深度学习中的局部最优点与鞍点解析
版权申诉
124 浏览量
更新于2024-08-04
收藏 522KB PDF 举报
"这篇文档探讨了深度学习和机器学习模型在优化过程中可能遇到的问题,特别是关于局部最优点和鞍点的理论分析。作者通过解释一阶导数和二阶导数的重要性,阐述了如何区分局部最优点和鞍点,并讨论了在高维空间中模型陷入鞍点的可能性大于陷入局部最优点的情况。"
在深度学习和机器学习中,模型的优化通常涉及到梯度下降法,这是一种基于参数更新方向与梯度相反的算法。然而,当模型在训练初期快速收敛时,可能会陷入局部最优点,即损失函数的一阶导数在该点为零的区域。局部最优点周围,梯度接近于零,导致模型无法通过常规的梯度下降步骤跳出这个区域,因为梯度下降法本身会沿着负梯度方向更新,从而进一步巩固模型在局部最优点的状态。
然而,仅依赖一阶导数不足以判断一个点是否为真正的局部最优点。例如,鞍点也是一阶导数为零的点,但并非局部最优点。鞍点在某些维度上是局部最小值,而在其他维度上是局部最大值。为了区分两者,我们需要考虑二阶导数,也就是Hessian矩阵的元素。如果在所有方向上二阶导数都为正,那么该点是严格局部最小点;若有至少一个方向上的二阶导数为负,那么该点是一个鞍点。
根据最大熵原理,在没有先验知识的情况下,我们假设二阶导数大于零和小于零的概率相等,均为0.5。对于具有n个参数的模型,损失曲面存在于n+1维空间。如果通过梯度下降法到达一个所有方向导数都为零的点,那么它是局部最优点的概率是(1/2)^n,而作为鞍点的概率是1 - (1/2)^n。随着模型参数n的增加,陷入鞍点的概率显著上升。
这意味着,尤其在深度学习模型中,由于大量的参数,模型更可能在优化过程中找到鞍点而非局部最优点。这也是为什么在实际训练中,人们会采用不同的优化策略,如动量法、RMSprop或Adam等,这些方法在一定程度上可以帮助模型避开局部最优点和鞍点,以期望找到全局最优解或者更优的解决方案。
理解模型优化过程中的局部最优点和鞍点概念至关重要,因为这直接影响到模型的性能和泛化能力。通过深入研究优化理论和采用先进的优化算法,我们可以更好地训练模型,避免陷入不佳的局部最优点,并提高模型的训练效果。
你的模型真的陷⼊局部最优点了吗?
原创
⼣⼩瑶
2017-11-21⼣⼩瑶的卖萌屋
来⾃专辑
卖萌屋@深度学习炼丹技巧
⼩⼣曾经收到过⼀个提问:“⼩⼣,我的模型总是在前⼏次迭代后很快收敛了,陷⼊到了⼀个局部最优点,怎么也跳
不出来,怎么办?”
本⽂不是单纯对这个问题的回答,不是罗列⼯程tricks,⽽是希望从理论层⾯上对产⽣类似疑问的⼈有所启发。
真的结束于最优点吗?
我们知道,在局部最优点附近,各个维度的导数都接近0,⽽我们训练模型最常⽤的梯度下降法⼜是基于导数与步⻓
的乘积去更新模型参数的,因此⼀旦陷⼊了局部最优点,就像掉进了⼀⼝井,你是⽆法直着跳出去的,你只有连续
不间断的依托四周的井壁努⼒向上爬才有可能爬出去。更何况梯度下降法的每⼀步对梯度正确的估计都在试图让你
坠⼊井底,因此势必要对梯度“估计错很多次”才可能侥幸逃出去。那么从数学上看,什么才是局部最优点呢?
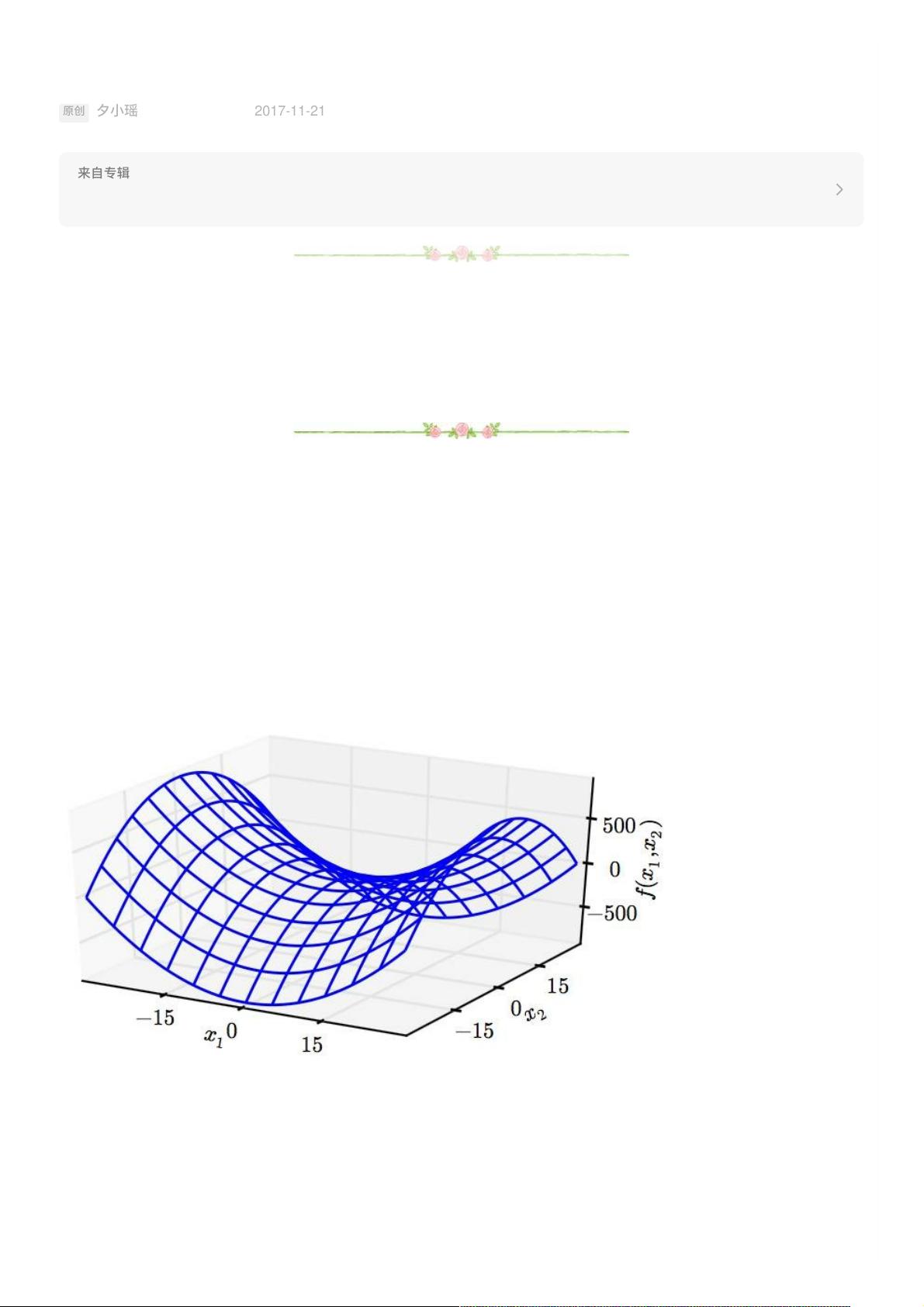
这个问题看似很⽩痴,很多⼈会说“局部最优点不就是在loss曲⾯上某个⼀阶导数为0的点嘛”。这就不准确啦,⽐如
下⾯这个⻢鞍形状的中间的那个点:
(图⽚来⾃《deep learning》)
显然这个点也是(⼀阶)导数为0,但是肯定不是最优点。事实上,这个点就是我们常说的鞍点。
显然,只⽤⼀阶导数是难以区分最优点和鞍点的。
我们想⼀下,最优点和鞍点的区别不就在于其在各个维度是否都是最低点嘛〜只要某个⼀阶导数为0的点在某个维度
下载后可阅读完整内容,剩余3页未读,立即下载
2021-09-29 上传
2021-09-26 上传
2021-08-14 上传
2023-06-20 上传
2021-09-25 上传
2021-08-11 上传
2021-09-29 上传
2021-09-26 上传
2021-09-26 上传

普通网友
- 粉丝: 1263
- 资源: 5619
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
