"打印-SP19_SAVIOR1:SAVIOR研究:基于错误驱动的混合测试方法"
需积分: 0 122 浏览量
更新于2024-01-16
收藏 1.42MB PDF 举报
打印 - SP19_SAVIOR1 是一篇关于软件测试方法的论文。该方法名为SAVIOR,是一种结合了模糊测试和共同符号执行的混合测试方法。在该方法中,模糊测试用于测试易于访问的代码区域,共同符号执行用于探索由复杂分支条件保护的代码块。通过这样的结合,SAVIOR能够更加深入地测试程序的状态空间。
在传统的软件测试中,模糊测试常用于随机生成输入并观察程序对输入的反应。然而,模糊测试仅仅测试了程序中易于访问的代码路径,无法深入到复杂的代码逻辑中。共同符号执行是一种静态和符号执行的结合体,它通过对程序进行符号执行来获得路径约束,再通过约束求解器来寻找新的输入测试用例。但共同符号执行的缺点是路径爆炸问题,即当程序的控制流图非常复杂时,共同符号执行的执行路径数量会急剧增加。
SAVIOR提出了一种将模糊测试和共同符号执行相结合的混合测试方法。在SAVIOR中,首先利用现有的模糊测试工具对程序进行模糊测试,生成一系列测试用例。然后,通过共同符号执行对这些测试用例进行深入的代码探索。共同符号执行在执行过程中会收集到程序的路径约束,这些路径约束用于对程序的状态空间进行进一步的探索。
具体来说,SAVIOR首先使用模糊测试来生成初始输入集合。然后,通过模糊测试将这些初始输入传递给共同符号执行引擎。在共同符号执行的过程中,引擎会根据路径约束和输入约束来生成新的测试用例。这些新的测试用例通过路径约束被限制在代码块的复杂分支条件中,从而能够深入探索更加复杂的代码逻辑。
SAVIOR的实验结果表明,与传统的模糊测试和共同符号执行方法相比,SAVIOR能够更好地发现程序中的漏洞和错误。在一系列测试程序上的实验中,SAVIOR相比于传统的模糊测试和共同符号执行方法,在发现漏洞和错误的数量上都有明显的提升。
总而言之,SAVIOR是一种结合了模糊测试和共同符号执行的混合测试方法。通过使用模糊测试和共同符号执行相互补充的特点,SAVIOR能够更好地探索程序的状态空间,发现更多的漏洞和错误。SAVIOR的实验结果表明,该方法在软件测试领域具有非常高的潜力和应用价值。
b1
b2
b3
b4
b5
b6
b8
b7
reachable labels: L2
solve attempts: S2
reachable labels: L1
solve attempts: S1
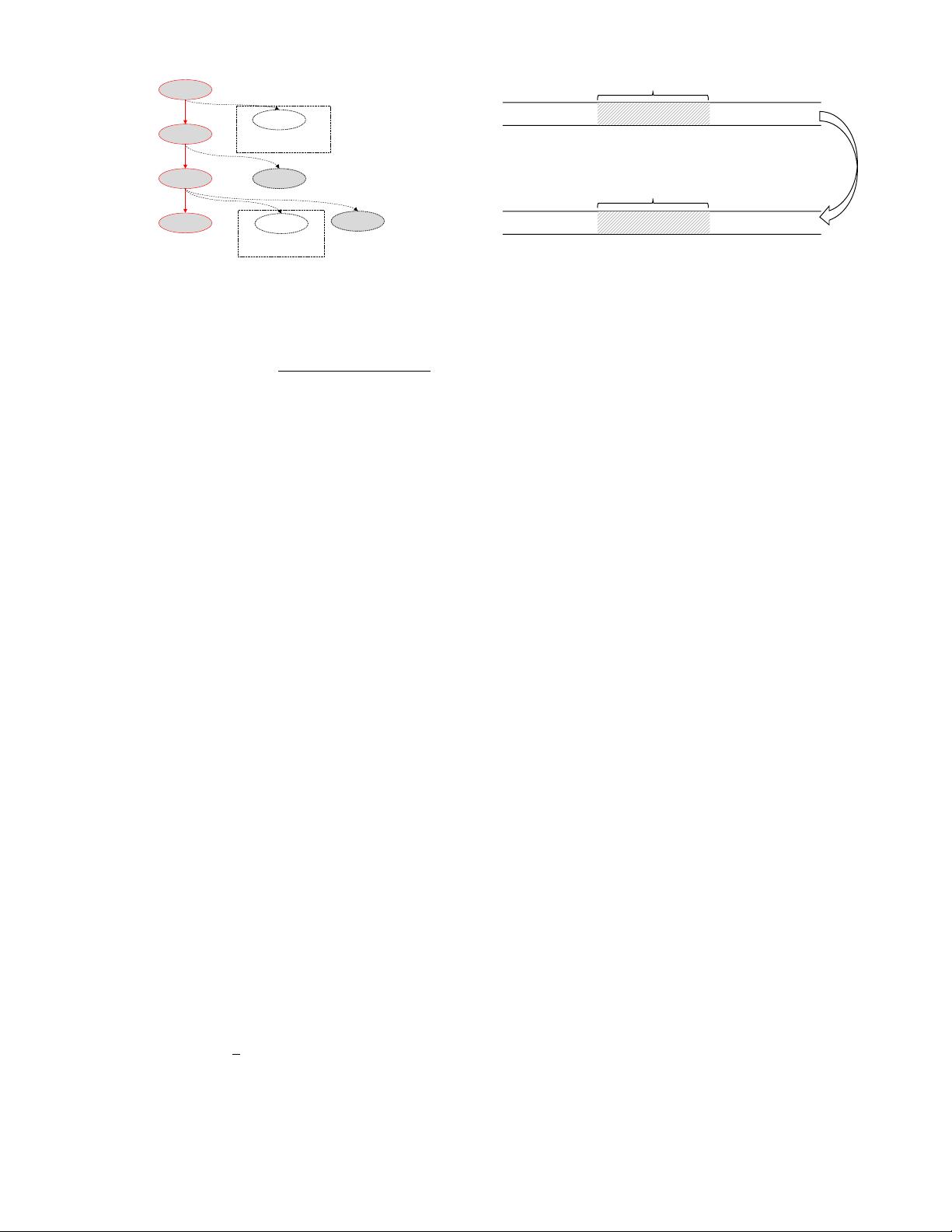
Fig. 3: An example showing how to estimate the bug-detecting
potential of a seed. In this example, the seed follows the path
b1->b2->b3->b4. Basic block b5 and b7 are unexplored
and they can reach L
1
and L
2
UBSan labels, respectively. They
have been attempted by constraint solving for S
1
and S
2
times.
The final score for this seed is
e
−0.05S
1
×L
1
+e
−0.05S
2
×L
2
2
.
metric to quantify the amount of vulnerabilities in a chunk of
code. SAVIOR fulfills them as follows.
To meet R1, SAVIOR approximates the newly explorable
code regions based on a combination of static and dynamic
analysis. During compilation, SAVIOR statically computes
the set of reachable basic blocks from each branch. At run-
time, SAVIOR identifies the unexplored branches on the
execution path of a seed and calculates the basic blocks that
are reachable from those branches. We deem that these blocks
become explorable code regions once the concolic executor
runs that seed.
To meet R2, SAVIOR utilizes UBSan [21] to annotate three
types of potential bugs (as shown in Table I) in the program
under testing. It then calculates the UBSan labels in each
code region as the quantitative metric for R2. As UBSan’s
conservative instrumentation may generate dummy labels,
SAVIOR incorporates a static filter to safely remove useless
labels. We discuss the details of this method in Section III-B1.
The above two solutions together ensure a sound analysis
for identifying potential bugs. First, our static reachability
analysis, as described in Section III-B1, is built upon a
sound algorithm. It over-approximates all the code regions that
may be reached from a branch. Moreover, UBSan adopts a
conservative design, which counts all the operations that may
lead to the undefined behavior issues listed in Table I [21, 35].
Facilitated by the two aspects of soundness, we can avoid
mistakenly underrating the bug-detecting potential of a seed.
Following the two solutions, SAVIOR computes the impor-
tance score for each seed as follows. Given a seed with n unex-
plored branches {e
1
, e
2
, . . . , e
n
}, SAVIOR calculates the UB-
San labels in the code that are reachable from these branches,
respectively denoted as {L
1
, L
2
, . . . , L
n
}. Also note that, in
the course of testing, SAVIOR has made {S
1
, S
2
, . . . , S
n
}
attempts to solve those branches. With these pieces of infor-
mation, SAVIOR evaluates the importance score of this seed
with a weighted average
1
n
×
P
n
i=1
e
−0.05S
i
×L
i
. L
i
represents
the potential of the i
th
unexplored branch. We penalize L
i
with
e
−0.05S
i
to monotonically decrease its weight as the attempts
to solve this branch grow. The rationale is that more failed
\xfb\xfb\xf4\xf1
\xxx\xxx\xxx\xxx
\xfb\xf4\xf1\xf1
section->size
Overflow Condition:
section->size + 1 < section->size
\xfb\xfb\xf4\xf1
\xff \xff \xff \xff
\xfb\xf4\xf1\xf1
section->size
solve
section->size+1 > 0xffffffff
Fig. 4: Solving the integer overflow in Figure 2. This shows
the case in a 32-bit system, but it applies to 64-bit as well.
attempts (usually from multiple paths) indicate a low success
possibility on resolving the branch. Hence, we decrease its
potential so that SAVIOR can gradually de-prioritize hard-
to-solve branches. Lastly, SAVIOR takes the average score
of each candidate branches in order to maximize the bug
detection gain per unit of time. To better understand this
scoring method, we show an example and explain the score
calculation in Figure 3.
This scoring method is to ensure that SAVIOR always
prioritizes seeds leading to more unverified bugs, while in
the long run it would not trap into those with hard-to-solve
branch conditions. First, it conservatively assesses a given
seed by the results of sound reachability and bug labeling
analysis. A seed which leads to more unexplored branches
where more unverified bugs can be reached from will earn a
higher score. Second, it takes into account runtime information
to continuously improve the precision of the assessment. This
online refinement is important because statically SAVIOR
may hardly know whether a branch condition is satisfiable
or not. Utilizing the history of constraint solving attempts,
SAVIOR can decide whether a seemingly high-score branch
is worth more resources in the future. As shown by our evalua-
tion in Section V, this scoring scheme significantly accelerates
the detection of UBSan violations, which empirically supports
the effectiveness of our design.
Referring to our motivating example in Figure 1, the
function packet_handler1 has few UBSan labels while
pcap_handler2 contains hundreds of labels. Hence, the
seed following Figure 1b has a lower score compared to the
other seed which runs the path in Figure 1c. This guides
SAVIOR to prioritize the latter seed, which can significantly
expedite the exploration of vulnerable code.
Bug-guided verification: This technique also ensures a sound
vulnerability detection on the explored paths that reach the
vulnerable sites. Given a seed from fuzz testing, SAVIOR
executes it and extracts the label of each vulnerability along
the execution path. After that, SAVIOR verifies the predicates
implanted in each label by checking the satisfiability under the
current path condition — if the predicate is satisfiable then its
corresponding vulnerability is valid. This enables SAVIOR
to generate a proof of either vulnerability or non-existence
along a specific program path. Note that in concolic execution,
many new states with new branch constraints will be created.
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-10-16 上传
2021-06-16 上传
2021-05-01 上传
2021-04-02 上传

独角兽邹教授
- 粉丝: 39
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
