深度解析:Spark迭代式计算与MapReduce对比及内存优化
需积分: 18 122 浏览量
更新于2024-07-17
收藏 2.57MB PDF 举报
Spark详解深入解析
Spark是一种强大的大数据处理框架,其核心优势在于其迭代式计算模型,相比于Hadoop MapReduce的两阶段(Map和Reduce)设计,Spark提供了更为灵活和高效的处理能力。Spark的主要组件包括RDD (Resilient Distributed Datasets)、内存管理和调度系统。
1. **RDD(Resilient Distributed Dataset)**:Spark的基本数据抽象,它是分布式的、容错的和并行的。RDD支持两种分片函数:HashPartitioner基于哈希划分,RangePartitioner基于范围划分,这对于key-value类型的RDD至关重要。RDD的transformation操作如map是延迟执行的,只有在action触发时才会真正计算,这有助于减少中间结果的产生。
2. **RDD持久化**:Spark允许RDD被持久化到内存或磁盘,以提高性能。持久化的RDD可以在多次计算中重用,减少数据传输开销。
3. **共享变量和分布式内存**:Spark引入了共享变量( Broadcast Variables),使得在集群中可以共享数据,同时提供了统一内存管理模型,使得不同操作之间可以共享数据,提高了效率。
4. **Spark运行流程**:在standalone模式下,Spark包含Master节点(负责任务调度和协调)和Worker节点(执行任务)。Master有主备切换机制,确保高可用性。当Master状态改变时,会触发相应的注册和状态同步机制。
5. **资源调度和任务调度**:Spark通过SchedulerBackend和DAGScheduler进行任务调度,DAGScheduler负责构建任务调度图(DAG),而TaskScheduler则根据资源情况分配任务。application的调度机制是核心,它决定了任务如何被分解和执行。
6. **Shuffle原理**:Shuffle是Spark进行数据交换的关键步骤,主要有两种类型:HashShuffle适用于哈希分区的键值对,Sort-based Shuffle用于排序后的数据。优化shuffle能有效减少网络通信量。
7. **内存管理**:Spark内存管理包括静态内存模型和统一内存模型,前者为每个任务分配固定的内存,后者通过共享内存池提高内存利用率。缓存过程涉及RDD的生命周期管理和内存分配策略。
8. **Tungsten项目**:Spark的Tungsten项目旨在降低内存复制开销,提高内存利用率,是Spark内存管理优化的重要成果。
9. **SparkSQL**:Spark的SQL接口,提供了数据查询和处理的能力,允许用户以SQL的方式操作分布式数据。
10. **源码解读**:理解Spark的内部组件如DAGScheduler、TaskScheduler和SchedulerBackend的源码有助于深入掌握Spark的工作原理和性能优化。
11. **调优实践**:Spark的开发调优涵盖了资源分配、数据倾斜问题(通过调整存储级别来解决)、shuffle优化以及面试准备中的常见问题,如RDD分片函数的理解和transformation与action的区别。
Spark凭借其迭代式计算、内存管理和高效调度机制,为大数据处理提供了强大的工具。深入理解和掌握这些核心概念和实践技巧,是成为Spark专家的关键。
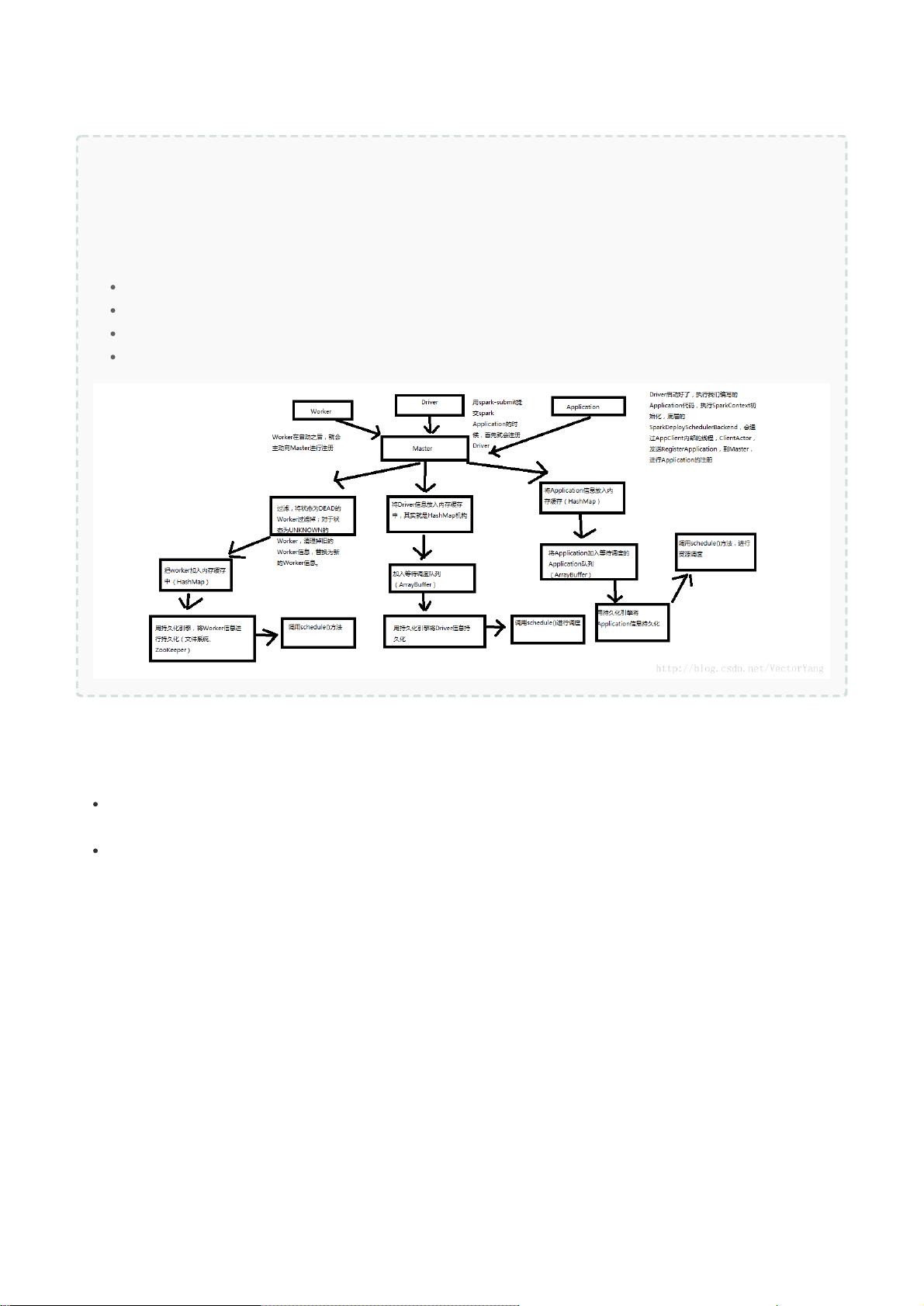
Master注册机制
Driver:在提交spark Application的机器上创建Driver(standalone模式和yarn-client模式在本地,yarn-cluster模
式在NodeManager上),driver启动后,会初始化SparkContext,将我们编写的Application注册到Master上。
(worker启动后就会自动向master进行注册)
Master:
将driver信息、Application信息、worker信息存入缓存(hashmap结构)
将Application加入调度队列,用持久化引擎持久化Application信息,调用schedule()方法进行资源调度
将driver加入调度队列,用持久化引擎持久化driver信息,调用schedule()方法进行资源调度
用持久化引擎持久化worker信息,调用schedule()方法进行资源调度
Master状态改变机制
如果driver的状态是错误、完成、被杀掉、失败。那么将driver从内存缓存中清除,清除driver的持久化信息,
worker中移除driver信息
如果executor状态改变,
worker的工作原理
剩余23页未读,继续阅读
342 浏览量
182 浏览量
145 浏览量
298 浏览量
2021-10-02 上传

sethcss
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- NesEmulator: 开发中的Java NES模拟器
- 利用MATLAB探索植物生长新方法
- C#实现条形码自定义尺寸生成的简易方法
- 《精通ASP.NET 4.5》第五版代码完整分享
- JavaScript封装类实现动态曲线图绘制教程
- 批量优化图片为CWEPB并生成HTML5图片标签工具
- Jad反编译工具:Jadeclipse的下载与安装指南
- 基于MFC的图结构实验演示
- Java中的邮件推送与实时通知解决方案
- TriMED方言技术的最新进展分析
- 谭浩强C语言全书word版:深入浅出学习指南
- STM32F4xx开发板以太网例程源码解析
- C++实现的人力资源管理系统,附完整开发文档
- kbsp_schedule:实时监控俄技大IKBiSP项目日程变更
- Seqspert: 提升Clojure序列操作性能的高效工具
- 掌握Android反编译:jdgui、dex2jar、apktool工具应用
