多模态COVID-19检测:深度学习方法实现97.8%精度
83 浏览量
更新于2024-06-18
收藏 3.03MB PDF 举报
随着COVID-19疫情的全球肆虐及其不断变异带来的挑战,准确、快速的病例识别成为公共卫生的关键需求。本文研究探讨了利用智能系统和机器学习技术对COVID-19病例进行多模态图像分类的方法。研究者们结合了胸部X线和CT扫描图像,以及相关的临床记录,构建了一个双模式检测系统。
该研究采用数据扩充技术来扩大数据集的范围,通过增加样本多样性来提高模型的泛化能力。他们运用了迁移学习策略,结合了Adam优化器和二进制交叉熵损失函数,这两种技术对于提升模型性能和稳定训练过程至关重要。研究团队尝试了五种不同类型的图像和文本模型,包括VGG16、ResNet50、InceptionResNetV2、和MobileNetV2等预训练模型,这些模型在医疗图像识别领域有着广泛的应用。
通过实验,最终的多模态方法实现了高达97.8%的测试准确性,证明了这种方法在识别COVID-19病例方面的有效性。值得注意的是,这种方法仅依赖于扫描图像和相关的临床注解,减少了依赖实验室测试的时间成本,并且可能在资源有限的地区提供更便捷的筛查手段。
整个研究分为两个主要部分:首先,介绍了COVID-19的起源和传播方式,强调了快速检测的重要性;其次,详细阐述了研究方法和所取得的成果,突出了多模态技术在医疗领域的潜力和实际应用价值。这一研究为COVID-19的早期诊断和管理提供了创新思路,同时也展示了人工智能在公共卫生应急响应中的积极作用。
N. Nasir
等人
智能系统与应用
17
(
2023
)
200160
3
×
×
(
)
下
一
页
()=()+
()=
()
(
)
()=
()+
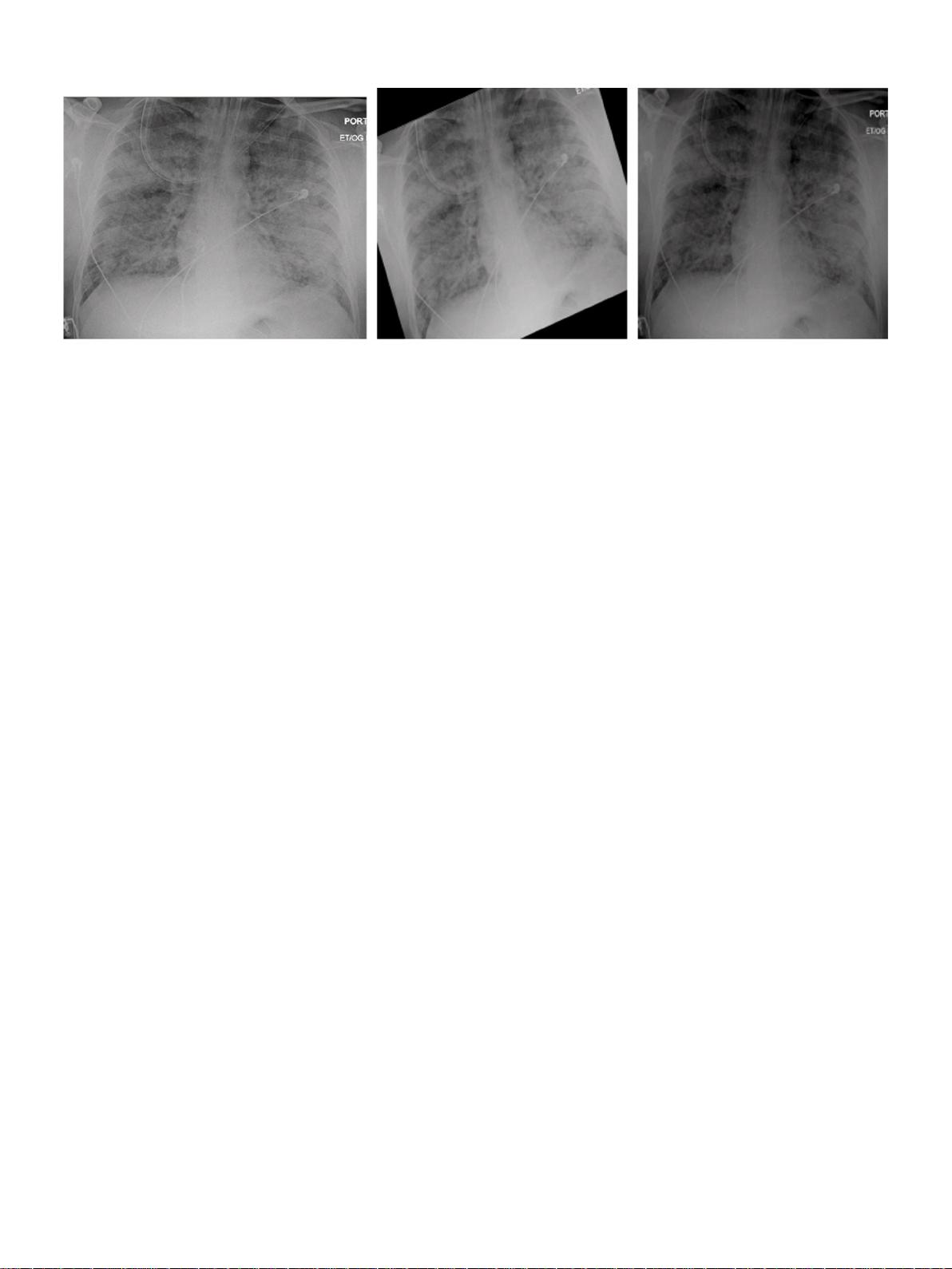
图1.一、
图像增强:
左:原始,中:旋转,右:亮度降低
。
swapped被选择为15,并且结果文本是增强文本。对于图像,也有两
种类型的增强-旋转和降低亮度。由于处理医学图像,图像的反转是
不可能的。增强图像旋转20度角。数据扩充完成两次,一次在整个
数据集上,一次仅在训练数据集上。增强图像的示例在图1中示出。
3.1.2.
文本分析
通过绘制单词云和前20个一元语法、二元语法和三元语法来分析临
床笔记。词云是一种可视化表示,通常用于可视化文本数据。它将文本
分解为单词,并以不同的大小和颜色绘制单词,以表示其在数据中的频
率。在词云中尺寸大得多的词被认为是数据中最频繁出现的词,而较小
尺寸的词则不太频繁。Uni-grams指的是单独的单词。二元语法指的是
成对的词在一起,而三元语法指的是三个词在一起的组。所有可能的这
种组合采取和最频繁出现的词组,然后绘制。
3.2.
k
倍交叉验证
测试了三种不同的情况以获得最佳结果-没有数据增强时,仅对训练
数据进行数据增强以及对整个数据进行数据增强。在这三个模型中,选
择最好的模型,然后进行K折交叉验证以测试结果的有效性,因为数据
很小并且数据分割是随机进行的。因此,K被选为10。对于10次迭代中
的每一次,运行模型,保持一个折叠作为测试,其余作为训练数据。在
运行模型时,验证数据大小选择为训练数据的30%。
3.3.
模型架构
Keras核心库中包含的最先进的预训练网络在ImageNet挑战中始终优
于卷积神经网络。这些网络还显示出使用迁移学习技术(如特征提取和
微调)泛化到ImageNet数据集之外的图像的强大能力。 下面讨论四种
使用的CNN架构
3.3.1.
VGG16
模型
VGG16最与众不同的方面是它专注于使用步长为1的3 × 3滤波器的卷
积层,而不是一堆超参数,并且始终使用相同的填充和步长为2的2 × 2
滤波器的maxpool层。卷积和最大池层是
以这种方式贯穿整个建筑。两个完全连接的层和一个softmax作为其最终
特征被包括在内。VGG16中的16代表加权层数,即16。这个网络有大约
1.38亿个参数,使其相当庞大(Simonyan Zisserman,2014&)。
3.3.2.
ResNet50
模型
ResNet或残差网络(由残差块组成)的引入缓解了不同之处在
于,有一个直接连接,跳过了中间的一些层(这可能会因型号而
异)。这种连接被称为由于这种跳过连接,层在没有这种跳过连接的
情况下,输入这一项然后通过激活函数
f
,结果是
H x f x
。添加跳过连
接后,输出现在为
H x f x x
。当输入的维度与输出的维度不同时,这
种方法似乎有一个小缺陷,这可能发生在卷积层和池化层中。当
f x
的
维数不同于
x
的维数时,可以采取两种方法之一:用额外的零条目填
充跳过连接以增加其维数。为了匹配维度,使用投影方法,这是通过
向输入添加11个卷积层来实现的。在这种情况下,结果是
H x f
x w
1。
X
.在这种情况下,我们添加了一个额外的参数w1,而
在第一种方法中,没有添加额外的参数。ResNet中的跳跃连接通过
允许梯度流动来解决深度神经网络中
通过另一条捷径。另一种方式,这些连接
帮助是通过允许模型学习恒等函数,这确保了高层的性能至少与低层
一样好,如果不是更好的话(He,Zhang,Ren,Sun,2016
&
)。
3.3.3.
MobileNetV2
模型
在MobileNetV2中,有两种不同类型的块。一个步长为1的残差块和
另一个步长为2的残差块用于缩小尺寸。这两种块都有一个11卷积,
ReLU6层作为它们的第一层。一个深度卷积构成第二层,另外11个没有
非线性的卷积构成第三层。如果再次应用ReLU,深度网络只在输出域的
非零体积部分上具有线性分类器 的能力(Sandler,Howard,Zhu,
Zhmoginov,Chen,2018&)。
3.3.4.
InceptionResNetV2
模型
Inception-ResNet-v2卷积神经网络是在ImageNet数据库中的100多万
张图像上训练的。使用164层,图像可以被分类为1000个不同的对象类
别。
剩余14页未读,继续阅读
2023-02-09 上传
2021-04-24 上传
2024-02-29 上传
2024-10-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-25 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
