




深度学习优化:解密自适应梯度法与学习率的相互作用
下载需积分: 16 | PDF格式 | 1015KB |
更新于2024-07-15
| 68 浏览量 | 举报
"从学习速率中解开自适应梯度法(Disentangling Adaptive Gradient).pdf"
本文主要探讨了深度学习优化算法评估中的关键问题,尤其是自适应梯度方法与学习速率调整之间的相互作用。学习速率是神经网络训练过程中一个极其重要的超参数,它对模型的收敛速度和泛化能力有着显著的影响。作者们通过引入了一种名为"嫁接"的实验方法,来分离更新的大小(即步长)和方向,以此来揭示一些以往研究中可能被忽视的细节。
"Disentangling Adaptive Gradient Methods from Learning Rates" 是该研究的核心主题,意在剖析自适应梯度算法如何独立于学习率工作。自适应梯度方法,如Adagrad、RMSprop、Adam等,通过动态调整每个参数的学习率来优化模型,这些方法在处理具有不同尺度的参数时表现优秀。然而,它们的内部机制常常与学习率的调整混淆,导致对这些方法的理解存在误区。
在"嫁接"实验中,研究人员将更新的幅度与方向分离开,揭示出许多关于自适应梯度方法的现有观点可能源于对学习率时间表的隔离不足。这种实验设计使得研究者能够更准确地评估每个因素的单独效果,从而对算法的性能有更深入的理解。
此外,论文还对自适应梯度方法的泛化能力进行了实证和理论的回顾。泛化能力是衡量模型在未见数据上的表现,这对于实际应用至关重要。作者们的目标是提供一个清晰的视角,帮助理解这些优化方法为何以及在何种情况下能实现良好的泛化。
通过这些研究,作者们期望能为深度学习社区提供更有力的工具和洞察,以便于更好地理解和调整这些算法,从而提高模型的训练效率和泛化性能。这不仅有助于优化现有的神经网络架构,也可能启发新的优化策略的开发,进一步推动深度学习领域的发展。

of M’s step and direction of D’s step.
Algorithm 2 AdaGraft meta-optimizer
1: Input: Optimizers M, D; initializer w
1
; > 0.
2: Initialize M, D at w
1
.
3: for t = 1, . . . , T do
4: Receive stochastic gradient g
t
at w
t
.
5: Query steps from M and D:
w
M
:= M(w
t
, g
t
), w
D
:= D(w
t
, g
t
).
6: Update with grafted step:
w
t +1
← w
t
+
kw
M
– w
t
k
kw
D
– w
t
k +
· (w
D
– w
t
) .
7: end for
Layer-wise vs. global grafting.
Two natural variants of Algorithm 2 come to mind, especially if one is
concerned about efficient implementation (see Appendix C.1). In the layer-wise version, we view w
t
as a
single parameter group (usually a tensor-shaped variable specified by the architecture), and apply AdaGraft
and its child optimizers to each group. In the global version, w
t
contains all of the model’s weights. We
discuss and evaluate both variants, but our main experimental results use layer-wise grafting.
The first experimental question addressed by AdaGraft is the following: To what degree does an optimizer’s
implicit step size schedule determine its training curve? To this end, given a set of base optimizers, we can
perform training runs for all pairs (
M
,
D
), where grafting (
A
,
A
) is understood as simply running
A
. For the
main experiments, we use SGD, Adam, and AdaGrad, all with momentum β
1
= 0.9.
All experiments were carried out on 32 cores of a TPU-v3 Pod [
JYP
+
17
], using the Lingvo [
SNW
+
19
]
sequence-to-sequence framework built on top of TensorFlow [ABC
+
16].
3.2 ImageNet classification experiments
We ran all pairs of grafted optimizers on a 50-layer residual network [
HZRS16
] with 26M parameters, trained
on ImageNet classification [
DDS
+
09
]. We used a batch size of 4096, enabled by the large-scale training
infrastructure, and a learning rate schedule consisting of a linear warmup and stepwise exponential decay. All
details can be found in Appendix C.2.
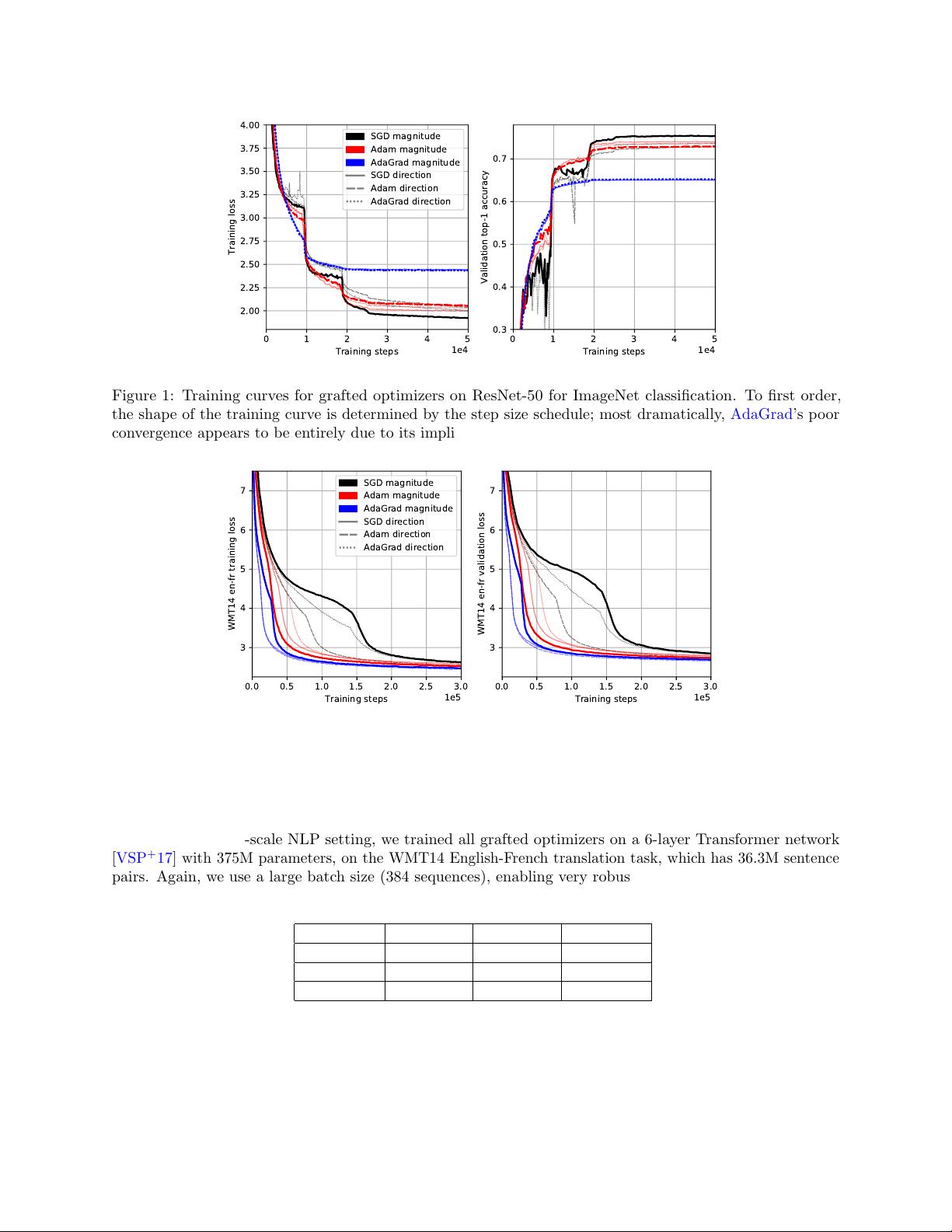
Table 2 shows top-1 and top-5 accuracies at convergence. The final accuracies at convergence, as well as
training loss curves, are very stable (
<
0.1% deviation) across runs, due to the large batch size. Figure 1
shows at a glance our main empirical observation: that the shapes of the training curves are clustered by the
choice of M, the optimizer which supplies the step magnitude.
We stress that no additional hyperparameter tuning was done in these experiments; not even the global
scalar learning rate needed adjustment. Thus, starting with N tuned optimizer setups, grafting produces a
table of N
2
setups with no additional effort. Each row of this table controls for the implicit step size schedule.
M
D SGD Adam AdaGrad
SGD 75.4 · 92.6 72.8 · 91.2 73.7 · 91.4
Adam 74.1 · 91.9 73.0 · 91.3 73.7 · 91.6
AdaGrad 65.0 · 85.9 65.1 · 86.0 65.3 · 86.3
Table 2: Top-1 and top-5 accuracies at training step t = 50K for ImageNet experiments. Averaged over 3
trials; no accuracy varied by more than 0.1%.
5
剩余25页未读,继续阅读
相关推荐



syp_net
- 粉丝: 158
 我的内容管理
展开
我的内容管理
展开








最新资源
- 魅族手机宣传PPT模板下载,展示产品亮点动态效果
- Java插件开发:探索NoMorePlugins项目
- 开发人员专属响应式投资组合模板
- SQSim开源项目:Java编写的简单队列模拟器
- 自动收藏学术论文的crx插件
- serverless-policy-generator:简化无服务器Lambda部署权限设置
- CSS3实现飞机交互特效:掌握空中飞行轨迹
- Fridge-N-Pantry应用程序:智能管理家庭食物库存
- Excel-Tournament-Assistant:自动电子表格助力锦标赛组织
- Tibia NoDie:基于AutoHotkey的PC游戏自动化宏与修复工具
- Wedge插件:提升远程学习与工作效率的Chrome扩展
- node-bumpy工具在JSON文件中自动化添加版本号
- C语言实现的qemu-run: 终端管理虚拟机无需脚本
- 深入理解数据结构与算法:C++实现解析
- Flesh-Java文本分析工具的开源项目介绍
- Python技术在电子杂志制作中的应用










