Spark GraphX:图计算深度解析
76 浏览量
更新于2024-07-15
收藏 2.87MB PDF 举报
"SparkGraphX图计算"
SparkGraphX是Apache Spark的一个扩展库,它提供了对图数据处理的支持,主要用于大规模图计算。SparkGraphX不是图数据库,而是一个图计算引擎,能够处理各种复杂的图算法应用,例如倒排索引、推荐系统、最短路径计算以及社区检测等。
在图计算中,图由顶点(Vertex)和边(Edge)组成。顶点可以存储各种属性,而边则表示顶点之间的关系。图可以是有向的或无向的。有向图中,边具有方向,从一个顶点指向另一个顶点;无向图中,边没有方向,任何两个相连的顶点都可以双向连接。有环图允许存在形成闭环的边,而无环图则不允许。图还可以是有标签的或无标签的,有标签图的顶点和边可以附加额外的信息。
在SparkGraphX中,所有的图都是伪图,这意味着一个节点可以有多条边连接到另一个节点,甚至允许节点自环。图的存储基于Resilient Distributed Datasets (RDD),GraphX将图分为两个RDD,一个表示边,另一个表示顶点。用户可以通过`triplets()`接口访问图的三元组((源顶点,边,目标顶点)),这有助于进行各种图运算。
图计算的一个关键操作是`aggregateMessages`,它允许用户自定义消息传递规则。例如,`sendMsg`方法用于定义如何从源节点向目标节点发送消息,而`recvMsg`方法则定义如何在目标节点上聚合接收到的消息。`aggregateMessages`的典型应用包括计算顶点的度(入度或出度),在给定的图中计算最短路径等。
SparkGraphX还支持Pregel抽象,这是一个迭代的图并行计算模型。Pregel允许在图的各个顶点上执行计算,并通过消息传递进行同步。在这个模型中,用户定义初始状态、顶点的计算逻辑以及全局超步(Superstep)间的同步策略。
此外,图还可以用邻接矩阵来表示,邻接矩阵是一个二维数组,其中的元素表示图中顶点之间的连接情况。对于大规模图,通常使用稀疏矩阵来存储,以节省空间。
SparkGraphX提供了一个强大的框架,使得开发人员能够高效地进行分布式图计算,处理复杂的数据关系,应用于社交网络分析、推荐系统优化、网络路由等多种场景。通过灵活的消息传递机制和丰富的图运算API,SparkGraphX极大地简化了大规模图数据处理的复杂性。
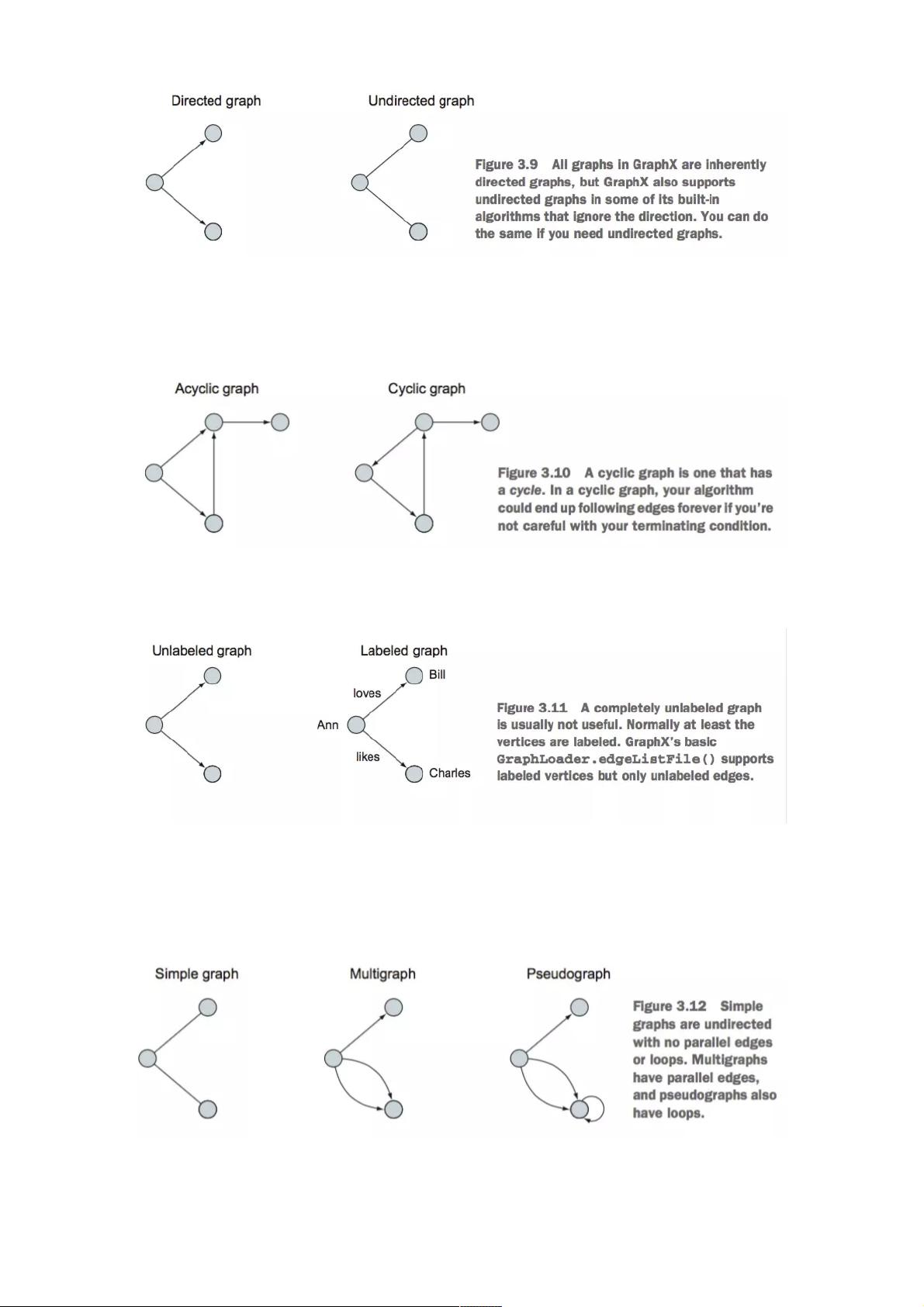
有向图与无向图
有向图无向图
有环图与无环图
两者的区别在于是否能够沿着方向构成一个闭环
有环图无环图
有标签图与无标签图
有标签无标签图
伪图与循环
从简单的图开始,当允许两个节点之间有多个边的时候,就是一个复合图,如果在某个节点上加个循环就成了伪
图,GRAPHX中的图都是伪图
伪图与循环
二部图/偶图
偶图有个特殊的结构,就是所有的顶点分为两个数据集,所有的边都是建立在这两个数据集之间的,在一个数据集中不会存在
边
剩余17页未读,继续阅读
2021-02-24 上传
点击了解资源详情
2021-01-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-09-08 上传

weixin_38709466
- 粉丝: 5
- 资源: 969
 我的内容管理
展开
我的内容管理
展开







最新资源
- MeuPrimeiroPacoteR:包装的用途(一行,标题大小写)
- command-asker.js:通过命令行与用户交互的简单方法
- DeathrunMod:AMXX插件
- ElsoKozosMunka
- tyten-game:TYTEN-TAGD Game Jam 2020年Spring
- 基于DS18B20多点测温源码-电路方案
- 戈格克隆
- calibre-web-test:口径网测试
- PEiD_1.1_2022_04_10.7z
- Arduino LEG-项目开发
- SpringCloud-Demo:springcloud演示
- 如果学生的学习时间为9.25小时,则在有监督的机器学习模型上的预测分数
- api-generator:Docpad 源解析器。 生成用于构建文档的 JSON 文件
- TaskScheduler:使用函子,lambda和std
- benthomas325
- Coding-Ninjas-java
