跳表(Skip List)实现原理详解
需积分: 0 123 浏览量
更新于2024-08-04
收藏 219KB DOCX 举报
"跳表(Skip List)的实现原理和应用"
跳表是一种高效的数据结构,主要用来解决有序链表中查找特定值困难的问题。它的设计灵感来源于有序表,通过增加多级索引来加速查找过程,使得查找的时间复杂度降低到O(logn)。跳表在Redis和LevelDB等数据库系统中被广泛使用,因为它相比平衡树如B树、红黑树、AVL树等,实现起来更加简单,同时性能接近。
跳表的主要特点如下:
1. **多层结构**:跳表由多个层级(Level)组成,每一层都是一个链表,且从下至上,链表的长度逐渐减小。
2. **有序链表**:每个层级的链表都是有序的,即链表中的元素按某种顺序排列。
3. **全包含关系**:最底层(Level 1)的链表包含所有元素,而上层的链表包含下层链表的部分元素,但这些元素在下层链表中一定存在。
4. **指针结构**:每个节点包含两个或多个指针,一个指向同一层的下一个节点,另一个或多个指针指向下一层的节点。
5. **随机化构建**:跳表的层数和各层节点的选择是随机的,这使得在平均情况下,查找效率较高。
跳表的查找过程如下:
以查找元素117为例:
1. 从最高层开始,比较当前元素(这里是21),如果待查找的元素大于当前元素,则向下移动到下一层并继续比较。
2. 继续在下一层进行比较,直到找到大于等于目标元素的节点(例如在Level 2找到了50)。
3. 在找到的节点的下一层,从该节点开始向后遍历,直到找到目标元素或超过目标元素。
插入和删除操作也遵循类似的原则,根据新元素的位置在适当的层级插入新的节点,删除操作则需要找到待删除节点,并在所有层上进行相应的调整。
在实际应用中,跳表的构建和维护可以通过概率算法来优化,例如每次添加新元素时,通过抛硬币决定其应出现在哪些层级,以达到动态平衡的效果。这种方法使得跳表的平均性能接近于平衡树,而实现起来却相对简单。
总结来说,跳表是一种随机化、高效的查找数据结构,适合用于需要快速查找和操作有序数据的场景。由于其简单的实现和良好的性能,跳表在内存存储和数据库领域得到了广泛应用。
Skip list 的实现原理
最近看了一种数据结构叫做 skipList,redis 和 levelDB 都是用了它。Skip
List 是在有序链表的基础上进行了扩展,解决了有序链表结构查找特定
值困难的问题,查找特定值的时间复杂度为 O(logn),他是一种可以代
替平衡树的数据结构。
下面是 skipList 的一个介绍,转载来的,源地址:
http://kenby.iteye.com/blog/1187303,为防止源地址丢失,故拷贝一
份放在这里,望作者原谅。
———————————————转载开始
—————————————————
为什么选择跳表
目前经常使用的平衡数据结构有:B 树,红黑树,AVL 树,Splay Tree, Treep 等。
想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者 AVL
树
出来吗? 很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,
还要参考网上的代码,相当麻烦。
用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,
它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,
就能轻松实现一个 SkipList。
有序表的搜索
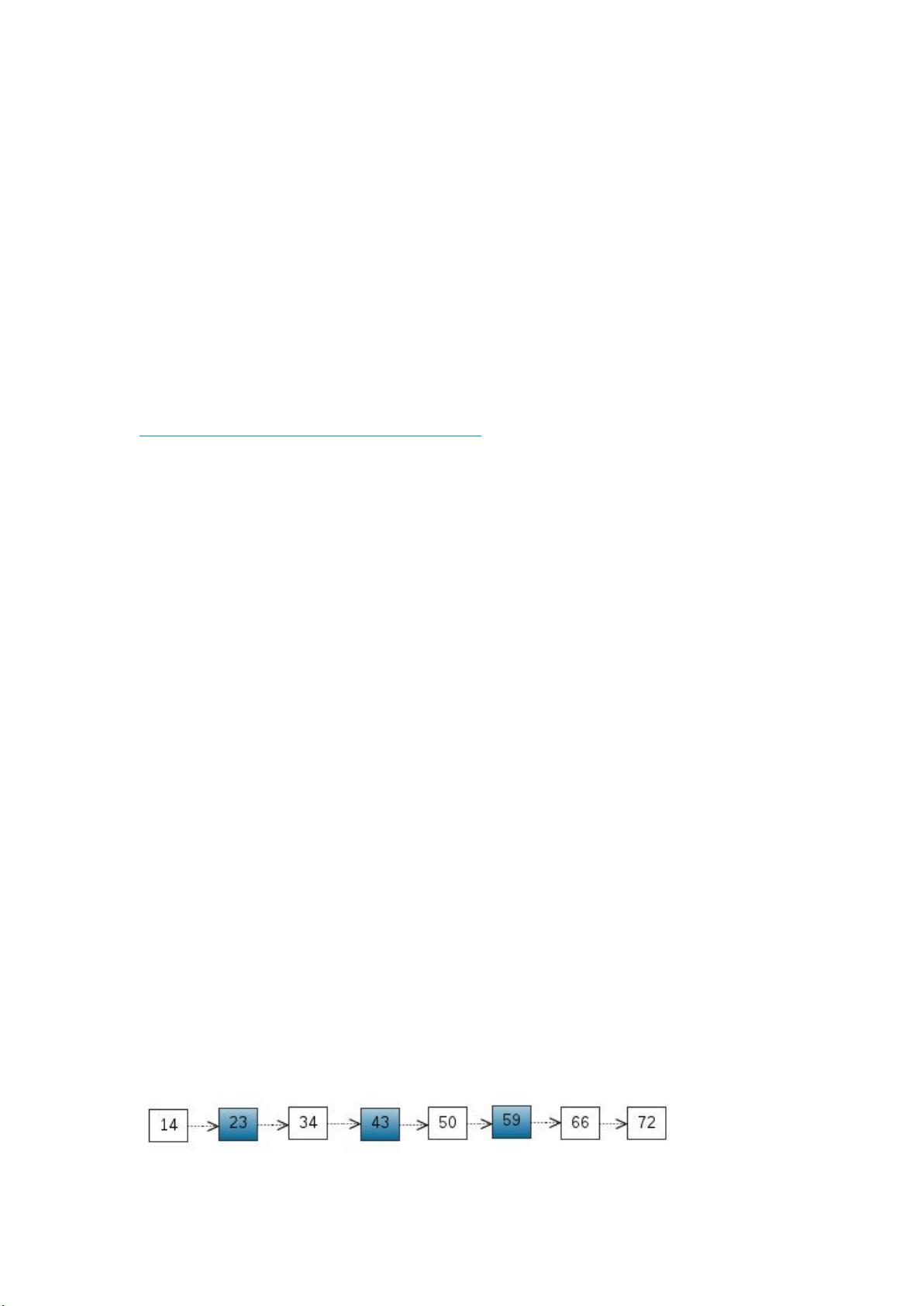
考虑一个有序表:
下载后可阅读完整内容,剩余9页未读,立即下载
2016-03-04 上传
2019-08-14 上传
2022-09-23 上传
174 浏览量
2019-07-26 上传
2020-12-17 上传
2024-06-04 上传
2019-12-12 上传
2021-08-12 上传

一曲歌长安
- 粉丝: 870
- 资源: 302
 我的内容管理
展开
我的内容管理
展开







最新资源
- getting started with JBoss4.0 中文版
- SQL语法大全中文版(其中两章)
- 开源_200903.pdf
- C语言趣味程序百例精解
- 动态场景下的运动目标跟踪方法研究.pdf
- 英语词根词缀记忆大全
- DS1302_中文资料.pdf
- How to solve it: A new aspect of mathematical method
- 美国MIT EECS系本科生课程设置简介
- 小程序(在网页上找Email地址)
- C#完全手册(新手学习C#必备手册)
- 数字信号处理、计算、程序、
- 详细设计说明书案例.DOC
- 课程设计航空客运订票系统
- JSF自定义组件 JSF自定义组件
- Visual C++与Matlab混合编程
