Azkaban定时任务:Spark作业整合与Azkaban流程执行
需积分: 0 146 浏览量
更新于2024-08-04
收藏 669KB DOCX 举报
本篇文档详细介绍了如何在Azkaban中设计和管理Spark定时任务。Azkaban是一个流行的开源工作流管理系统,用于调度和监控复杂的IT流程,特别是在大数据处理场景中,如Apache Spark作业的执行。以下是关键知识点的总结:
1. **Spark定时任务结构**:
- 作者根据任务的相似性,对某些Spark任务进行了合并,如25、26、27和44、45、46任务。这些任务具有高度的代码重用价值,因此被封装在一个scala对象中,以便在一个job中执行。这样做可以简化任务管理和减少重复工作。
2. **Job定义与执行**:
- 每个Spark任务被定义为一个Azkaban job,类型为`command`,使用`spark-submit`命令行工具提交Spark应用程序。例如,`dwd_base_event_log.job`和`dwd_base_page_log.job`分别负责解析JSON数据并存储到不同表中。
- `dwd_base_page_log.job`依赖于`dwd_base_event_log.job`,意味着它在前者的执行完成后才会开始。
3. **组织与管理**:
- 所有编写的Spark任务job都放置在`jobs`文件夹下,以结构化的方式进行组织。
- 为了便于Azkaban管理,所有job资源被打包成一个zip文件。
4. **Azkaban集成**:
- 在Azkaban的Web管理界面中创建一个新的工程,将打包的zip文件上传到工程中。这一步完成了Azkaban对Spark任务的配置和集成。
5. **任务调度与监控**:
- 创建并启动执行Flow,即一系列相互关联的任务序列。Azkaban会按照预定的时间或条件触发这些job的执行。
- 任务执行成功后,可以通过Azkaban的Web界面查看Flow的日志,以获取任务执行的详细情况和任何可能的错误报告。
通过这种设计,Azkaban帮助团队有效地协调和监控Spark定时任务,确保大数据处理过程的可靠性和效率。同时,任务的模块化和依赖管理使得维护和调整变得更加方便。
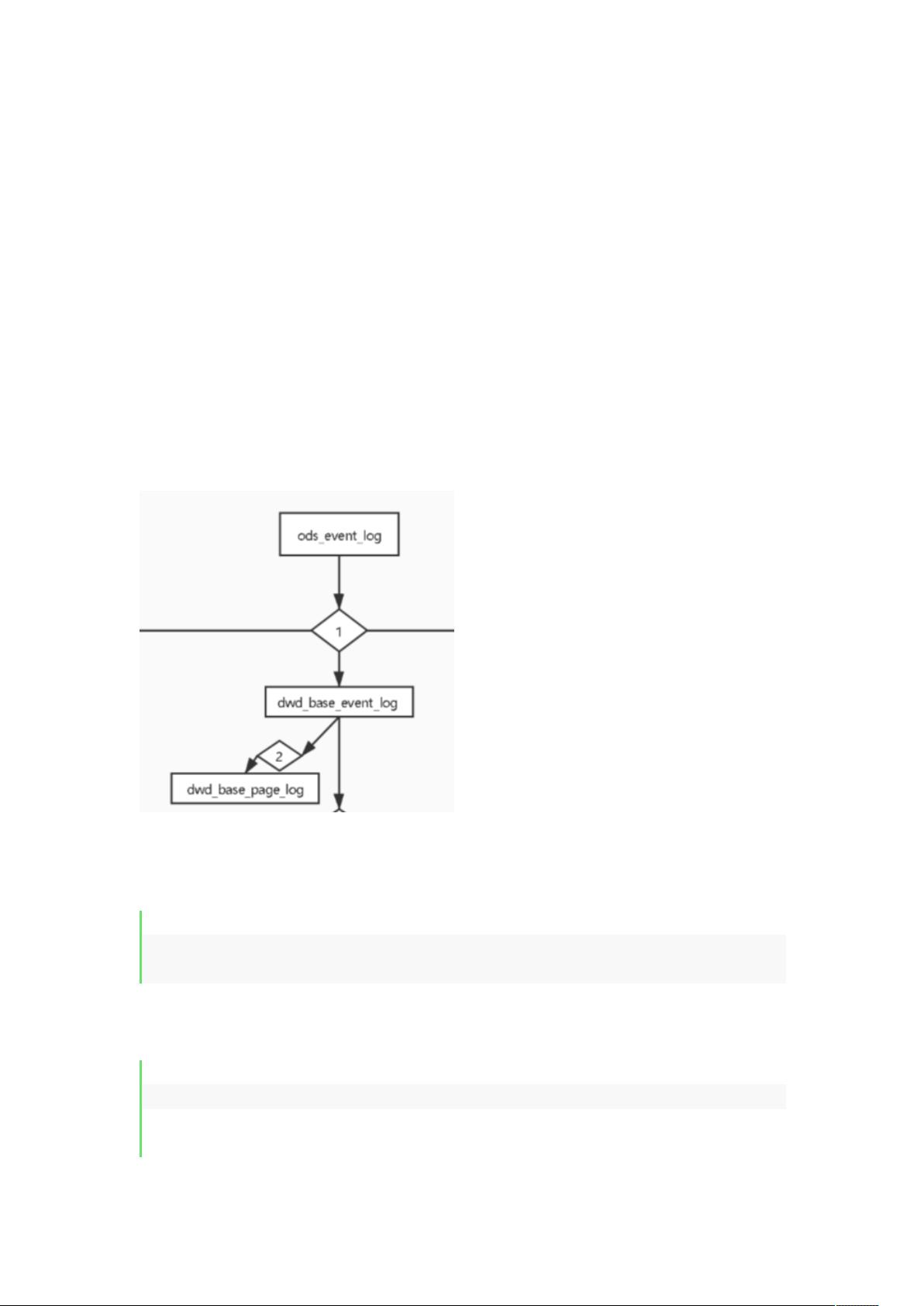
一、根据我们的 spark 定时任务进行 job 的编写
基本一个 spark 任务编写一个 job
(例外如下
1.我们将 25,26,27 任务合并成一个 job,合并原因是这三个 spark 任务的实
现方法极其相似,我们就在 spark 任务代码中将他们写到一个 scala 对象中。
该 job 作用为向 ads_usr_dau_cube、ads_usr_wau_cube、ads_usr_mau_cube 表
中导入数据,这三个表的具体执行时间在实现方法中做了判断
2.我们将 44,45,46 任务合并成一个 job,合并原因同上。该 job 只需要调用
这 个 scala 对 象 就 行 了 。 该 job 作 用 为 向 base_user_active_day 、
base_user_active_week、base_user_active_month 表中导入数据,这三个表的
具体执行时间在实现方法中做了判断)
以任务 1、2 为例
任务 1:dwd_base_event_log.job
1. type=command
2. command=spark-submit --master yarn --deploy-mode cluster --class cn.edu.neu.titan.titanSpark.analy
sis.base.function.JSONParseFunction /BigData/jars/titanSpark-1.0-SNAPSHOT.jar
任务 2:dwd_base_page_log.job 依赖于 dwd_base_event_log.job
1. type=command
2. dependencies=dwd_base_event_log
3. command=spark-submit --master yarn --deploy-mode cluster --class cn.edu.neu.titan.titanSpark.analy
sis.base.function.JSONParseFunction /BigData/jars/titanSpark-1.0-SNAPSHOT.jar
下载后可阅读完整内容,剩余4页未读,立即下载
190 浏览量
215 浏览量
371 浏览量
120 浏览量
1596 浏览量
177 浏览量
2021-05-24 上传
211 浏览量
140 浏览量

懂得越多越要学
- 粉丝: 28
 我的内容管理
展开
我的内容管理
展开







最新资源
- CodeVisionAVR C库详解:全方位涵盖C函数集
- PS/2鼠标与键盘接口详解:技术概览与协议介绍
- 病毒编程基础:创建与逻辑解析
- ISO 9660详解:规范、实现与扩展
- Intel AGP 2.0接口规范详解与关键要素
- 深入解析:WAVE音频文件格式
- 北京大学计算机考研经验与心得
- 企业GIS与SOA:架构、服务与实践
- 详解Socket编程:原理、转换与地址结构
- MPI并行编程入门与高级特性探索
- C#入门到精通:从语言概述到面向对象编程
- Windows BMP文件格式详解
- 精通BIOS设置与调整:电脑优化秘籍
- C++文件操作与流的使用详解
- Ajax+Jsp+Access实现唯一性校验教程
- SOA与Web服务:降低IT复杂性的关键
