超详细教程:Hadoop集群上的Hive安装与配置
版权申诉
"本文详细介绍了如何在Hadoop集群中配置和安装Hive,包括Hive的基本概念、作用以及其与Hadoop的关系。同时,提到了Hive的查询语言HQL,并阐述了Hive的工作原理,即如何将HQL转化为MapReduce任务进行执行。此外,还涉及了MySQL的安装过程,作为Hive可能依赖的元数据存储服务。
Hive是Apache Hadoop生态系统中的一个组件,由Facebook开源,主要用于处理和分析大量结构化的存储在Hadoop分布式文件系统(HDFS)上的数据。它提供了一种基于SQL的查询接口,使得具有SQL背景的用户可以方便地对大数据进行查询和分析,而无需深入理解MapReduce编程模型。Hive不仅支持标准的SQL查询,还允许开发人员自定义Mapper和Reducer,以应对复杂的数据分析需求。
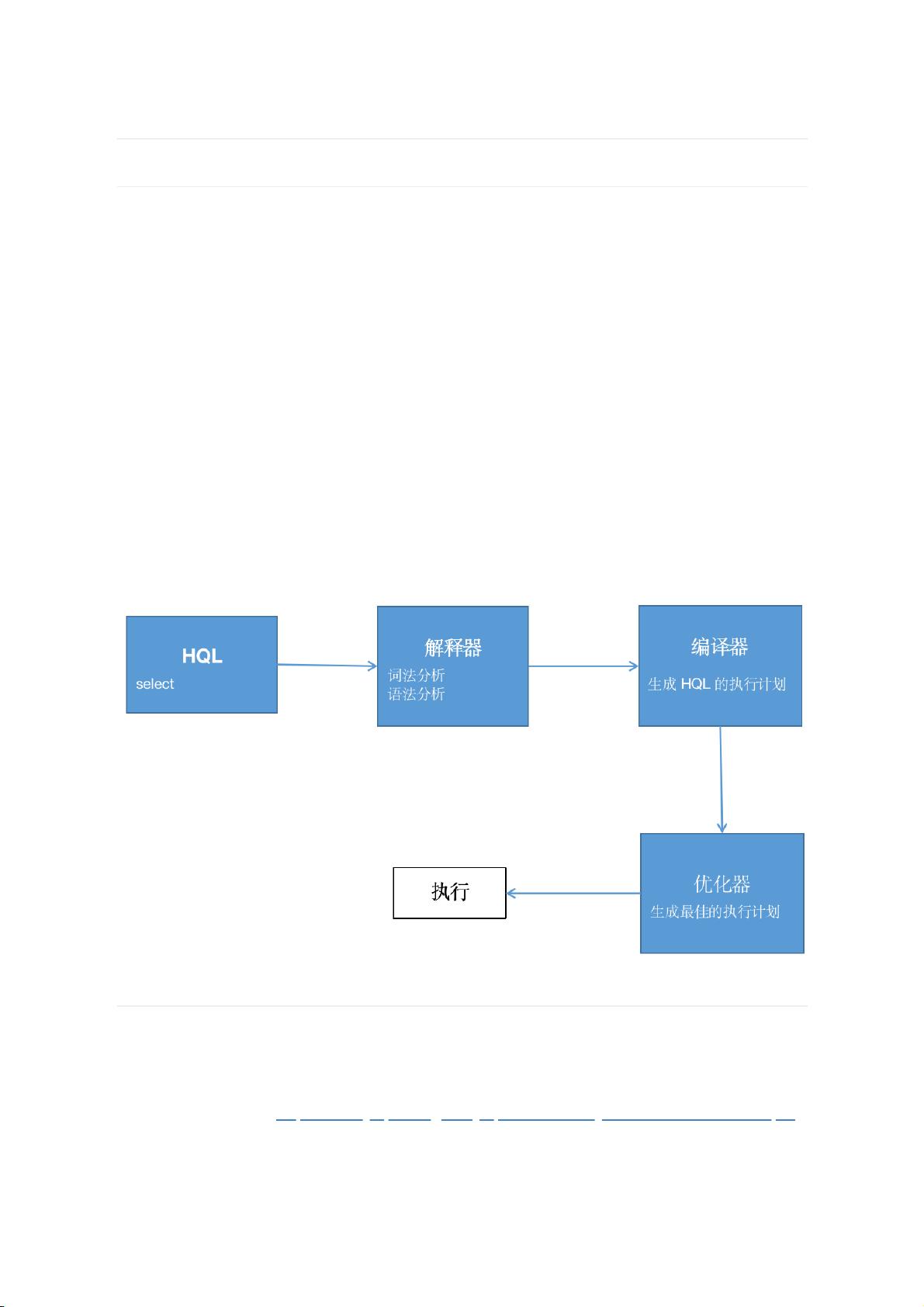
Hive的工作流程主要包括以下几个步骤:
1. 用户通过Hive的接口提交HQL查询。
2. 解释器接收到HQL后,进行词法分析和语法分析。
3. 编译器将HQL转换成执行计划,这个计划可能包含多个MapReduce任务。
4. 优化器对执行计划进行优化,比如选择最佳的JOIN策略、减少数据移动等。
5. 最终生成的MapReduce计划被写入HDFS,并由Hadoop集群执行。
在安装Hive之前,通常需要先安装MySQL作为元数据存储服务。MySQL的安装步骤如下:
1. 使用wget命令下载MySQL的RPM安装包。
2. 将安装包上传到Linux系统的指定目录。
3. 检查系统中是否已安装MySQL,如有则卸载。
4. 安装MySQL的YUM源。
5. 使用yum命令安装MySQL社区服务器。
6. 启动MySQL服务,并设置为开机启动。
在Hadoop集群中配置Hive时,需要考虑的方面包括:
- 配置Hive的 metastore,连接到MySQL服务存储元数据。
- 配置Hive的Hadoop相关参数,如HDFS的路径、Hadoop的配置文件位置等。
- 配置Hive的环境变量,确保所有节点都能访问到Hive的安装目录。
- 如果有多个Hive实例,还需要配置HiveServer2以支持多用户并发访问。
安装完成后,可以通过创建数据库、表,导入数据,然后执行HQL查询来验证Hive的配置是否成功。需要注意的是,Hive的性能受到Hadoop集群性能的影响,因此优化Hadoop集群的配置也能提高Hive的查询效率。
Hive是Hadoop生态中不可或缺的一部分,它简化了大数据分析的复杂性,使非程序员也能参与到大数据处理中。通过正确配置和使用Hive,可以在Hadoop上实现高效的数据仓库和分析功能。"
hHive
什么是Hive?
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是建立在Hadoop HDFS上的数据仓库基础架构。
Hive可以用来进行大规模的数据提取-转换-加载(ETL)。
Hive定义了简单的类似SQL查询语言,称为HQL。它允许熟悉SQL的用户进行查询数据。
Hive允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer来处理内建的mapper和
reducer无法完成的复杂的分析工作。
Hive是HQL解析引擎,它将HQL语句转换成M/R Job然后再Hadoop上执行。
Hive的表其实就是HDFS的目录(表)/文件(数据)
本质是:将HQL转化成MapReduce程序
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划
(Plan)的生成。生成的查询计划存储在HDFS中,并随后由MapReduce调用执行。
一条HQL在Hive中如何执行呢?
MySQL 安装
rpm安装包安装MySQL(推荐)
安装包准备
MySQL 下载地址:http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
1. 使用wget下载 rpm yum仓库。
下载后可阅读完整内容,剩余7页未读,立即下载
716 浏览量
505 浏览量
292 浏览量
183 浏览量
135 浏览量
117 浏览量

林中有神君
- 粉丝: 3779
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- wifi-channels:一个简单的python脚本,用于查看本地wifi信道使用情况与信号强度
- webpack-docker-example
- 主动记录介绍
- 医院物业管理方案
- Shark:Java中安全相关数据的抓包、分析和提取
- MediumPosts:记录我的学习,以便其他人可以减少苦苦挣扎
- my_app
- milktoz.github.io
- javaFx swing开发桌球小游戏项目(完整的项目,包含源码和素材)
- 灾害应对项目
- meteor-kouto-swiss:使用Kouto Swiss的完整的Meteor软件包,可与Stylus一起使用-CSS框架+ Jeet +破裂+轴+ AutoPrefixer + Nib +印刷
- clojure-db-pool
- 解决lxml没有etree的方法
- DefiTool.github.io:DefiTool.github.io
- LiME_binning
- pso两种MATLAB代码实现,MATLAB初学者教程
