哈夫曼编码解码技术与实现
需积分: 0 33 浏览量
更新于2024-08-04
收藏 184KB DOCX 举报
"哈夫曼树编码解码需求分析1"
在进行哈夫曼树编码解码的需求分析时,我们首先要理解哈夫曼编码的基本原理和应用。哈夫曼编码是一种特殊的前缀编码方法,主要用于数据压缩,通过构建最优二叉树——即哈夫曼树,来为每个字符或符号分配一个唯一的二进制编码,使得频繁出现的字符拥有较短的编码,从而在整体上减少数据的存储空间。
二叉树是哈夫曼编码的基础数据结构,它由节点组成,每个节点可以有零个、一个或两个子节点。在二叉树中,节点分为叶子节点和非叶子节点。叶子节点通常代表待编码的字符或符号,而非叶子节点则是为了构造哈夫曼树而创建的内部节点。二叉树的节点通常包含以下属性:值(权值)、父节点引用以及左右子节点引用。
哈夫曼树(Huffman Tree),又称为最优二叉树,是在给定一组权值的情况下,通过合并最小权值的节点来构建的。构建过程如下:
1. 将每个权值视为一个单独的节点,形成一个森林F,其中每个节点都是一个只有一个权值的二叉树。
2. 从森林F中选取权值最小的两个节点,将它们合并为一个新的二叉树,新树的权值为两个子节点的权值之和,且这两个子节点分别成为新树的左子节点和右子节点。
3. 删除原来的两个节点,将新树添加回森林F。
4. 重复步骤2和3,直到森林中只剩下一棵树,这棵树就是哈夫曼树。
哈夫曼树的节点类通常包含如下属性:权值key,左子节点left,右子节点right,以及父节点parent。此外,为了方便处理节点的比较和复制,节点类可能还需要实现Comparable接口和Cloneable接口。
哈夫曼编码的实现思路包括以下几个步骤:
1. 构建哈夫曼树:根据输入的字符频率,按照上述方法构造哈夫曼树。
2. 生成编码表:从根节点出发,通过遍历哈夫曼树,左子树代表0,右子树代表1,记录下从根节点到每个叶子节点的路径,形成每个字符的哈夫曼编码。
3. 文件编码:用哈夫曼编码替换原始文件中的字符,生成编码后的文件。
4. 文件解码:读取编码后的文件,根据编码表恢复出原始字符,完成解码。
在实际实现过程中,除了基本的数据结构和算法外,还需要考虑如何高效地存储和查找编码表,以及如何处理边界情况和错误检测。对于编码解码的效率,可以通过优化数据结构和算法来提高,例如使用优先队列(如堆)来快速找到最小权值的节点,以及使用位操作来加速编码和解码过程。哈夫曼编码解码需求分析的核心在于理解和利用哈夫曼树的特性,实现高效的数据压缩与还原。
《哈夫曼树编码解码》需求分析
一、实验内容
运用哈夫曼编码的相关知识对任意文本文件进行编码、解码。
二、需要用的数据结构以及实现思路
需要用到二叉树、HuffMan 树、递归等数据结构
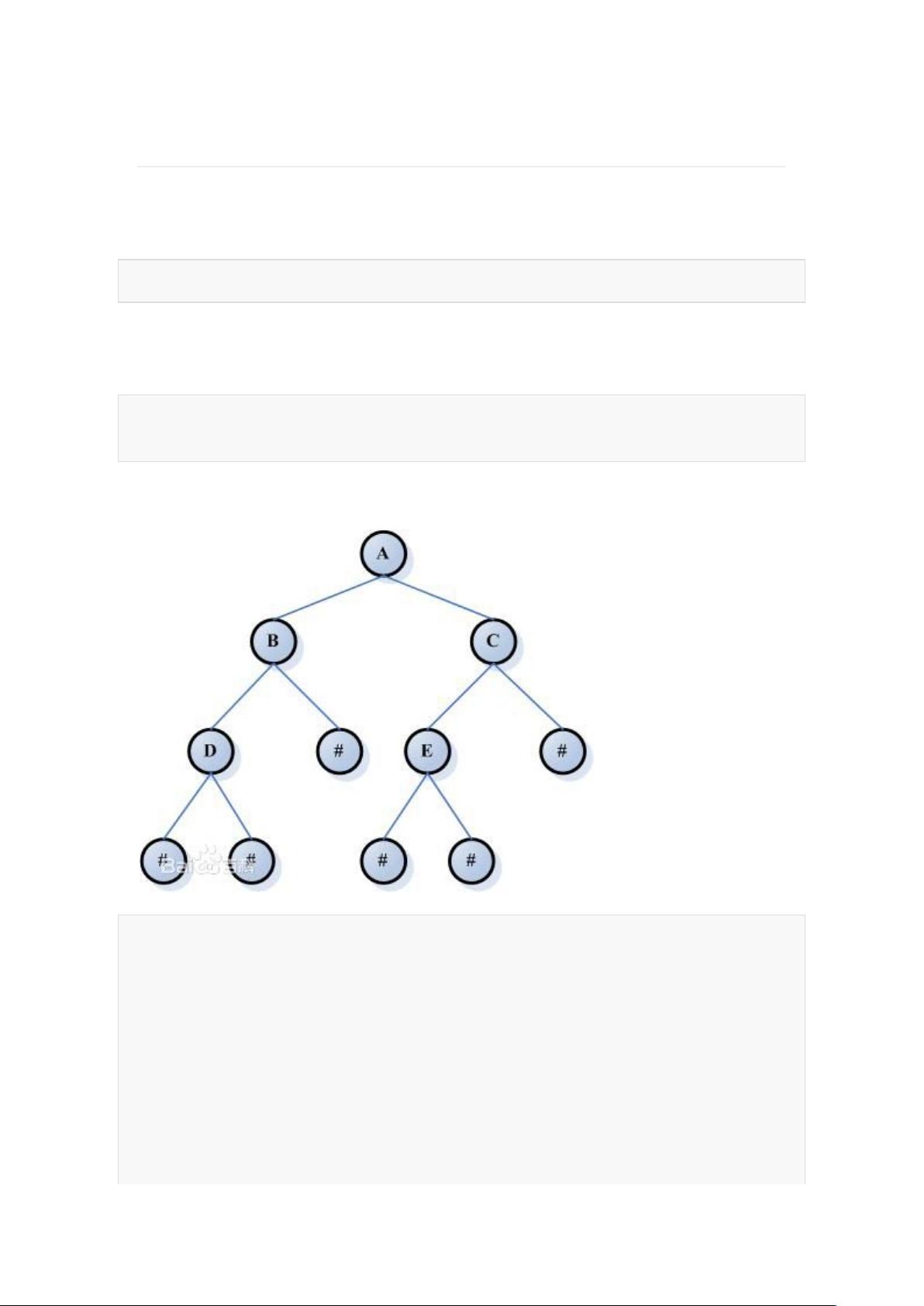
� 二叉树
在计算机科学中,二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子
树”(left subtree)和“右子
树”(right subtree)。
//二叉树节点
public class TreeNode {
public int value;
public int parent;
public TreeNode leftchild;
下载后可阅读完整内容,剩余4页未读,立即下载
2010-04-26 上传
2017-11-08 上传
2017-12-31 上传
2011-07-05 上传
2021-09-26 上传
2022-10-30 上传
2022-10-29 上传
2022-10-30 上传
2022-10-29 上传

小崔个人精进录
- 粉丝: 39
- 资源: 316
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
