动手写网络爬虫:JAVA实现网页抓取与分析
需积分: 11 46 浏览量
更新于2024-07-26
收藏 2.49MB PDF 举报
"这篇教程主要围绕使用JAVA语言实现网络爬虫,内容包括全面了解网络爬虫的工作原理,学习抓取网页、处理HTTP状态码以及理解URL等基础概念。通过学习,读者将具备自行编写网络爬虫的能力,能够针对特定需求抓取互联网上的信息。"
在互联网时代,网络爬虫扮演着至关重要的角色。它们自动遍历网页,收集和整理信息,为搜索引擎、数据分析、市场研究等多种用途提供数据支持。尽管大型搜索引擎已经抓取了大量网页,但定制化的网络爬虫可以满足特定需求,例如企业数据仓库的构建、股票信息的实时抓取等。
首先,我们来深入理解网络爬虫的基础——URL(统一资源定位符)。URL是互联网上资源的唯一标识,它告诉网络如何找到特定的资源。以常见的HTTP URL为例,如`http://www.example.com/path/page.html`,其中:
1. `http` 是协议,指示如何获取资源(这里指HTTP协议)。
2. `www.example.com` 是域名,即资源所在的服务器。
3. `/path/` 是路径,指示服务器上资源的具体位置。
4. `page.html` 是文件名,表示我们要访问的具体资源。
当网络爬虫工作时,它会根据URL向服务器发送请求,服务器响应后返回网页内容。对于网络爬虫来说,理解HTTP状态码至关重要,因为它们反映了请求是否成功。例如,200状态码表示请求成功,404则表示请求的资源未找到。
接下来,我们将学习如何用JAVA语言实现网页抓取。JAVA提供了多种库,如Jsoup或Apache HttpClient,可以帮助我们轻松地发送HTTP请求并解析返回的HTML内容。例如,使用Jsoup库,我们可以创建一个简单的网络爬虫来提取网页标题:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class SimpleCrawler {
public static void main(String[] args) throws Exception {
String url = "http://www.example.com";
Document doc = Jsoup.connect(url).get();
String title = doc.title();
System.out.println("网页标题: " + title);
}
}
```
这段代码首先连接到指定的URL,然后解析返回的HTML文档,并提取出网页的标题。这只是网络爬虫的基本操作,实际的爬虫可能还需要处理反爬策略(如验证码、User-Agent设置)、使用队列管理待爬取的URL(以控制爬取速度和防止重复),甚至进行更复杂的HTML解析和数据提取。
通过以上内容,你已具备了初步的网络爬虫知识,可以开始尝试编写自己的爬虫项目,从互联网的海量信息中获取所需的数据。随着技能的提升,你还可以学习更多高级技巧,如多线程爬取、分布式爬虫、动态网页的处理等,进一步提高爬虫的效率和实用性。
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
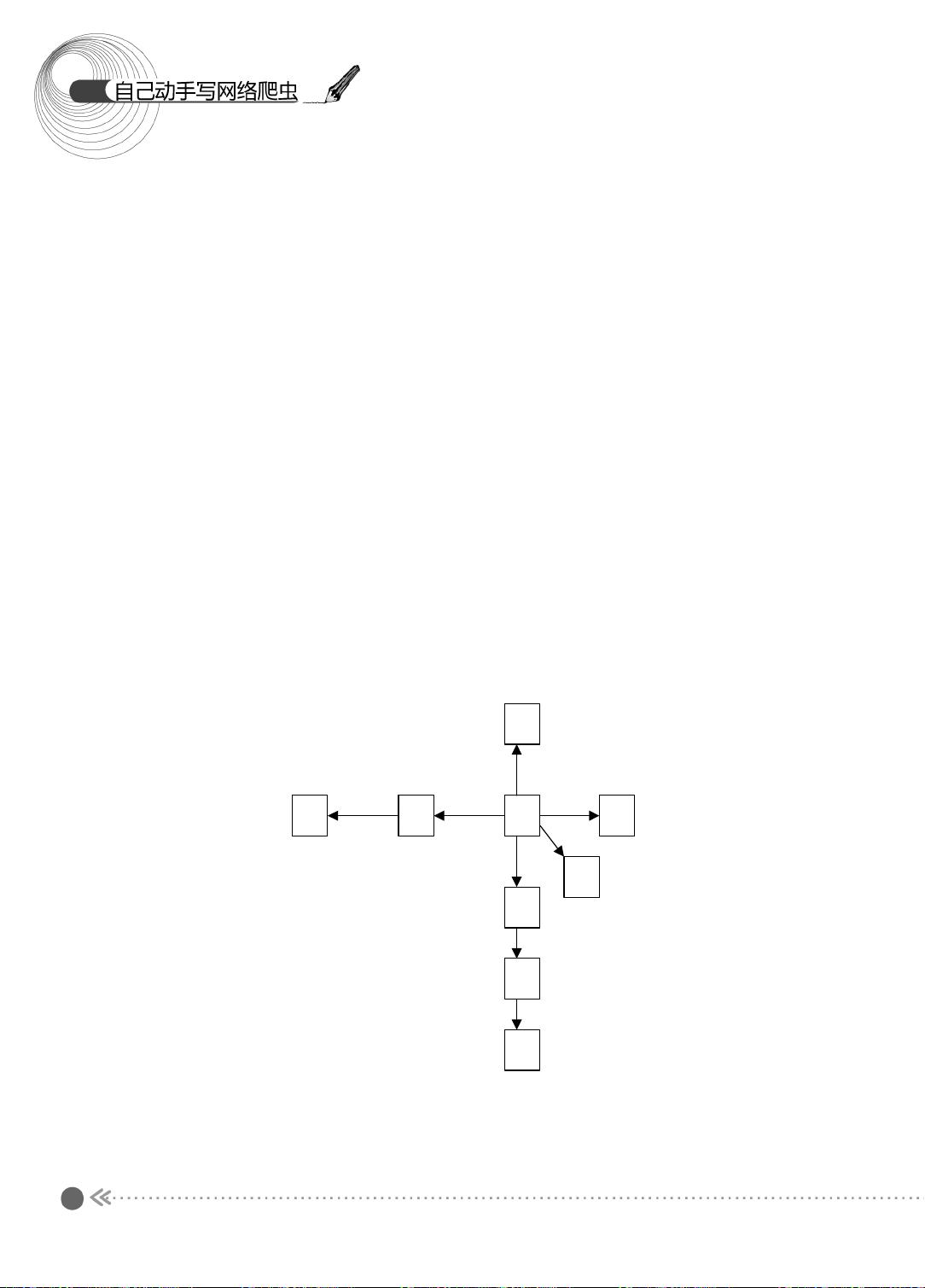
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
2015-11-05 上传
2016-12-13 上传
499 浏览量
2024-12-31 上传
LCC-LCC无线充电恒流 恒压闭环移相控制仿真 Simulink仿真模型,LCC-LCC谐振补偿拓扑,闭环移相控制 1. 输入直流电压350V,负载为切电阻,分别为50-60-70Ω,最大功率3.4
2024-12-31 上传
2024-12-31 上传
2024-12-31 上传

love20yh
- 粉丝: 14
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 专用虚拟局域网(PVLAN)技术与应用.pdf
- IReport用户手册
- 最新的Prototype框架版本1.5.0的API帮助文档(英文原版)。
- 最新的Prototype框架版本1.5.1的API帮助文档(英文原版)。
- 最新的Prototype框架版本1.6.0的API帮助文档(英文原版)。
- 基于单片机的八路竞赛抢答器
- 柱透镜光栅用于显示综述
- suse+linux+10+下安装+oracle9i数据包
- Thinking.In.Java.3rd
- CLIPS-自定义模板属性
- 侯捷的MFC part2
- SharpMap程序开发实例图文教程
- 深入浅出MFC part1
- Vim用户手册中文版 7.2
- 计算机外文翻译C#外文翻译
- TMS320C6000
