领域本体驱动的Web表格信息抽取提升准确性
需积分: 9 162 浏览量
更新于2024-08-26
收藏 1.13MB PDF 举报
本篇文章探讨了"基于本体的Web表格信息抽取技术的研究"这一主题,发表于2010年的《青岛大学学报(自然科学版)》第二十三卷第二期。作者袁鸿雁来自沈阳职业技术学院计算机系,研究的核心是将本体理论与Web信息抽取技术紧密结合,特别关注特定领域的信息处理。
在当前互联网环境中,大约52%的网页包含表格,这使得从Web表格中有效地提取信息成为一个挑战。传统的HTML标记仅关注数据展示,而非数据的语义描述,导致理解表格结构的复杂性增加。BUY研究小组将表格信息抽取过程细分为表格理解、数据整合和信息抽取三个步骤,强调了理解表格结构在这一过程中的关键作用。
H. Chen等人提出了表格定位、结构识别和"属性-值"对提取的框架,虽然算法相对简单,但缺乏实验验证。Tengli等人的工作则引入了自动抽取系统,通过样本表格学习属性词汇信息,并运用模糊匹配技术来定位属性单元格。然而,这种方式对领域知识的依赖度较高。
王放等人提出了基于本体的Web表格信息抽取方法,借助本体的学习和积累,为表格结构识别提供了更精准的指导。文章创新地采用了领域本体,这种方法能够在元素级别和实例级别上进行模式匹配,减少了对网页结构的依赖。这种方法的优势在于其高度定制化,只要预先构建的领域本体足够强大,就能够对相应领域的表格文本进行高效的信息抽取。
值得注意的是,作者强调了限定领域的重要性,这意味着通过专注于特定领域,可以显著提高信息抽取的准确性和效率。这种方法不仅能够解决Web表格理解的难题,而且对于大规模、多样化的Web信息抽取任务具有广泛的应用前景。这篇文章深入研究了如何通过本体理论优化Web表格信息抽取的技术,为该领域的研究和发展提供了新的视角和方法。
第23卷 第 2 期
2 0 1 0 年 6 月
青 岛 大 学 学 报 (自 然 科 学 版 )
JOURNAL OF QINGDAO UNIVERSITY (Natural Science Edition)
Vol .23 No .2
Jun .2 0 1 0
文章编号 :1006 1037(2010)02 0047 05
doi :10 .3969/
j
.issn .1006 1037 .2010 .02 .012
基 于 本 体 的 Web 表 格 信 息 抽 取 技 术 的 研 究
磁
袁鸿雁
(沈阳职业技术学院计算机系 ,沈阳 110045)
摘要 :将本体与和 Web 信息抽取技术相结合 ,将信息抽取的重点放在特定的领域 ,利用
表格属性定位 、识别表格结构生成启发式规则 ,可以大大提高信息抽取的准确率 。
关键词 :Web 表格 ;本体 ;表格定位 ;表格结构识别
中图分类号 :TP391 .13 文献标志码 :A
据统计 ,互联网上约有 52% 的 Web 页面包含表格
[1]
。 Web 表格主要基于 HTML ,由于 HTM L 只描述
数据怎样显示而缺乏对数据本身的描述 ,再加上 Web 表格表现形式的复杂多样性 ,因此理解 Web 表格结构
从中抽取出有效的信息就变得非常的困难 ,从 Web 表格中抽取信息也就成为 Web 信息抽取领域重要且有
价值的研究课题之一 。 BUY 研究小组将表格的信息抽取划分为表格理解 、数据整合 、信息抽取三个部分
[2]
。
通过理解表格结构 ,可以识别表格里的属性和取值 。 H .Chen 等
[3]
首次提出 Web 表格分析的过程分为表格
定位 、表格结构识别和“属性–值”对的提取 ,该文提出的算法相对较简单 ,但未给出实验结果 。 Tengli 等
[4]
提出了一个 Web 表格信息自动抽取系统的构造方法 。 在表格结构识别中 ,该系统通过样本表格学习属性的
词汇信息 ,然后通过向量空间模型对待抽取表格的单元格进行模糊匹配 ,从而识别属性单元格所在位置 ,达
到定位属性和值的目的 。 这种方式的表格结构识别对领域知识依赖过强 。 王放等
[5]
提出了一种基于本体的
Web 表格信息抽取技术 ,该方法通过对本体的学习和积累 ,对表格的结构识别提供指导 。 本文提出了一种
新的基于领域本体
[6]
的 Web 表格信息抽取方法 。 该方法可实现元素级别和实例级别的模式匹配并且对网
页结构依赖很少 ,只要事先创建的应用领域 ontology 足够强大 ,系统就可以对该应用领域中的表格文本实
现信息抽取 ,其中限定领域的思想提高了数据抽取的准确率 。
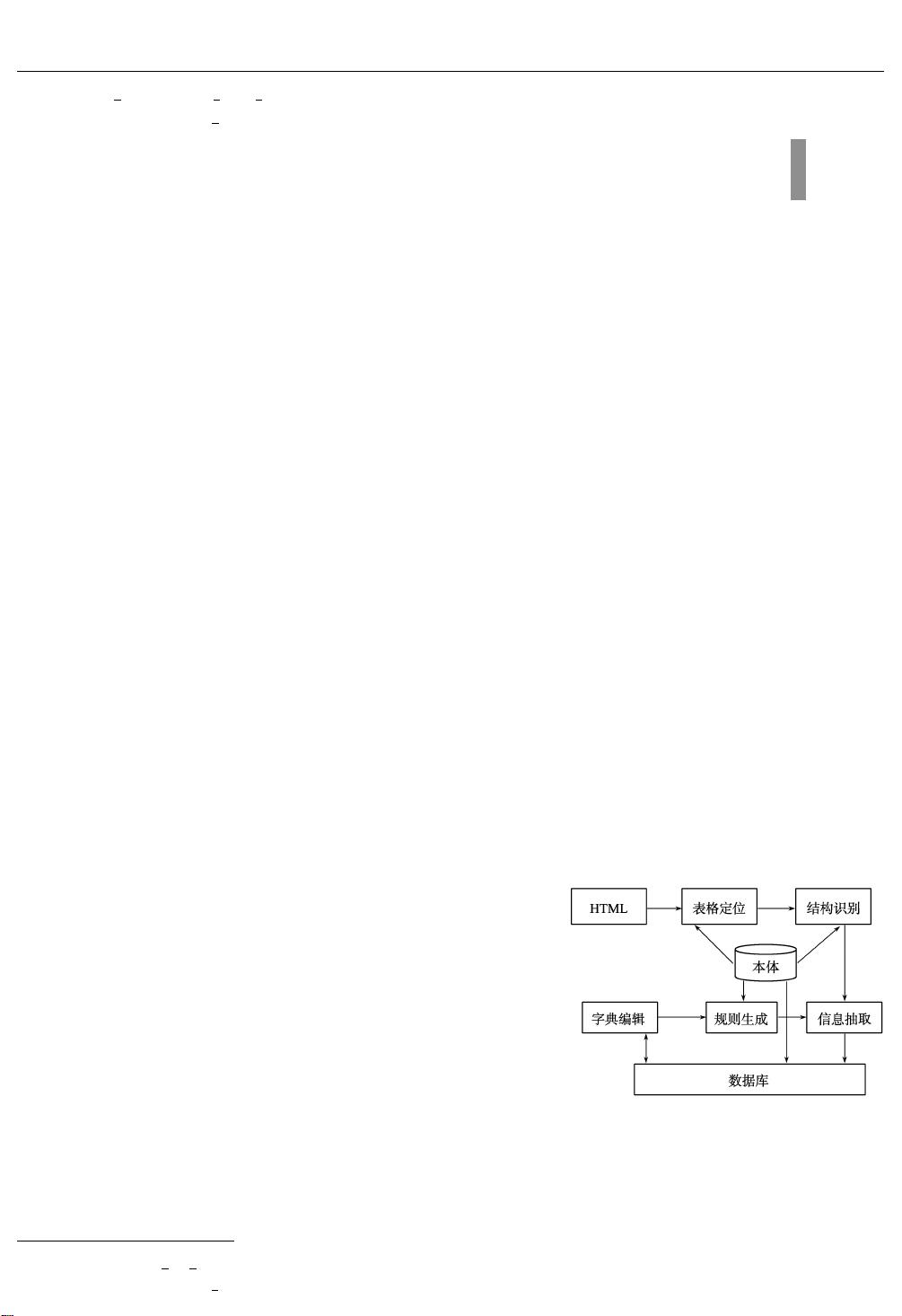
1 Web 表格信息抽取系统结构
系统结构如图 1 所示 。 本系统对 Web 表格数据抽取工作分为
图 1 系统总体结构图
3 步进行 :表格定位 、表格结构识别 、表格信息抽取 。 其工作过程为 :
待处理的包含表格的 HTML 文档首先进入表格定位模块 ,在此模
块中滤除非数据表格和非用户感兴趣的数据表格等额外的信息 ,识
别出满足要求的数据表格 ,然后进入表格结构识别模块 ,在该模块
中识别出表格的展开方式和表格属性行(列) 、数据单元格所在的位
置 ,最后按照抽取规则完成表格的属性与本体中概念的映射 ,抽取
出所需要的数据 ,存入数据库中 。 由于 HT ML 文档的获取以及本
体的建立不是本文研究的内容 ,因此在本文中未涉及 。
磁
收稿日期 :2009 10 03
作者简介 :袁鸿雁 (1973 ) ,女 ,硕士 ,讲师 ,主要从事数据库系统及数据挖掘技术的研究 。
下载后可阅读完整内容,剩余4页未读,立即下载
2011-06-27 上传
2011-09-29 上传
2021-05-21 上传
2020-07-06 上传
2021-05-22 上传
2021-05-27 上传
2022-04-09 上传
2021-05-18 上传
2020-07-04 上传

weixin_38743372
- 粉丝: 5
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
