快速掌握Apache Spark:7步学习指南
需积分: 10 60 浏览量
更新于2024-07-19
1
收藏 4.62MB PDF 举报
Apache Spark是一个强大的开源大数据处理框架,以其高效、易用性和处理大规模数据的能力而著称。它最初由加州大学伯克利分校的AMPLab在2009年开发,随后在2010年成为了Apache软件基金会的一部分。本文档提供了7个步骤,旨在帮助开发者快速入门Apache Spark,以便节省学习时间并理解其核心概念和技术。
步骤1:了解基础知识
首先,熟悉Spark架构,包括它的分布式计算模型(RDDs、DataFrames和Datasets),以及其主要组件,如Spark Core、Spark SQL、Spark Streaming和MLlib等。理解Spark的运行原理,即基于内存计算,能够显著提高数据处理速度。
步骤2:安装与配置
掌握如何在本地或集群环境中安装Spark,并配置环境变量和配置文件。了解不同部署模式(standalone、Spark on YARN、Kubernetes等)的选择依据。
步骤3:创建和操作RDDs
学习如何创建Resilient Distributed Datasets (RDDs),这是Spark的基础数据结构,可以进行各种转换和操作。通过实例了解map、filter、reduce等操作在实际场景中的应用。
步骤4:探索DataFrame API
DataFrame是Spark 1.0以后引入的重要特性,它是SQL查询的一种高效表示形式。理解DataFrame的概念,学习如何使用Spark SQL和DataFrame API进行数据处理和查询,包括连接、聚合和分组等操作。
步骤5:实时流处理
Spark Streaming提供了对实时数据流的处理能力。学习如何设置流接收器,定义滑动窗口和处理逻辑,实现实时数据的处理和分析。
步骤6:机器学习和深度学习
了解MLlib库,这是Spark的机器学习模块,涵盖了分类、回归、聚类和协同过滤等功能。学习如何构建模型,评估性能,以及将模型部署到生产环境。
步骤7:实战项目与最佳实践
最后,通过实践项目来巩固所学知识,比如构建一个简单的推荐系统或数据分析应用。同时,关注Databricks社区分享的最佳实践和优化技巧,以便更好地利用Spark的优势。
总结:
通过这7个步骤,开发者可以系统地掌握Apache Spark的基本技能,从底层API到高级功能,从单机到集群部署,再到数据流处理和机器学习。掌握这些知识后,不仅能够高效地处理大数据,还能在实际工作中快速解决复杂的数据分析问题。
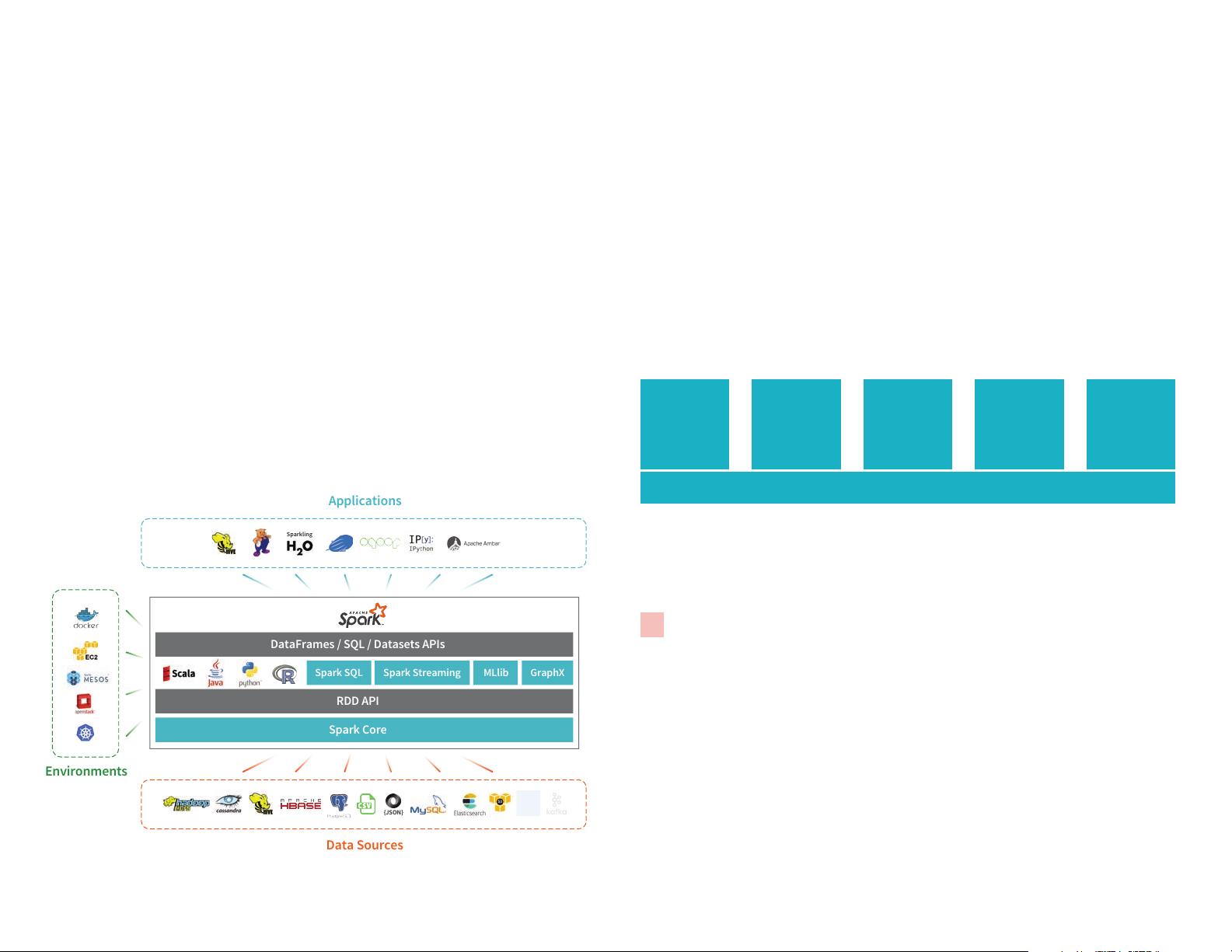
Why Apache Spark?
!
For one, Apache Spark is the most active open source data processing
engine built for speed, ease of use, and advanced analytics, with over
1000+ contributors from over 250 organizations and a growing
community of developers and adopters and users. Second, as a
general purpose fast compute engine designed for distributed data
processing at scale, Spark supports multiple workloads through a
unified engine comprised of Spark components as libraries accessible
via unified APIs in popular programing languages, including Scala,
Java, Python, and R. And finally, it can be deployed in different
environments, read data from various data sources, and interact with
myriad applications.
All together, this unified compute engine makes Spark an ideal
environment for diverse workloads—traditional and streaming ETL,
interactive or ad-hoc queries (Spark SQL), advanced analytics
(Machine Learning), graph processing (GraphX/GraphFrames), and
Streaming (Structured Streaming)—all running within the same
engine.
In the subsequent steps, you will get an introduction to some of these
components, from a developer’s perspective, but first let’s capture key
concepts and key terms.
Why Apache Spark?
6
Spark Core Engine
Spark
SQL
Spark
Streaming
Streaming
MLlib
Machine
Learning
GraphX
Graph
Computation
Spark R
R on Spark
Spark Core Engine
Spark
SQL
Spark
Streaming
Streaming
MLlib
Machine
Learning
GraphX
Graph
Computation
Spark R
R on Spark
Environments
Applications
Data Sources
DataFrames / SQL / Datasets APIs
RDD API
Spark Core
Spark SQL Spark Streaming MLlib GraphX
S3
{JSON}
Sparkling
剩余29页未读,继续阅读
2018-11-26 上传
2017-11-12 上传
2024-07-18 上传
2023-08-03 上传
2023-08-26 上传
2018-11-02 上传
点击了解资源详情

song_zhanlong
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
