微软技术助力机器学习:项目选型与工具指南
需积分: 9 179 浏览量
更新于2024-07-17
收藏 28.61MB PDF 举报
"《机器学习与微软技术》一书,由Leila Etaati于2019年由Apress出版社发布,探讨了如何在商业软件开发领域广泛应用机器学习。本书的核心内容涵盖了机器学习的基本概念、方法和不同类型,以及其在微软产品中的实际应用,如Bing搜索引擎、Xbox和Kinect等。作者特别关注如何选择适合项目的架构和工具,使读者能够充分利用微软提供的强大机器学习工具,如SQL Server、Power BI和.NET等,以创建更智能的应用程序和报表。
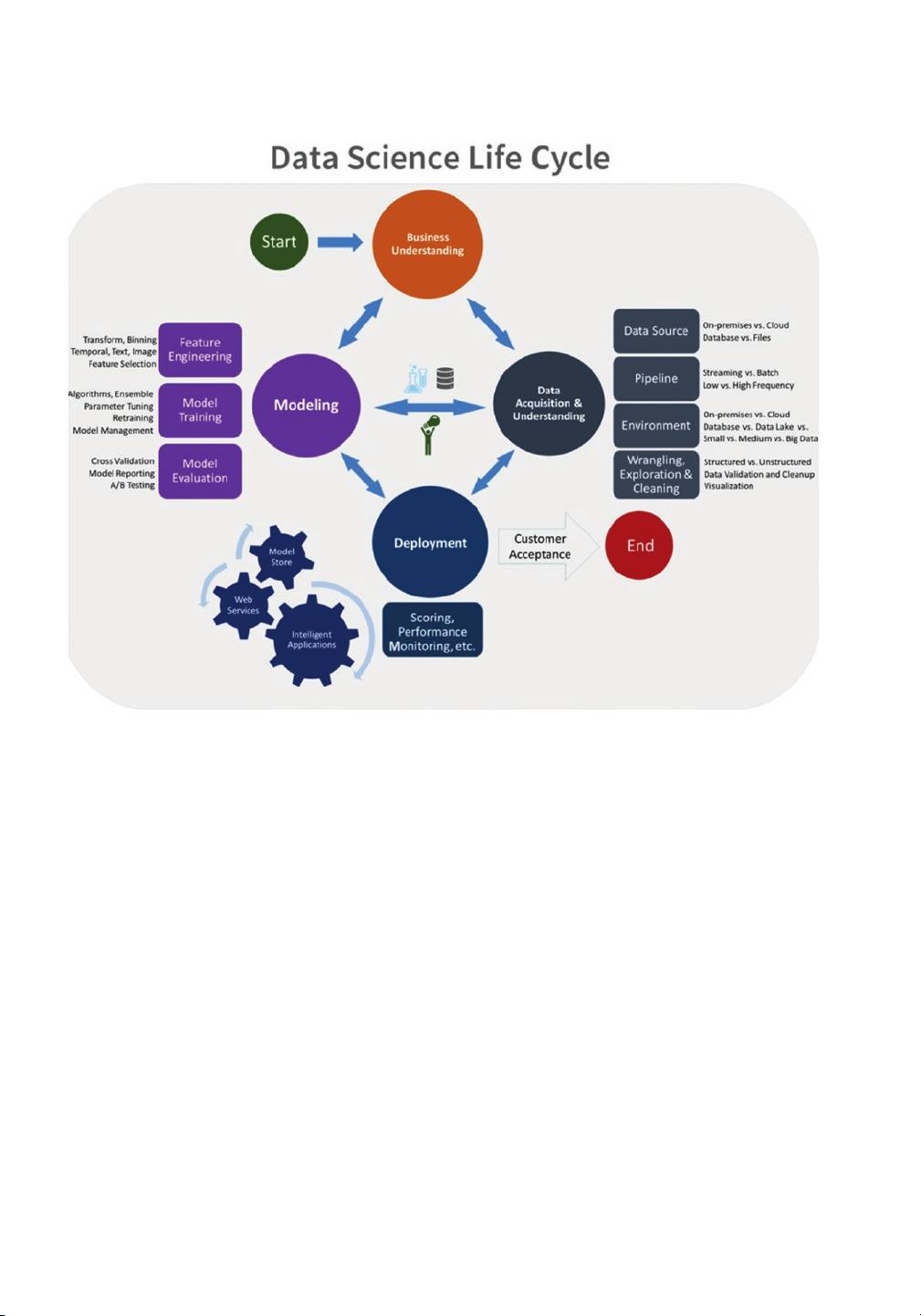
章节中深入剖析了机器学习项目的生命周期,从数据收集、预处理、模型选择到训练和部署,每个阶段都进行了详细指导。读者可以了解到微软技术生态系统中集成的机器学习工具的优势,以及如何有效地将这些工具应用于软件开发流程中,提升决策制定者对数据的洞察力,从而获取更为精准和深入的信息。
此外,版权方面,所有内容受版权保护,未经许可,禁止任何形式的翻译、复制、重印、朗诵、广播、微缩胶片复制、物理或数字传输,以及任何形式的电子适应或类似技术的使用。书中可能会包含商标名称、标志和图像,尽管并非每次出现都标注商标符号。
《机器学习与微软技术》是一本实用指南,对于希望在日常工作中利用微软平台进行机器学习实践的开发者和技术人员来说,提供了宝贵的参考和实战经验。通过阅读这本书,读者将能掌握如何在实际项目中构建和优化机器学习解决方案,提升软件产品的智能化水平。"
4
Academics and authors have proposed different definitions of machine learning.
For example, Sebastian Raschka defined machine learning as tools for making sense
of data, using algorithms [2]. He mentioned that we encounter a significant amount of
structured (numbers) and unstructured (image, voice text, and so forth) data. Gaining
insight from these data affects the decision-making process and helps managers to
achieve a better understanding of what happened, why it happened, what will happen in
future, and how to make it happen.
The concepts of machine learning are based on discovering common patterns from
current data sets. Historically, we created reports and software to understand what
happened in the past. Analyzing recent events and data always helps us to perform
further analysis, such as finding key performance indicators (KPIs), and so forth.
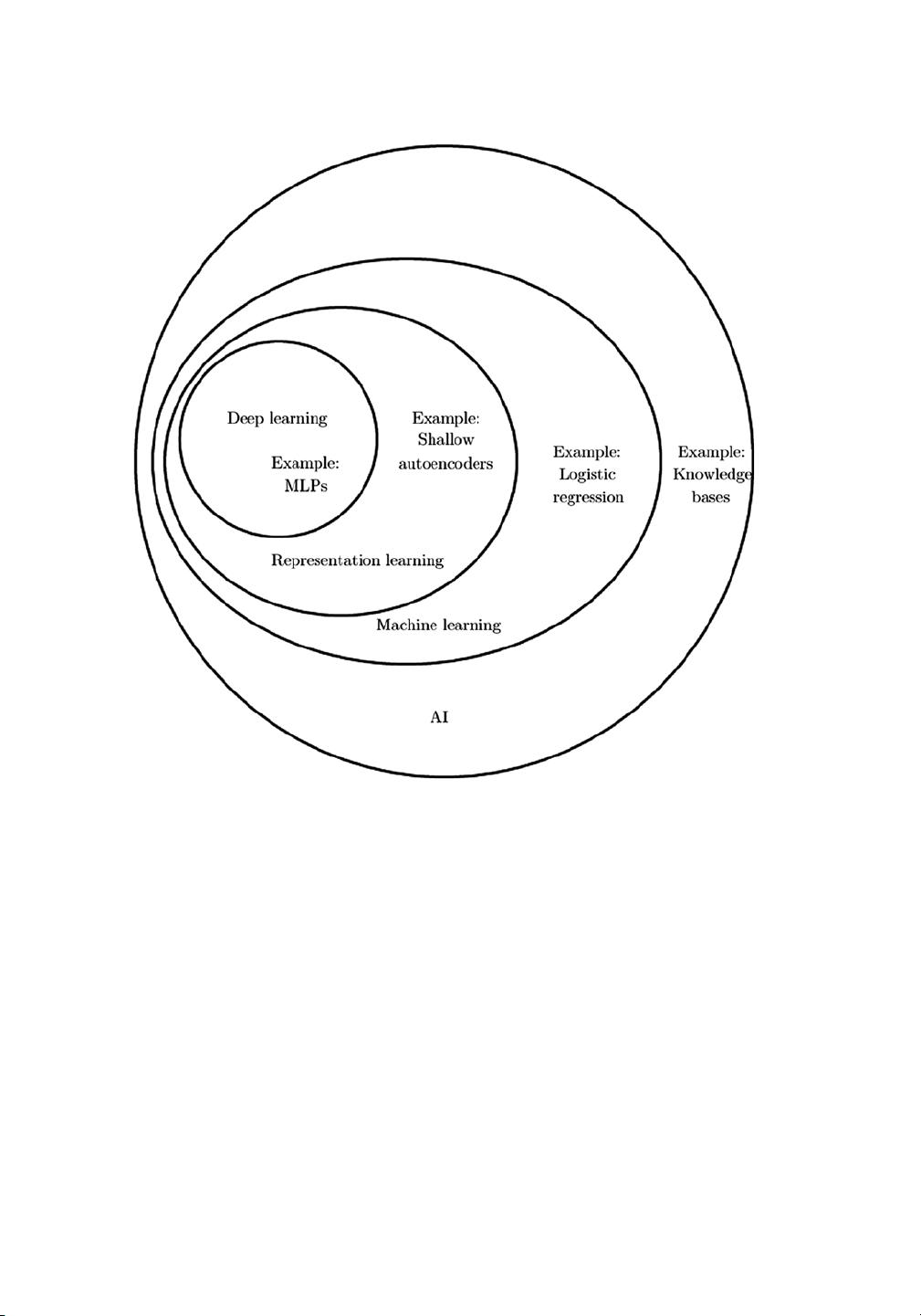
Figure 1-1. A Venn diagram showing the AI category and subcategories [1]
Chapter 1 IntroduCtIon toMaChIne LearnIng


剩余362页未读,继续阅读
2018-07-25 上传
2021-10-21 上传
2018-03-24 上传
2019-07-24 上传
2018-03-11 上传
2018-04-29 上传
2017-10-06 上传
2020-07-12 上传

OneCrazyStone
- 粉丝: 5
- 资源: 45
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
