OneFlow:专为大规模深度学习设计的通用引擎
需积分: 10 199 浏览量
更新于2024-07-17
收藏 853KB PDF 举报
深度学习引擎OneFlow技术实践
在当前深度学习领域,数据并行性是众多开源框架如TensorFlow和PyTorch等的核心优势,它们在处理大规模数据集时表现出色。然而,随着模型规模的不断增大,如ResNet的ExaFlops计算需求、DeepSpeech和Google NMT的巨大参数量,传统的数据并行策略已不足以应对,模型并行或流水线并行成为解决分布式训练问题的新挑战。
OneFlow的研发动机源自于对软件层面瓶颈的认识:尽管硬件的进步显著,特别是GPU和AI专用芯片的发展,但在大规模分布式训练中,如何优化算法在底层硬件上的部署以及最大化硬件效能,是亟待解决的软件层面问题。团队的目标是打造一个通用的深度学习框架,无需用户进行深度定制,就能自动适应不同场景,包括模型并行和流水线并行,从而使得非超算背景的团队也能充分利用分布式GPU集群的性能提升。
OneFlow的诞生源于2015年微软的ResNet项目,其庞大的计算需求显示了计算力在深度学习中的核心地位。然而,当时的硬件环境并不能轻松应对,即使是数千个GPU核心也难以在短时间内完成。模型的参数量增加,如ResNet的几千万参数和DeepSpeech的三亿参数,以及Google NMT的几十亿参数,使得存储需求和计算复杂度进一步攀升。
Facebook的研究成果展示了通过增加数据量和计算资源,即使是使用数百块GPU和大量弱标注图片,也能显著提升模型性能。然而,这并未在公开的开源框架中得到普遍支持,大多仍局限于大型企业内部的定制解决方案。
OneFlow的解决方案不仅包括优化数据并行,还涵盖了模型并行和流水线并行技术,旨在提供一个统一且易于使用的平台,让研究人员和开发者能够更轻松地应对深度学习中的大规模训练挑战。通过OneFlow,即使是小型团队也能享受到分布式计算的优势,推动深度学习的普及和发展。在未来的技术实践中,OneFlow有望成为推动AI创新的重要力量,助力更多创新应用的实现。
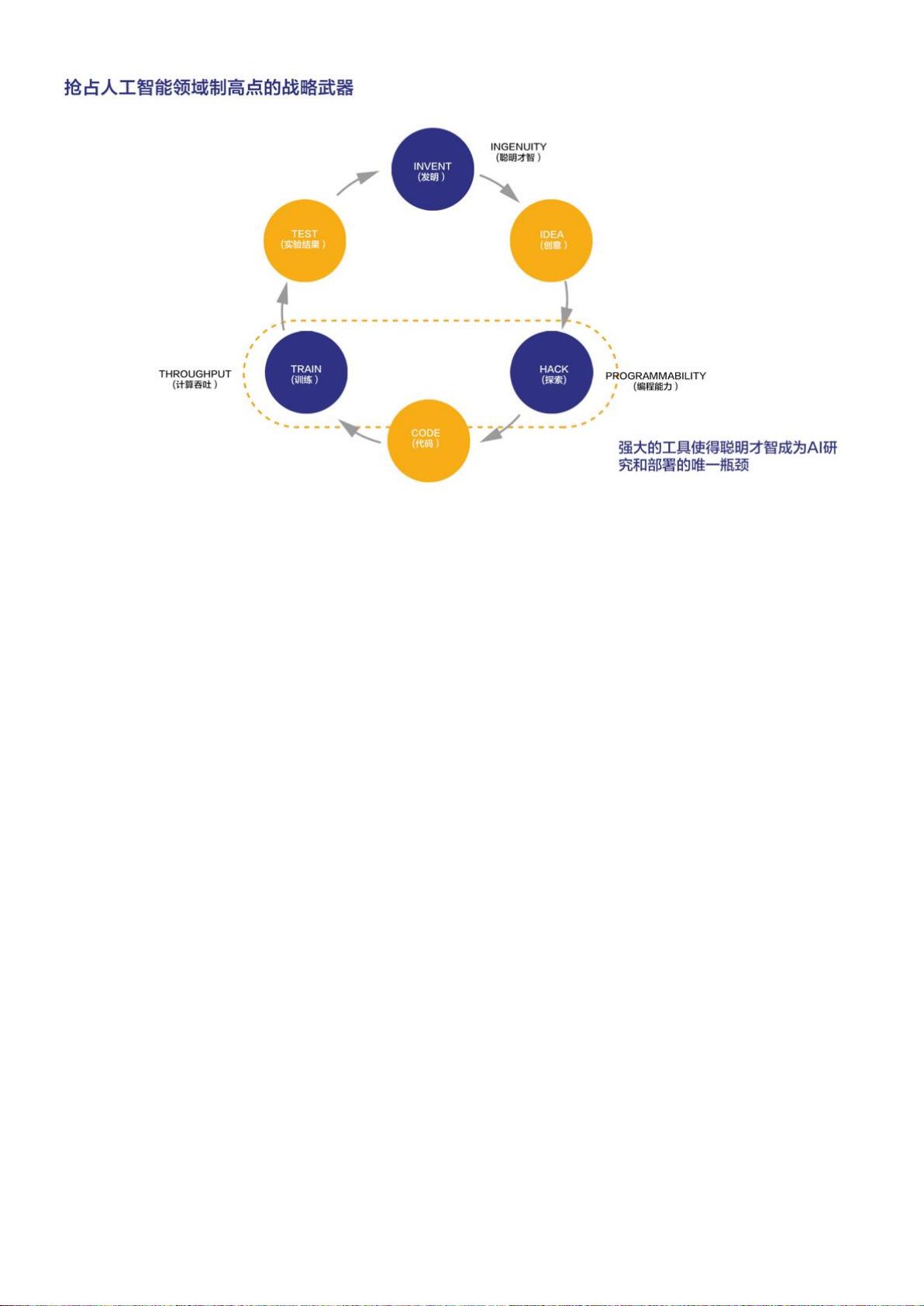
深度学习经过这几年的爆发式发展,特别引人注目的算法层面的创新越来越少了,今年比较吸引眼球
的进步都来自于堆计算力,也就是人们常说的“大力出奇迹”的方式。怎么才能让更多的企业用户能享
受到算力提升的红利,帮助算法科学家完成更多的 KPI, 这是我们 OneFlow 非常关心的问题。常言
道,工欲善其事必先利其器,框架在深度学习研究和落地的过程中就扮演了“工具”的角色,好的工具
能大大加速人工智能研发的效率,甚至可能成为行业竞争的决胜法宝。从 BigGAN 和 BERT 等例子
也可以看出来,当一家公司掌握了其他人不掌握的工具时,就可以引领算法研究的潮流,反过来,当
一家公司的基础设施跟不上的时候,也就没办法做前沿探索,即使是做研究也只能跟在 Google 后面,
因此称深度学习框架是人工智能制高点的战略武器一点不为过。
基于纯硬件的解决思路
剩余16页未读,继续阅读
2020-08-17 上传
2024-05-10 上传
2024-05-10 上传
2021-05-25 上传
2019-07-02 上传
点击了解资源详情
点击了解资源详情

LongLongRiver
- 粉丝: 76
- 资源: 42
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
