SLURM集群管理:组件、命令及脚本编写指南
需积分: 0 33 浏览量
更新于2024-08-04
收藏 495KB PPTX 举报
本文主要介绍了高性能计算集群系统中的SLURM集群管理系统,包括其核心组件、常用命令参数以及SLURM脚本的编写方法。SLURM(Simple Linux Utility for Resource Management)是一种广泛使用的资源调度器,适用于大规模的并行计算环境。
在SLURM架构中,有三个主要的守护进程:
1. **slurmctld**:管理节点守护进程,负责全局监控和资源分配。它接收作业请求,并确保资源的有效分配。为了高可用性,通常会设置为主备模式。
2. **slurmd**:计算节点进程,每个计算节点上都有一个slurmd实例,用于监控和管理运行在其上的任务。它接收任务、分配任务,并根据需求终止正在运行的任务。
3. **slurmdbd**:数据库守护进程,提供了一个企业级的安全数据库接口,用于存储账单信息和其他重要数据。
了解SLURM进程的状态,可以通过以下命令查看:
- `systemctl status slurmctld`:检查slurmctld的运行状态。
- `systemctl status slurmdbd`:检查slurmdbd的运行状态。
- `systemctl status slurmd`:检查slurmd的运行状态。
SLURM的配置文件非常重要,其中:
- **slurm.conf**:主配置文件,包含了集群的基本设置和配置信息。
- **slurmdbd.conf**:slurmdbd的配置文件,用于设定数据库相关参数。
- **gres.conf**:通用资源配置文件,用于定义特殊硬件资源。
- **Topology.conf**:定义网络拓扑,帮助优化任务调度。
- **slurm_node.conf**:节点配置文件,详细描述集群中的每个计算节点。
- **slurm_partition.conf**:分区配置文件,定义不同计算资源的分区策略。
SLURM节点的状态描述了其当前的工作情况:
- **Allocated**:节点已被分配至少一个作业。
- **Allocated+**:除了分配的作业外,还有作业正在完成。
- **Completing**:所有关联作业都在完成过程中。
- **Down**:节点不可用。
- **Drained**:节点不能处理新的作业,但当前作业仍在执行。
- **Draining**:正在执行作业,但不会接受新的作业,待最后一个作业完成后转为Drained状态。
- **Fail**:预计即将故障,无法响应管理请求。
- **Failing**:正在运行作业,但预期即将故障。
- **Future**:尚未完全配置,但未来可使用。
- **Idle**:空闲状态,未分配任何作业,可接受新任务。
- **Inval**:节点配置无效,与SLURM管理器获取的配置不符。
- **Reboot_I**:重启中,表明节点正在进行重启过程。
编写SLURM脚本是调度作业的关键。脚本通常包含作业的基本信息,如执行命令、内存需求、CPU核心数、运行时间限制等,使用`sbatch`命令提交。例如:
```bash
#!/bin/bash
#SBATCH --job-name=myjob
#SBATCH --output=myjob.out
#SBATCH --ntasks=4
#SBATCH --cpus-per-task=1
#SBATCH --mem-per-cpu=1G
#SBATCH --time=01:00:00
# 在这里放置你的程序执行命令
your_command
```
这个例子中,`SBATCH`后的参数定义了作业名称、输出文件、任务数量、每个任务的CPU核心数、每个核心的内存需求以及作业运行的最大时间。
掌握SLURM的使用,能有效地管理和调度高性能计算集群资源,提高计算效率。在实际应用中,应结合具体需求调整配置和脚本,以实现最佳性能和资源利用率。
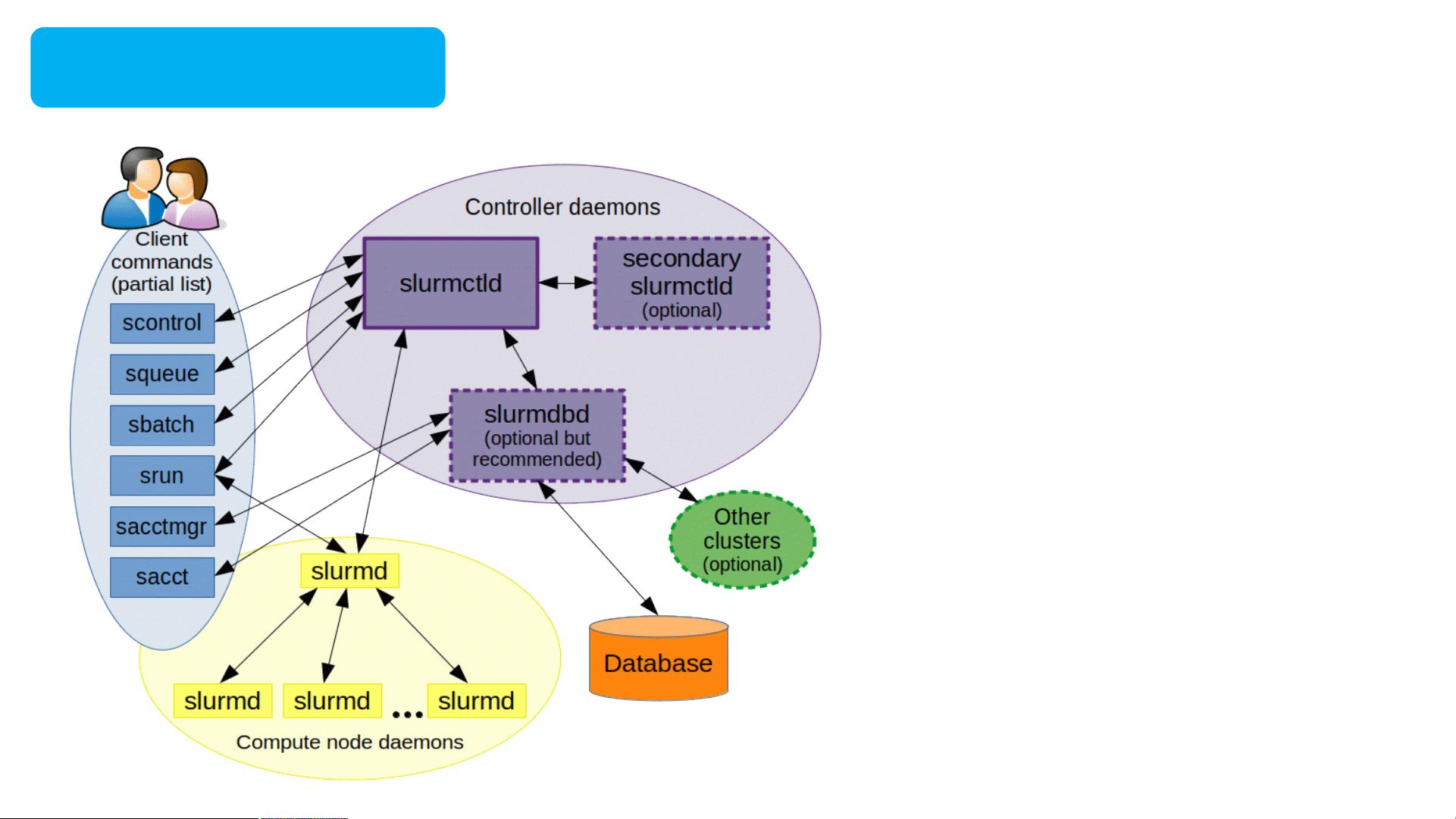
slurm架构
slurmctld:管理节点守护进程,
监控所有slurm的守护进程和资源,
接收作业并分配资源给这些作业。考
虑到关键场景,通过需要主备模式。
slurmd:计算节点进程,作用是
监控运行在计算节点的所有任务,接
收任务,分配任务,根据请求终止正
在运行的任务。
slurmdbd:数据库守护进程,为
提供一个安全的企业级数据库接口,
主要用于归档账单信息。
下载后可阅读完整内容,剩余9页未读,立即下载
2023-07-26 上传
2009-01-15 上传
2024-01-04 上传
2023-05-25 上传
2023-07-16 上传
2024-11-01 上传
2024-11-01 上传
2023-09-07 上传
2023-05-26 上传

LonelyLinguist
- 粉丝: 11
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- d3graphTheory:使用d3.js制作的互动式和彩色图论教程
- arcticseals:与NOAA海洋哺乳动物实验室合作进行的深度学习项目,用于对航空影像中的北极海豹进行检测和分类,以了解北极海豹如何适应不断变化的世界
- 61IC_S4282.rar_OpenCV_Visual_C++_
- FramerBasics
- A+InfoPower 2011(good).zip
- tableone:用于创建“表1”的R包,描述具有或不具有倾向得分加权的基线特征
- Discreet Links-crx插件
- NagiosCFG-开源
- ANFIS-Design.rar_matlab例程_matlab_
- matlab代码续行-UWPFlow:UWContinuationPowerFlow(c)1992、1996、1999、2006C.Caniz
- CSS3横向手风琴风格菜单
- leetcode:收集LeetCode问题以使编码面试更上一层楼! -使用[LeetHub](https
- ekpmeasure:用于各种实验的计算机控制代码存储库
- vue+node+mongodb完成的拼多多移动端仿站(练习项目).zip
- 查找:查找R的完整功能定义,包括编译后的代码,S3和S4方法
- CONTROLLER.zip_单片机开发_C++_
