Git存储原理详解:内容寻址与数据库结构
92 浏览量
更新于2024-08-28
收藏 254KB PDF 举报
"Git存储原理详解"
Git是一个分布式版本控制系统,其强大的功能和高效的数据存储机制是它备受青睐的原因之一。本文将深入探讨Git的存储原理,解析其内部目录结构以及内容寻址的特性。
首先,当我们在项目根目录下执行`git clone`或`git init`命令时,Git会创建一个隐藏的`.git`目录。这个目录是Git存储所有元数据和版本历史的地方。以下是`.git`目录的主要组成部分:
1. **HEAD文件**:它是一个指向当前分支的文本文件,指示当前工作目录所在的分支。
2. **index文件**(也称为 staging area 或 cache):存储了被暂存的文件信息,准备进行下一次提交。
3. **refs目录**:包含了所有分支和标签的引用,每个分支或标签实际上是一个指向特定提交对象的SHA-1哈希值的文件。
4. **objects目录**:这是Git数据库的核心,存储了所有版本化的文件内容和元数据。对象以SHA-1哈希值命名,确保了内容的唯一性和完整性。
5. **config文件**:包含了项目级别的配置信息,如用户信息、远程仓库设置等。
6. **info目录**下的**exclude文件**:定义了项目级别的全局忽略规则,与`.gitignore`文件一起控制哪些文件不被版本化。
7. **hooks目录**:存放自定义的客户端和服务端钩子脚本,可以在特定事件(如提交、推送等)发生时自动执行。
在Git中,一个重要概念是**内容寻址文件系统**。Git使用SHA-1算法对文件内容进行哈希运算,生成一个40位的十六进制字符串作为文件的唯一标识,称为校验和。这样,文件是通过其内容而不是存储位置来寻址的,保证了数据的完整性和一致性。当文件内容改变时,其对应的哈希值也会随之改变。
Git将文件内容分为两种类型的对象:**blob对象**(用于存储文件内容)和**tree对象**(用于组织文件和目录结构)。此外,还有**commit对象**(记录提交信息,包括作者、时间戳和对父提交的引用)和**tag对象**(用于标记特定的提交)。这些对象构成了Git数据模型的基础。
每次提交时,Git会将修改的文件内容转换为blob对象,然后创建一个新的tree对象来表示当前的工作树状态。同时,Git还会创建一个新的commit对象,它引用了当前的tree对象以及上一次提交的commit对象。通过这种链式结构,Git可以追踪整个版本历史。
当需要恢复某个历史版本时,可以通过SHA-1哈希值直接找到相应的对象。Git的回退操作(如`git reset`)就依赖于这种机制,能够快速定位并切换到指定的提交状态。
总结来说,Git的存储原理基于内容寻址和SHA-1哈希,确保了数据的稳定性和可追溯性。理解这一原理有助于更好地利用Git进行版本控制,尤其是在处理复杂的历史分支和合并操作时。通过深入学习和实践,我们可以更有效地管理代码仓库,提高开发效率。
Git由浅入深之存储原理由浅入深之存储原理
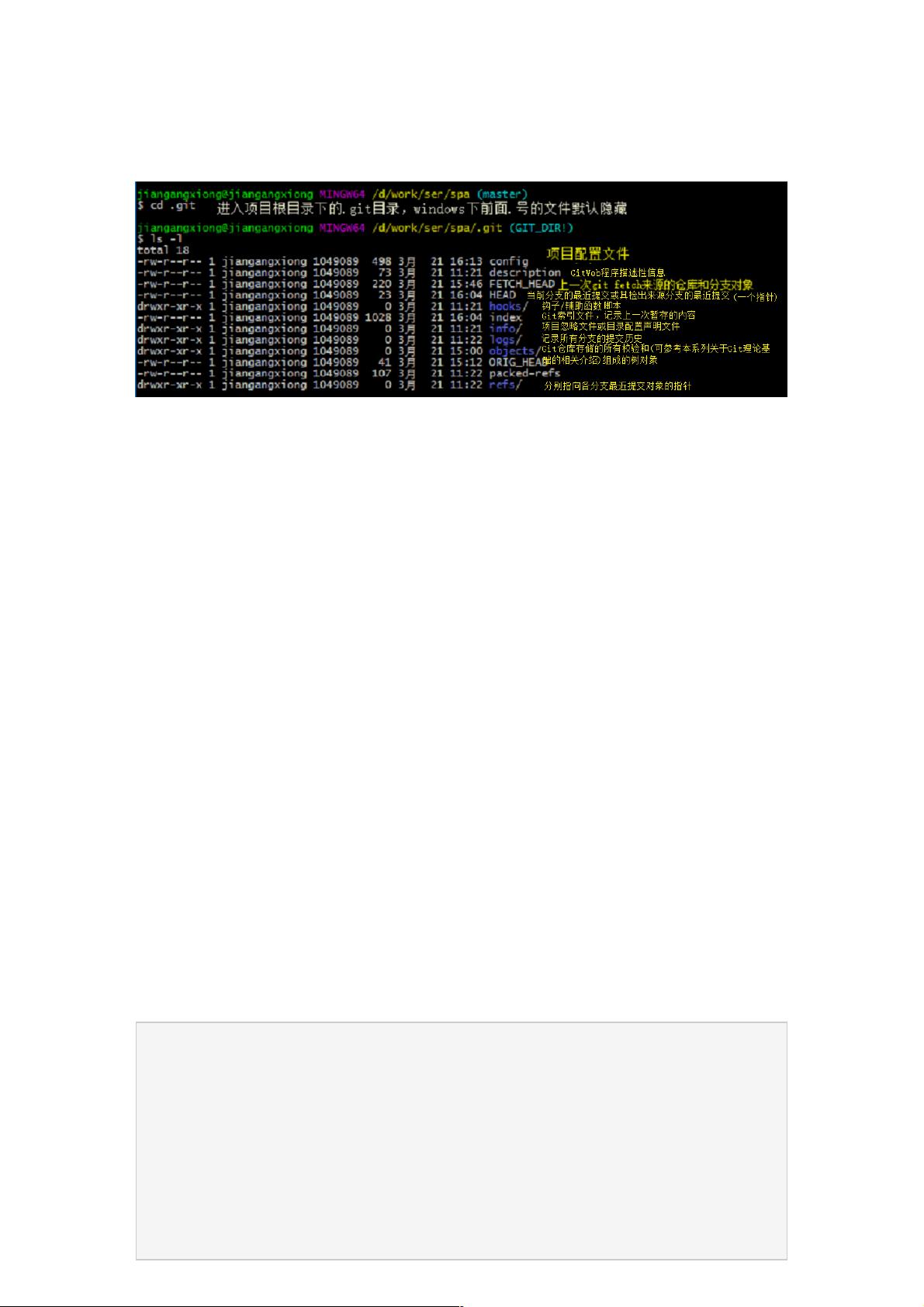
Git存储目录结构
在初始化项目仓库时(git clone 或git init),Git会在根目录下创建一个.git目录,其下存放着Git操作和存储相关的内容,该目
录结构大致如下:
如图中所述:
HEAD文件指向当前分支;
index文件存储着暂存区的内容信息;
refs目录存储着所有分支指向各自提交对象的指针;
objects目录存储着Git数据库的所有内容;
config文件包含项目的配置信息;
info目录下的exclude文件包含项目全局忽略匹配模式,与.gitignore文件互补;
hooks目录则存放项目的客户端或服务端钩子脚本。
注:其中的ORIG_HEAD记录的是在进行极端(drastic)操作(如合并merge,回退reset等)时,此操作之前HEAD所指向的
位置,便于我们在发生毁灭性失误时进行回退,如使用
git reset --hard ORIG_HEAD指令可以回退到危险操作之前的状态,但是对于正常的提交操作,该指针是不会变化的。在1.8.5
版本以后,Git使用了链表记录HEAD的所有移动轨迹,
可以使用git reflog查看,使用git reset HEAD@{num}方式可以回退到指定版本,这也是之后介绍Git数据恢复将要介绍的一个
指令,推荐使用这种方式替代ORIG_HEAD方式。
更多信息可参考此处
Git存储
Git是一个内容寻址文件系统(content-addressed filesystem),其存储内容都是通过内容地址维护,可以把它理解成一个键值对
存储方式:即给定一个存储文件,该系统根据文件信息和内容,使用SHA-1算法计算,返回一个由40个十六进制字符组成的
字符串,之后只需要通过该字符串即可访问该文件,这个字符串就是Git中通常所说的校验和。
内容寻址
在了解Git内部存储原理之前我们先了解下内容寻址:
When being contrasted with content-addressed storage, a typical local or networked
storage device is referred to as location-addressed. In a location-addressed storage device,
each element of data is stored onto the physical medium, and its location recorded for later use.
The storage device often keeps a list, or directory, of these locations.
When a future request is made for a particular item, the request includes only the
location (for example, path and file names) of the data. The storage device can then use this
information to locate the data on the physical medium, and retrieve it. When new information is
written into a location-addressed device, it is simply stored in some available free space,
without regard to its content.
In contrast, when information is stored into a CAS system, the system will record a content address,
which is an identifier uniquely and permanently linked to the information content itself.
A request to retrieve information from a CAS system must provide the content identifier,
from which the system can determine the physical location of the data and retrieve it.
Because the identifiers are based on content, any change to a data element will necessarily
change its content address.
下载后可阅读完整内容,剩余3页未读,立即下载
392 浏览量
点击了解资源详情
188 浏览量
2019-03-17 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38560768
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- S3C2440上运行的UCOS-II操作系统开发代码
- Java完整文件上传下载demo解析
- Angular 8+黄金布局集成方案:ng6-golden-layout概述
- 科因网络OA:党政机关全方位信息化解决方案
- Linux下LAMP环境与PHP网站搭建指南
- 新语聊天系统:ASP.NET C# 实现的WebChat
- 中国移动专线拨测工具:高效测试数据与互联网线路
- AT89S52单片机直流电源设计:原理图、程序及详解
- 深入掌握WPF与C# 2010编程技术
- C#初学者百例实例程序解析
- express-mongo-sanitize中间件:防止MongoDB注入攻击
- 揭秘精品课程源码:提升教育质量的秘密武器
- 中文版SC系列OTP语音芯片特性详解
- Lombok插件0.23版发布,提高开发效率
- WebTerminal:InterSystems数据平台的全新Web终端体验
- 多功能STM32数字时钟设计:全技术栈项目资源分享
