PostgreSQL多维存储与SQL流计算实战:噪声过滤与优化
需积分: 9 178 浏览量
更新于2024-07-18
收藏 985KB PDF 举报
"本文主要探讨了PostgreSQL在处理大数据时如何进行多维存储和SQL流计算,重点关注数据噪音、隐式噪音以及相应的解决方案,包括多维聚集和空间切割技术。内容涉及一维、二维和多维聚集的概念,以及BRIN索引在减少隐式噪音中的应用。"
在大数据分析中,数据噪音是一个重要的问题,它指的是那些对分析目标无用或者干扰性的数据。在PostgreSQL中,数据噪音可能源于多种因素,如非必要的索引访问和分区策略。隐式噪音尤其棘手,因为它可能导致IO放大和CPU资源的浪费。
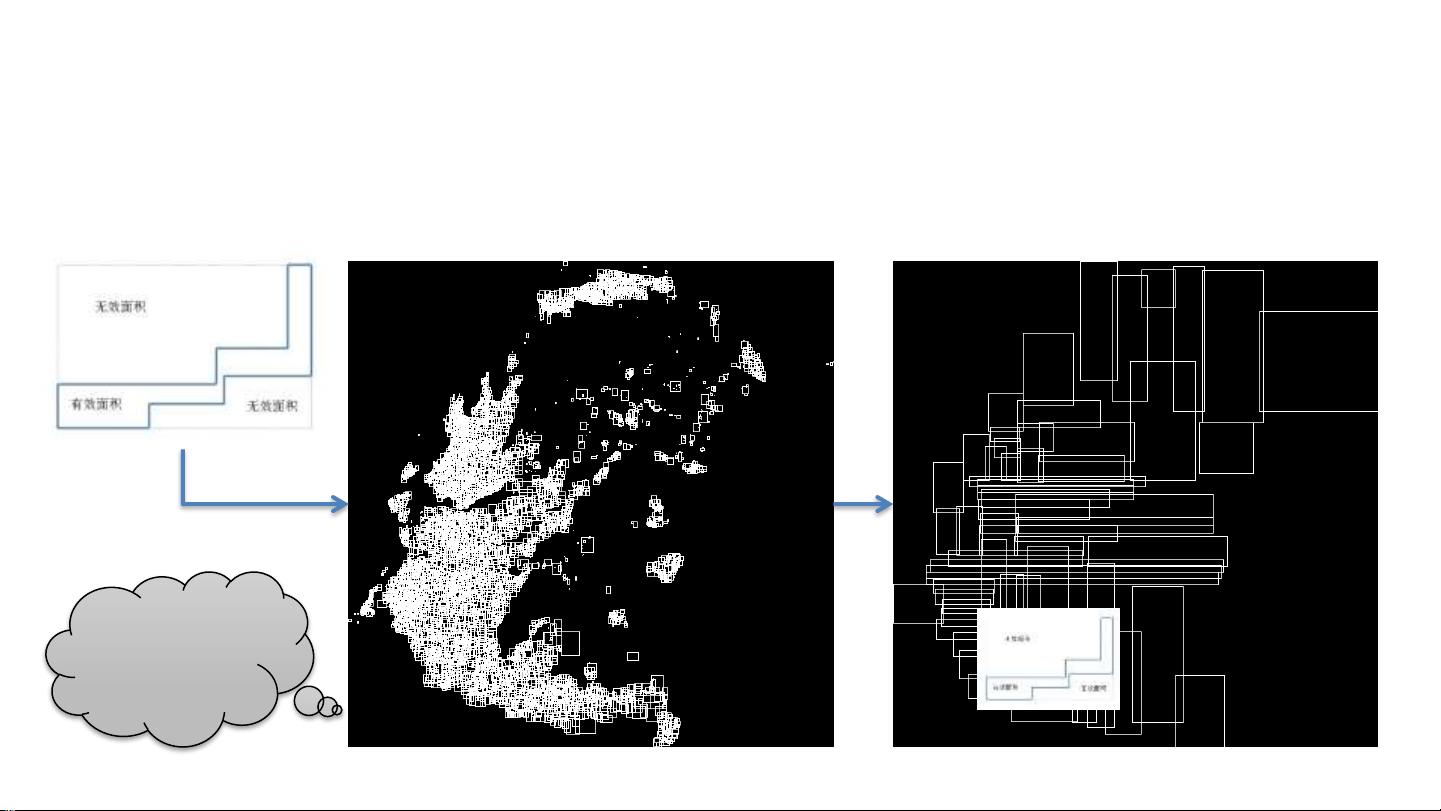
隐式噪音的一个典型例子是IO放大,当查询只返回少量有效数据,但需要读取大量存储数据时,就会发生这种情况。例如,一个简单的索引访问可能在HEAP Storage中导致IO放大,因为索引虽然帮助定位到数据,但仍然需要读取所有相关行。此外,如果索引本身也参与计算,那么IO放大可能会结合CPU资源的消耗,形成隐式噪音的CPU+IO放大。
为了解决隐式噪音,PostgreSQL提供了两种主要方法:聚集和空间切割。聚集是一种将数据按照特定维度(如一维、二维或更多维)排序的方法,以减少无效数据的处理。一维聚集通过ORDER BY操作实现,如WHERE col1 = xxx ORDER BY col1,这可以创建一个有序列,便于快速查找。二维聚集则需要同时考虑两个维度,如WHERE a = xxx AND/OR b = xxx,通过row_number()函数进行排序,适用于需要在两个维度上查找的数据。三维及更多维度的聚集与此类似,通过更多的row_number()函数应用来处理。
空间切割是另一种优化策略,它涉及到将数据空间分割成更小的区域,以便更有效地查询。在PostgreSQL中,BRIN(Bitmap RANge Indexes)索引是实现这一目标的有效工具,尤其是对于多列BRIN索引,它可以很好地结合数据的聚集效果,减少对大量数据的扫描,从而降低隐式噪音。
SQL流计算是实时数据处理的关键,它允许数据在流入系统时即被处理,而不是等待全部数据存储完毕。在PostgreSQL中,流计算可以通过设置触发器、事件处理器或者使用支持流处理的扩展来实现。这种方式能够实时响应数据变化,提高系统的响应速度和效率。
PostgreSQL的多维存储和SQL流计算能力使其成为处理大数据和实时分析的强大平台。通过理解并应用数据噪音的解决策略,如聚集和空间切割,可以显著提高查询性能,减少资源浪费,从而更好地服务于各种复杂的业务需求。
隐式噪音1 - IO+CPU放大
索引放大
IO+CPU
隐式噪音
剩余44页未读,继续阅读
2018-10-10 上传
2022-06-27 上传
2021-09-20 上传
2014-10-22 上传
2011-07-03 上传
2013-03-11 上传

Francis_Chan
- 粉丝: 4
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
