Spark 1.6后内存优化:UnifiedMemoryManager详解
111 浏览量
更新于2024-08-27
收藏 243KB PDF 举报
Spark的内存管理是其性能优化的关键组成部分,特别是在大数据处理和分布式计算中。早期的Spark(版本1.5之前)使用StaticMemoryManager进行内存划分,主要将内存分为Execution内存(用于执行计算任务的临时数据)和Storage内存(用于存储中间结果和数据传输)。StaticMemoryManager的主要特点是通过静态边界来区分这两种内存,这简化了实现,但存在以下问题:
1. 缺乏通用性:默认设置可能无法适配各种工作负载,对于不同的计算场景,用户可能需要手动调整内存分配,这增加了内存调优的复杂性和难度。
2. 内存利用不充分:对于那些不需要大规模缓存的应用,Execution内存可能被闲置,而Storage内存则可能不足以支持数据传输和计算需求。
为了提升Spark的灵活性和易用性,从Spark 1.6版本开始引入了UnifiedMemoryManager(统一内存管理)模型。这个模型的核心组件包括StorageMemoryPool和ExecutionMemoryPool,它们作为动态内存池,允许在两者之间动态调整软边界,使得内存分配更为智能和高效。
UnifiedMemoryManager的内存布局设计更加精细,它在Executor JVM内存中继续划分Storage内存和Execution内存,但通过引入Softboundary的概念,内存在需求不足时可以跨区域共享。这样做的好处在于:
- 提高资源利用率:即使某个内存区域紧张,其他区域的空闲内存可以被自动调整到需要的地方,避免了资源的浪费。
- 降低调优压力:统一内存管理减少了用户对Spark内部机制的深入了解要求,使得内存管理变得更加直观和易于管理。
- 避免OOM问题:通过动态调整,可以更好地防止由于内存溢出(OOM)导致的任务失败。
UnifiedMemoryManager是对StaticMemoryManager的一个重大改进,它通过引入动态内存池和软边界概念,增强了Spark内存管理的灵活性和适应性,使得开发者能够更专注于业务逻辑,而不必过多关注底层内存配置,从而提升了Spark的整体性能和可靠性。
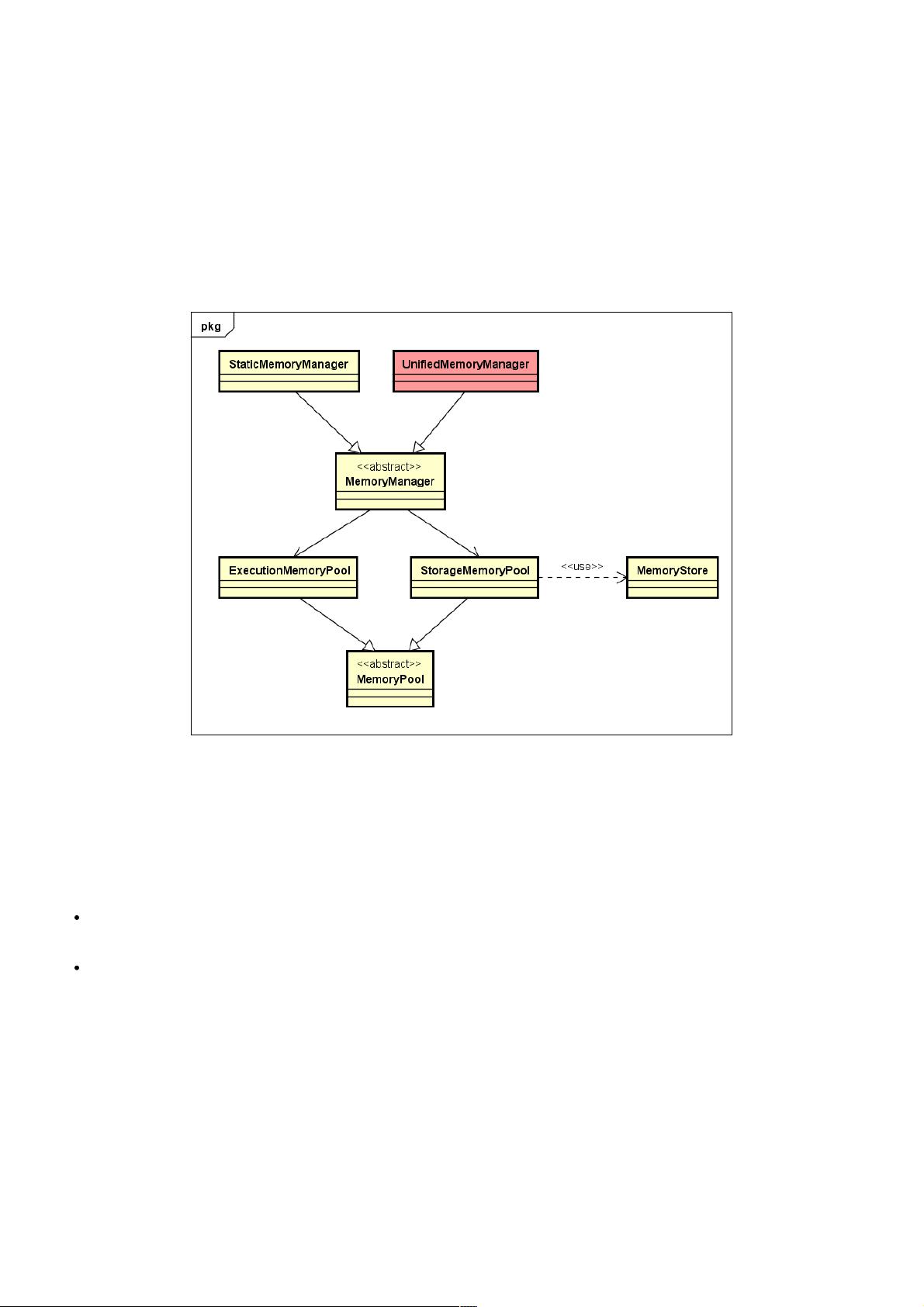
SparkUnifiedMemoryManager内存管理模型分析内存管理模型分析
Spark的内存使用,大体上可以分为两类:Execution内存和Storage内存。在Spark 1.5版本之前,内存管理使用的是
StaticMemoryManager,该内存管理模型最大的特点就是,可以为Execution内存区与Storage内存区配置一个静态的
boundary,这种方式实现起来比较简单,但是存在一些问题:
1. 没有一个合理的默认值能够适应不同计算场景下的Workload
2. 内存调优困难,需要对Spark内部原理非常熟悉才能做好
3. 对不需要Cache的Application的计算场景,只能使用很少一部分内存
为了克服上述提到的问题,尽量提高Spark计算的通用性,降低内存调优难度,减少OOM导致的失败问题,从Spark 1.6版本
开始,新增了UnifiedMemoryManager(统一内存管理)内存管理模型的实现。UnifiedMemoryManager依赖的一些组件类及
其关系,如下类图所示:
从上图可以看出,最直接最核心的就是StorageMemoryPool 和ExecutionMemoryPool,它们实现了动态内存池(Memory
Pool)的功能,能够动态调整Storage内存区与Execution内存区之间的Soft boundary,使内存管理更加灵活。下面我们从内
存布局和内存控制两个方面,来分析UnifiedMemoryManager内存管理模型。
内存布局
UnifiedMemoryManager是MemoryManager的一种实现,是基于StaticMemoryManager的改进。这种模型也是将某个执行
Task的Executor JVM内存划分为两类内存区域:
Storage内存区
Storage内存,用来缓存Task数据、在Spark集群中传输(Propagation)内部数据。
Execution内存区
Execution内存,用于满足Shuffle、Join、Sort、Aggregation计算过程中对内存的需求。
这种新的内存管理模型,在Storage内存区与Execution内存区之间抽象出一个Soft boundary,能够满足当某一个内存区中内
存用量不足的时候,可以从另一个内存区中借用。我们可以理解为,上面Storage内存和Execution堆内存是受Spark管理的,
而且每一个内存区是可以动态伸缩的。这样的好处是,当某一个内存区内存使用量达到初始分配值,如果不能够动态伸缩,不
能在两类内存区之间进行动态调整(Borrow),或者如果某个Task计算的数据量很大超过限制,就会出现OOM异常导致Task
执行失败。应该说,在一定程度上,UnifiedMemoryManager内存管理模型降低了发生OOM的概率。
我们知道,在Spark Application提交以后,最终会在Worker上启动独立的Executor JVM,Task就运行在Executor里面。在一
个Executor JVM内部,基于UnifiedMemoryManager这种内存管理模型,堆内存的布局如下图所示:
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
2024-11-01 上传
2024-11-01 上传

weixin_38731226
- 粉丝: 5
- 资源: 926
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
