,理解并灵活运用不同的聚类算法是提高聚类效果的关键。
本章节提供了一个深入理解数据聚类基础和实践应用的框架,强调了在实际场景中处理约束条件下的聚类挑战,并指导读者如何选择和使用适当的聚类方法。这对于那些在人工智能学院学习模式识别导论的学生来说,是一次系统学习和掌握聚类技术的重要课程内容。
第13页
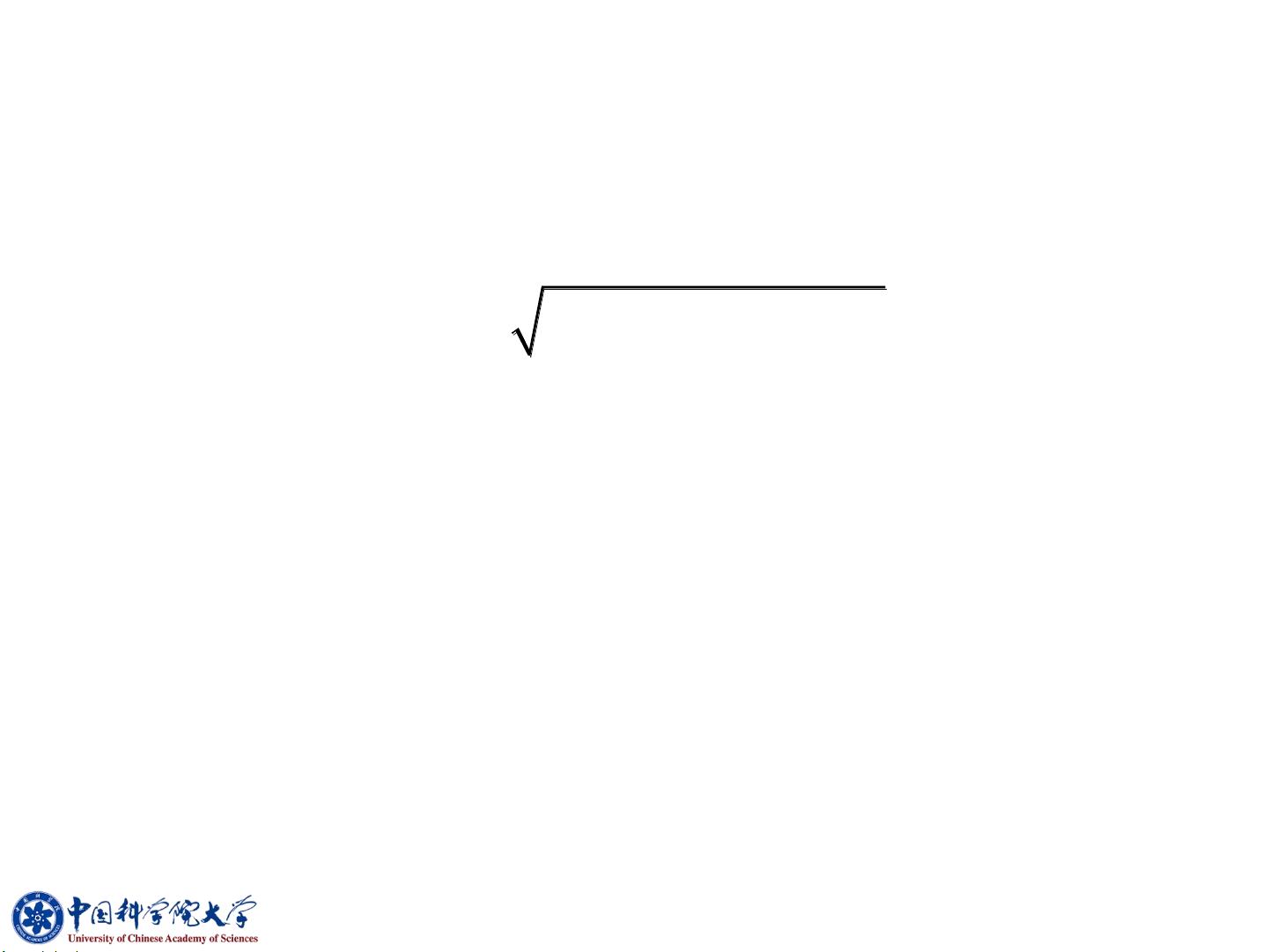
9.2 距离与相似性度量
• 设x, y R
d
, Mahalanobis (马氏)距离定义如下:
– M为单位矩阵时,退化为欧氏距离度量。
– M为对角矩阵时,退化为特征加权欧氏距离
( , ) ( ) ( )
T
d = − −x y x y M x y
其中,M是半正定矩阵。

剩余74页未读,继续阅读
2022-08-04 上传
2022-08-03 上传
2022-08-03 上传
2022-08-04 上传
点击了解资源详情
2022-08-04 上传
2022-08-03 上传
2022-08-03 上传
2024-03-09 上传

邢小鹏
- 粉丝: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- ftpClient工具类包:简化FTP文件操作流程
- 凯立德春季版脚本支持特性解析
- CAXA电子图板自动生成齿轮链轮图库教程
- 北斗BDTXR语句解析及utf8解码技术实现
- 多语言LeetCode编程题解:Java、Python、Javascript
- Robotium测试报告导出实战攻略
- 开源实用工具:快速检查DICOM CDROM
- SSH框架构建医院系统学习项目
- Android MultiType库:轻松实现列表视图多种类型
- 多色复古风免费论文答辩PPT模板下载
- 空档接龙游戏开发教程与JL压缩包文件解析
- 多媒体教室活动安排:优化算法的应用与实现
- WPF中实现GIF动画图片显示的详细教程
- Web Service服务器端代码部署指南
- 韩超深度解析Android系统原理与架构培训课件
- C++图形类实现与面积计算教程
