Python网络爬虫基础:URL管理器与网页解析
版权申诉
"Python网络爬虫实例讲解,涵盖了爬虫定义、主要框架、URL管理器、网页下载器和网页解析器等内容。"
Python网络爬虫是一种自动化程序,它能遍历互联网并抓取所需的数据。在Python中实现网络爬虫涉及多个关键组件,包括URL管理器、网页下载器和网页解析器。
首先,URL管理器是爬虫系统的核心部分,它负责跟踪已访问和待访问的URL。这个功能通常通过Python的set数据结构或者关系数据库(如MySQL)来实现,以确保没有重复抓取同一页面,并避免循环抓取问题。set数据结构在内存中高效地处理唯一元素,而数据库则适合存储大量URL,尤其是在大型爬虫项目中。
其次,网页下载器是爬虫用来获取网页内容的工具。在Python中,标准库urllib提供了这一功能。urlopen函数可以打开URL并返回响应数据。对于复杂请求,如处理HTTP头、登录状态或处理cookies,可能需要更精细的控制,这可以通过urllib的request子模块或其他第三方库如requests来实现。
接下来,网页解析器从下载的HTML或XML文档中提取所需信息。Python的BeautifulSoup库常被用来解析网页内容,它将原始HTML转化为易于操作的DOM树结构,便于查找和提取数据。正则表达式也是常用的辅助工具,虽然在特定场景下强大,但其灵活性较低,不适合复杂的数据结构。
以下是一个使用BeautifulSoup进行网页解析的简单示例,它抓取了百度百科中“英雄联盟”词条相关的其他词条,并将其保存到Excel文件中:
```python
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_links(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 假设链接存在于类名为'wiki_link'的a标签内
links = [a['href'] for a in soup.find_all('a', class_='wiki_link')]
return links
# 主要链接,比如:'https://www.baidu.com/baike/lol'
base_url = 'https://www.baidu.com/baike/lol'
related_links = get_links(base_url)
# 将链接保存到Excel
df = pd.DataFrame(related_links, columns=['Links'])
df.to_excel('related_links.xlsx', index=False)
```
这段代码首先使用requests库发送GET请求获取页面,然后BeautifulSoup解析响应的HTML内容,寻找所有类名为'wiki_link'的a标签,提取它们的href属性,即相关词条的链接。最后,将这些链接保存到一个DataFrame并导出为Excel文件。
了解这些基本概念后,你可以开始构建自己的Python网络爬虫,从网页中提取新闻、产品信息、用户评论等各种数据,为数据分析、信息提取或自动化任务提供基础。记住,使用爬虫时需遵守网站的robots.txt规则,尊重网站的版权和隐私政策,合法合规地获取网络数据。
Python网络爬虫实例讲解网络爬虫实例讲解
聊一聊Python与网络爬虫。
1、爬虫的定义、爬虫的定义
爬虫:自动抓取互联网数据的程序。
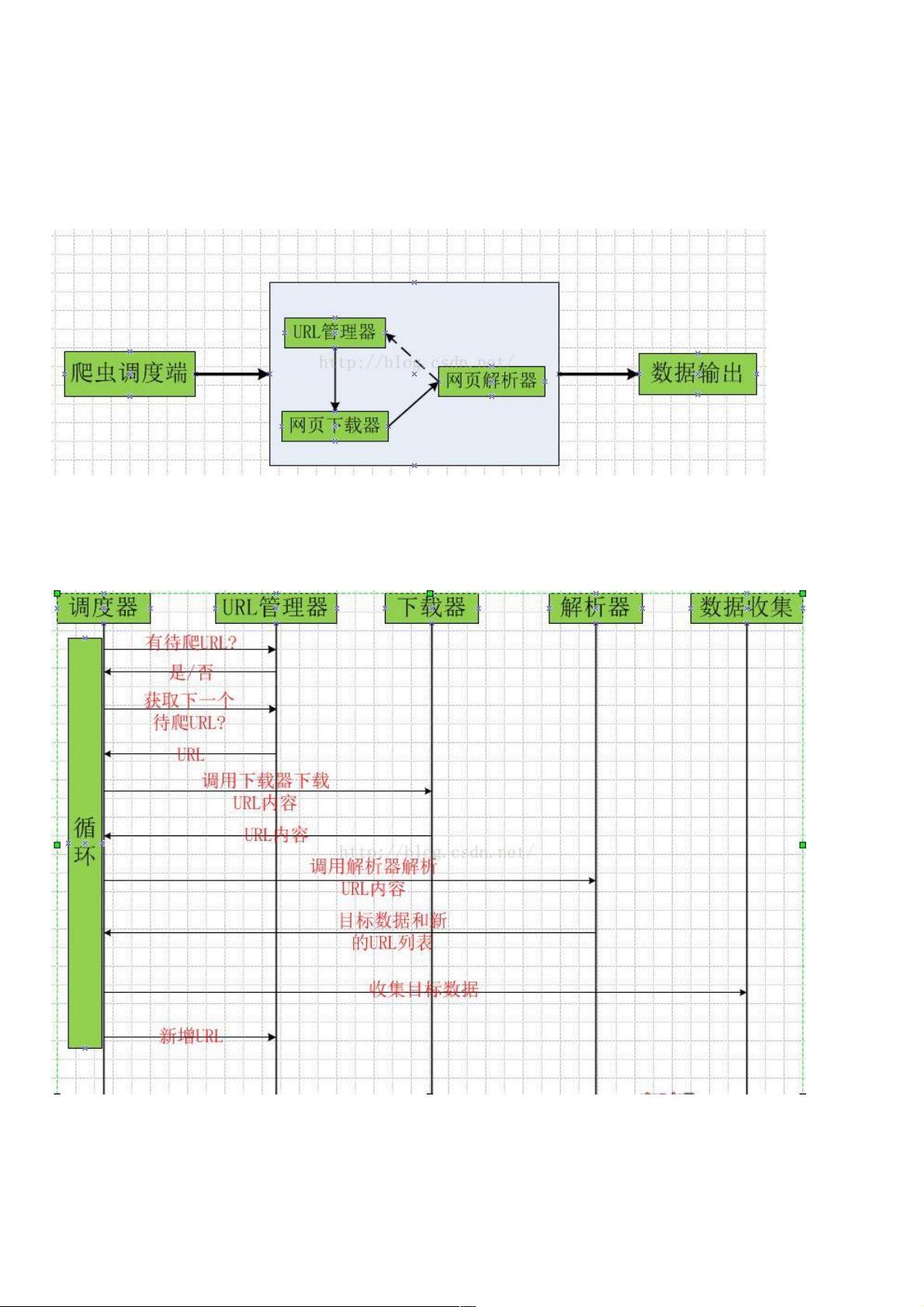
2、爬虫的主要框架、爬虫的主要框架
爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链
接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器
中,将有价值的数据输出。
3、爬虫的时序图、爬虫的时序图
4、、URL管理器管理器
URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取。URL管理器的主要职能如下图所示:
下载后可阅读完整内容,剩余3页未读,立即下载
175 浏览量
159 浏览量
2023-02-22 上传
2024-02-04 上传
2020-12-24 上传
2021-01-21 上传
2020-09-20 上传
2020-12-24 上传
2021-01-21 上传

weixin_38597300
- 粉丝: 6
- 资源: 982
 我的内容管理
展开
我的内容管理
展开







最新资源
- flex迅速入门教程
- Struts标签详解(中文).doc
- 学习3D模型-Focus.On.3D.Models
- 字符编码-使用c#研究
- 配置vista驱动开发环境
- 向量在游戏中的应用——Vector.Game.Math.Processors
- c#中如何调用外部DLL
- Hibernate学习笔记.pdf
- 计算机网络课程设计 任务书
- MapXtreme2005官方中文版开发指南.pdf
- 微软C编程精粹-微软C编程精粹
- DXP简介及使用技巧
- 土豆网前端概况.doc
- 关于获得MFC窗口其它类指针的方法.pdf
- SMC无线硬盘盒 Dreambox DM500 定時錄製卫星節目
- laji表单的验证js_Validator.chm
