MySQL分布式集群高可用设计:从理论到实践与解决方案
本文档主要探讨了MySQL分布式数据库集群的高可用设计及其在实际应用中的策略。作者谭俊青来自MySQL实验室,讨论的主题涵盖了CAP理论,以及如何在MySQL环境中实现高可用性(High Availability, HA)以满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)这三个关键原则。
首先,CAP理论是分布式系统设计的核心概念,它表明在一个分布式系统中不可能同时满足一致性、可用性和分区容忍性这三者。在本文中,作者通过以下几种方法来权衡这些特性:
1. MySQL + Shared-Storage: 采用共享存储模式,通过私有IP(如10.10.10.21和10.10.10.20)配置主动服务器和被动服务器,确保数据的一致性,但可能牺牲一定的可用性,因为如果共享存储出现故障,所有节点都会受到影响。
2. MySQL + DRBD (Copy-Partitioned): 使用DRBD(Distributed Replicated Block Device)提供冗余复制,将数据复制到两个不同的物理位置,一个是主DRBD(如10.10.10.21)和一个是从DRBD(如10.10.10.20),通过Linux Heartbeat监控系统状态,提供高可用。在这种模式下,可以通过虚拟IP(10.10.10.10)访问服务,但可能会遇到分区故障的情况。
3. Master+Slave (Semi-Sync Replication): 这种模式允许多个主服务器,通过半同步复制技术保证数据一致性,当主服务器发生故障时,可以自动切换到备机,从而保持服务连续性。私有IP地址用于连接各节点,而虚拟IP(10.10.10.10)作为访问入口。
4. Multi-Master: 在多主模式下,每个节点都可以处理写入请求,提高了系统的并发能力,但可能会带来数据一致性问题,需要特别设计复制策略。
5. MySQL Cluster: 这是一种专为高可用设计的解决方案,它能够实现CAP理论中的CP或AP(Consistency and Partition Tolerance)模式,通过Data Node和NDB API来管理和处理数据,确保在分区的情况下仍能维持一定程度的一致性。
作者提供了针对MySQL分布式数据库集群的不同高可用设计方案,以适应不同的业务需求和性能目标。在选择方案时,需要根据具体应用场景评估各个特性的重要性,并权衡可能出现的挑战,如数据同步延迟、网络分区等。
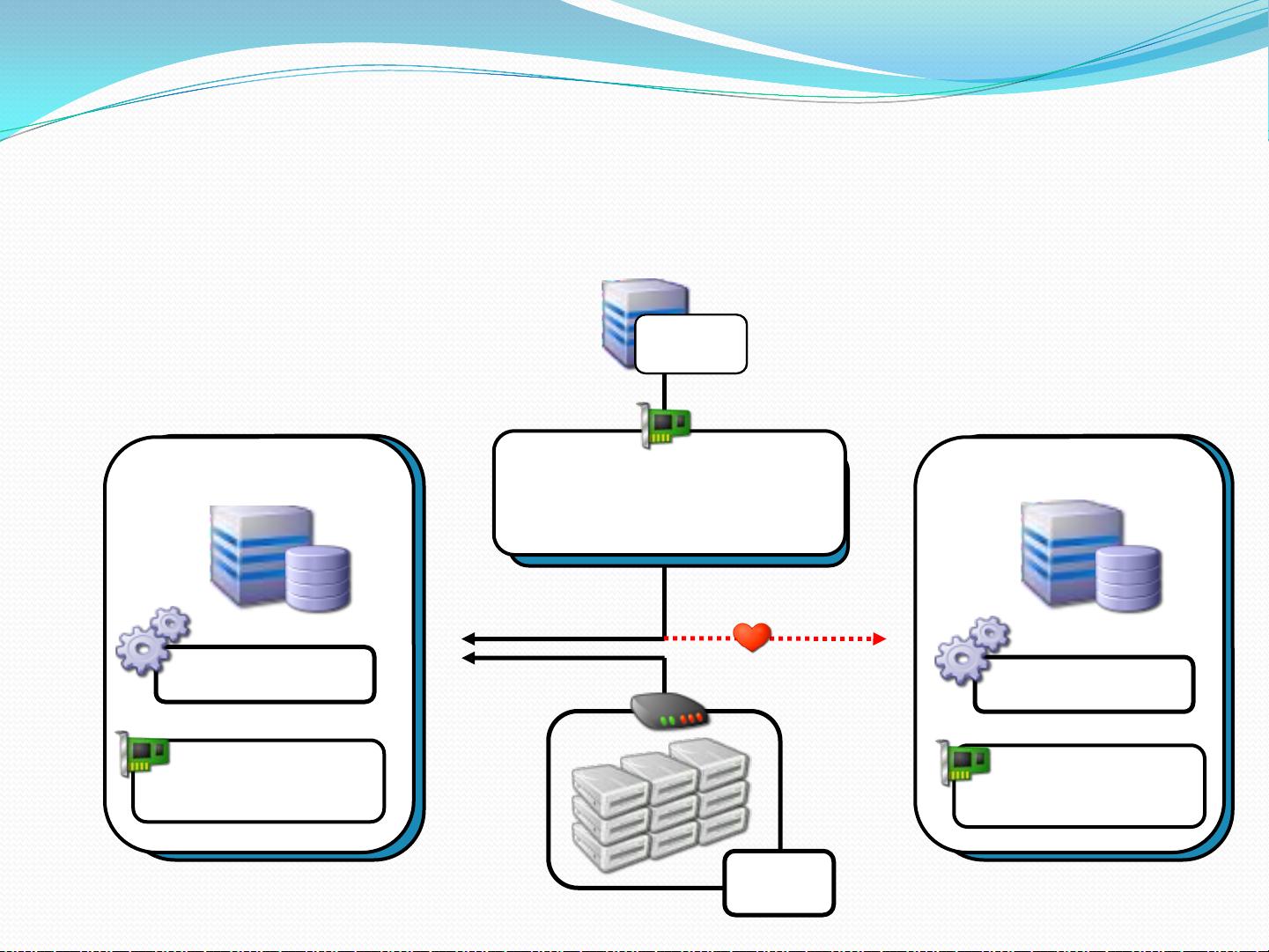
MySQL + Shared-Storage
Active/Passive
= Private IP =
10.10.10.21
Active Server
Passive Server
Cluster Management
= Virtual IP =
10.10.10.10
= Private IP =
10.10.10.20
Cluster Agent
SAN
Web/App
Server
Web/App
Server
Cluster Agent
剩余32页未读,继续阅读
2019-11-21 上传
2021-08-09 上传
点击了解资源详情
2021-02-25 上传
2021-02-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

imliuli
- 粉丝: 233
- 资源: 1351
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
