深度学习驱动的自然语言处理:词向量与序列标注应用详解
需积分: 31 124 浏览量
更新于2024-07-18
1
收藏 4.03MB PPTX 举报
深度学习与自然语言处理是一对强大的技术组合,它们在信息技术领域扮演着关键角色。本篇文章将为你深入解析深度学习的基础知识,并探讨其在中文信息处理中的应用实例。
首先,深度学习(Deep Learning)是机器学习的一种高级形式,它模仿人脑神经网络的结构,通过多层非线性变换来提取和理解复杂数据的特征。在中文信息处理中,深度学习占到了91%,特别是在处理诸如中文分词、命名实体识别、词性标注、句法分析和篇章分析等任务上发挥着重要作用。这些任务涉及将文本分解成有意义的部分,识别特定实体(如地名、人名),确定每个词的语法角色,以及理解句子的整体结构。
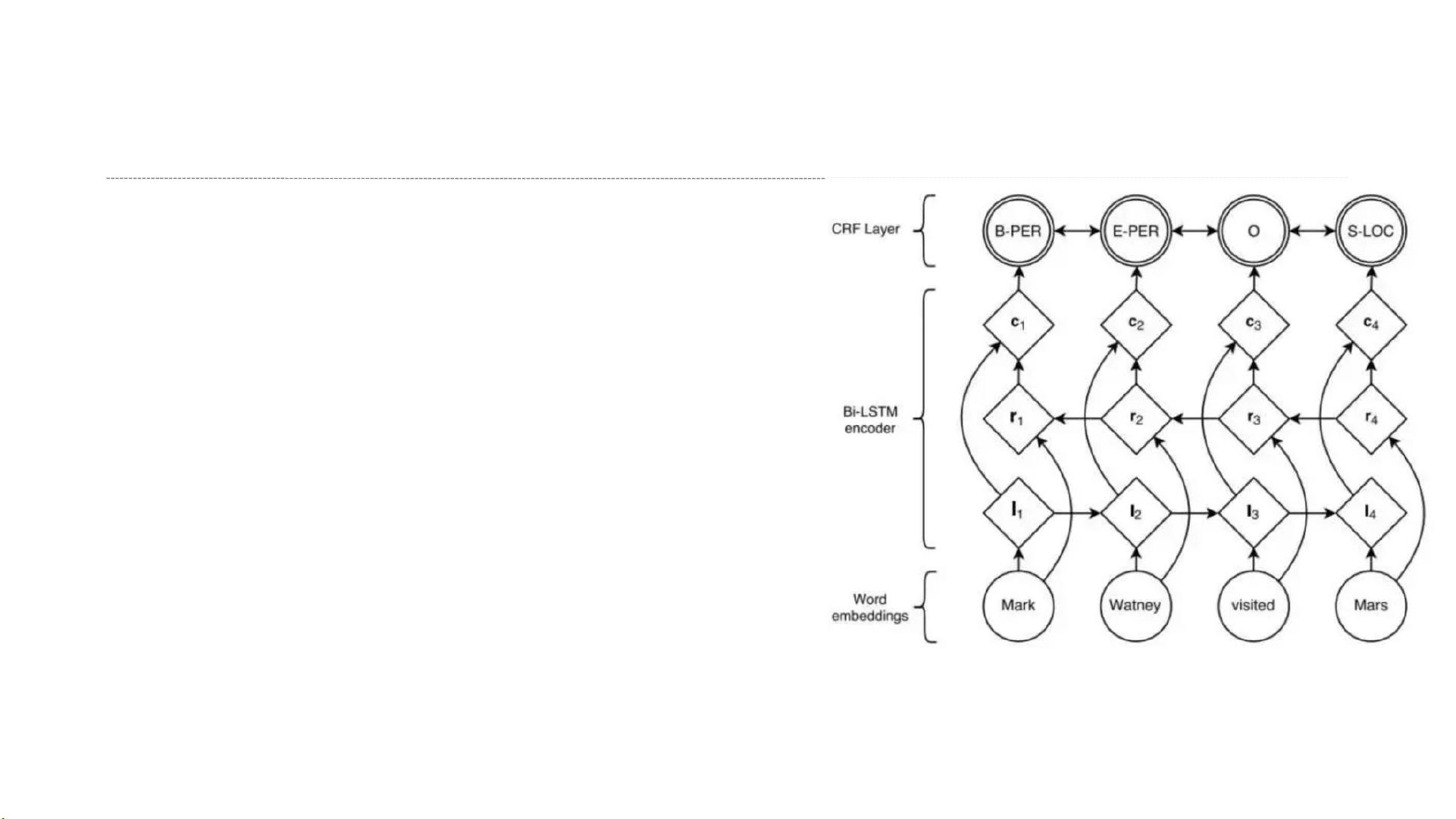
例如,中文分词是将连续的汉字序列切分成有意义的词语单位,这对于后续的信息检索和理解至关重要。深度学习方法如Bi_LSTM(双向长短期记忆网络)结合条件随机场(CRF)的序列标注技术,能够有效地捕捉词汇之间的上下文关系。
词向量(Word Embedding)是深度学习在自然语言处理中的关键技术,它将单词转换为低维实数向量,使得计算机可以理解和比较词语的语义相似性。比如,“话筒”和“麦克”虽然拼写不同,但在词向量空间中可能距离很近,这极大地推动了深度学习在自然语言处理中的应用。词向量的训练方法通常基于神经概率语言模型,随着时间的推移,研究人员不断优化算法,以提高表示的准确性。
序列标注是深度学习在自然语言处理中的一个重要应用,如命名实体识别。在“我叫张三”的例子中,深度学习模型能准确地标记出“张三”是人名(PER)。序列标注的特点是标注的序列长度与原始输入相同,如使用BI_LSTM+CRF模型,模型能够根据上下文信息预测每个字的正确标签。
深度学习的优势主要体现在两个方面:一是通过优化最终目标,自动学习原子特征和上下文的高效表示,无需人工设计复杂的特征工程;二是利用深层网络如卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)等,深度学习能够处理长距离依赖,增强对文本整体结构的理解。
深度学习与自然语言处理的结合,为中文信息处理提供了强大工具,使得机器能够更好地理解和生成人类语言,推动了智能对话系统、机器翻译等领域的进步,如Siri和小娜等。随着技术的不断发展,深度学习将继续在自然语言处理中发挥关键作用。
91%
序列标注
BI_LSTM+CRF
以最基本的向量化原子特征作为输入,经过多层非线性变
换,输出层就可以很好的预测当前字的标记。在深度学习
的框架下,仍然可以采用基于子序列标注的方式,或基于
转移的方式,以及半马尔科夫条件随机场。
深度学习主要有两点优势 :
1 )深度学习可以通过优化最终目标,有效学习原子特征和
上下文的表示;
2 )基于深层网络如 CNN 、 RNN 、 LSTM 等,深度学习
可以更有效的刻画长距离句子信息。


剩余58页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

sophie123123123
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
