Transformer模型深度解析:从NLP到CV的革命
92 浏览量
更新于2024-06-27
22
收藏 17.48MB PPTX 举报
"Transformer深度讲解,进一步给出其在NLP和CV下的发展,共95页ppt,全网最好的讲解,没有之一"
Transformer模型是由Vaswani等人在2017年提出的,其核心思想在于引入了注意力机制,彻底改变了序列到序列(seq2seq)模型的设计。在传统的RNN或LSTM模型中,信息传递存在时序依赖,而Transformer通过自注意力(Self-Attention)机制消除了这种依赖,使得并行计算成为可能,大大提高了训练效率。
Transformer模型由以下几个关键部分组成:
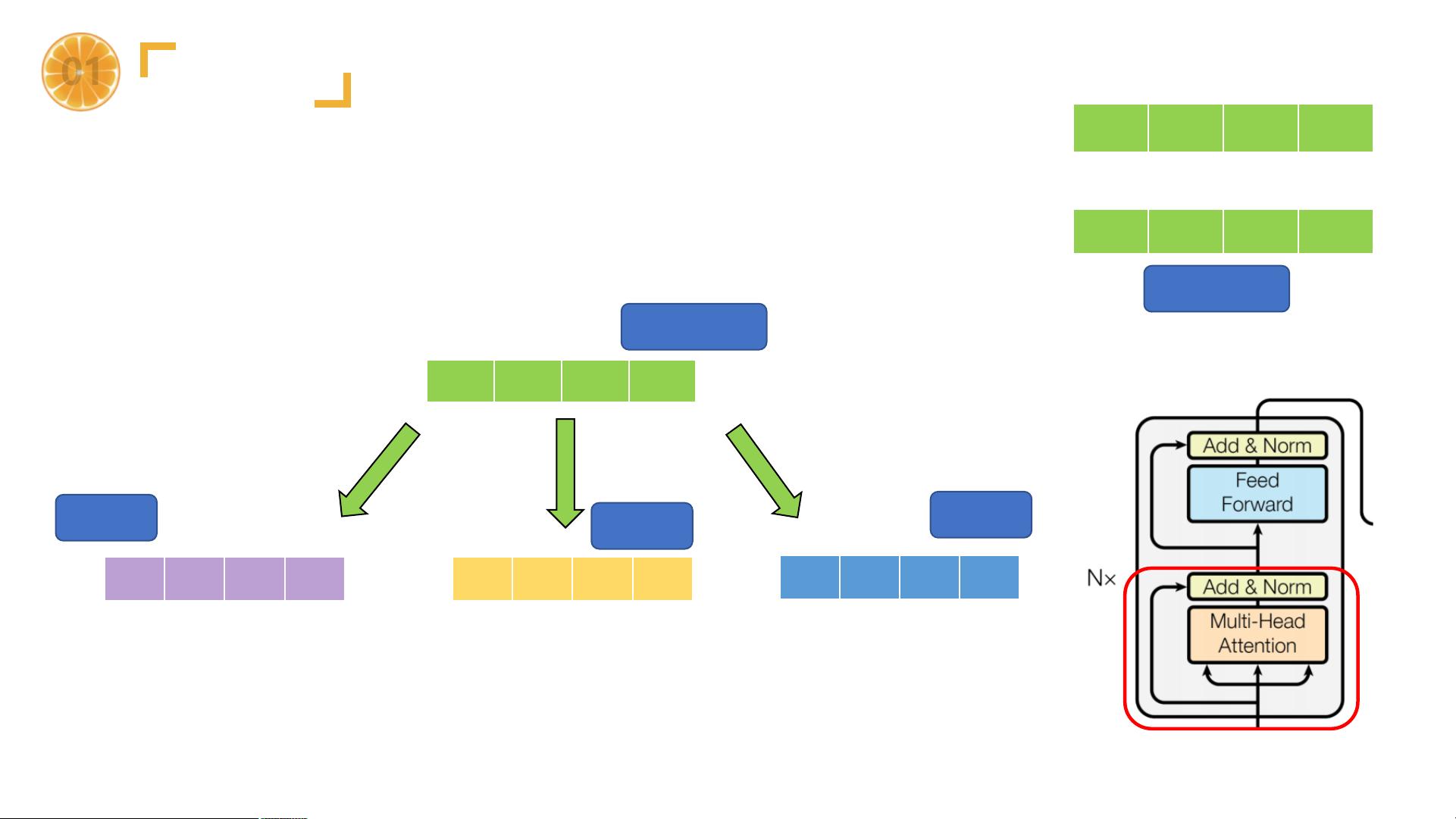
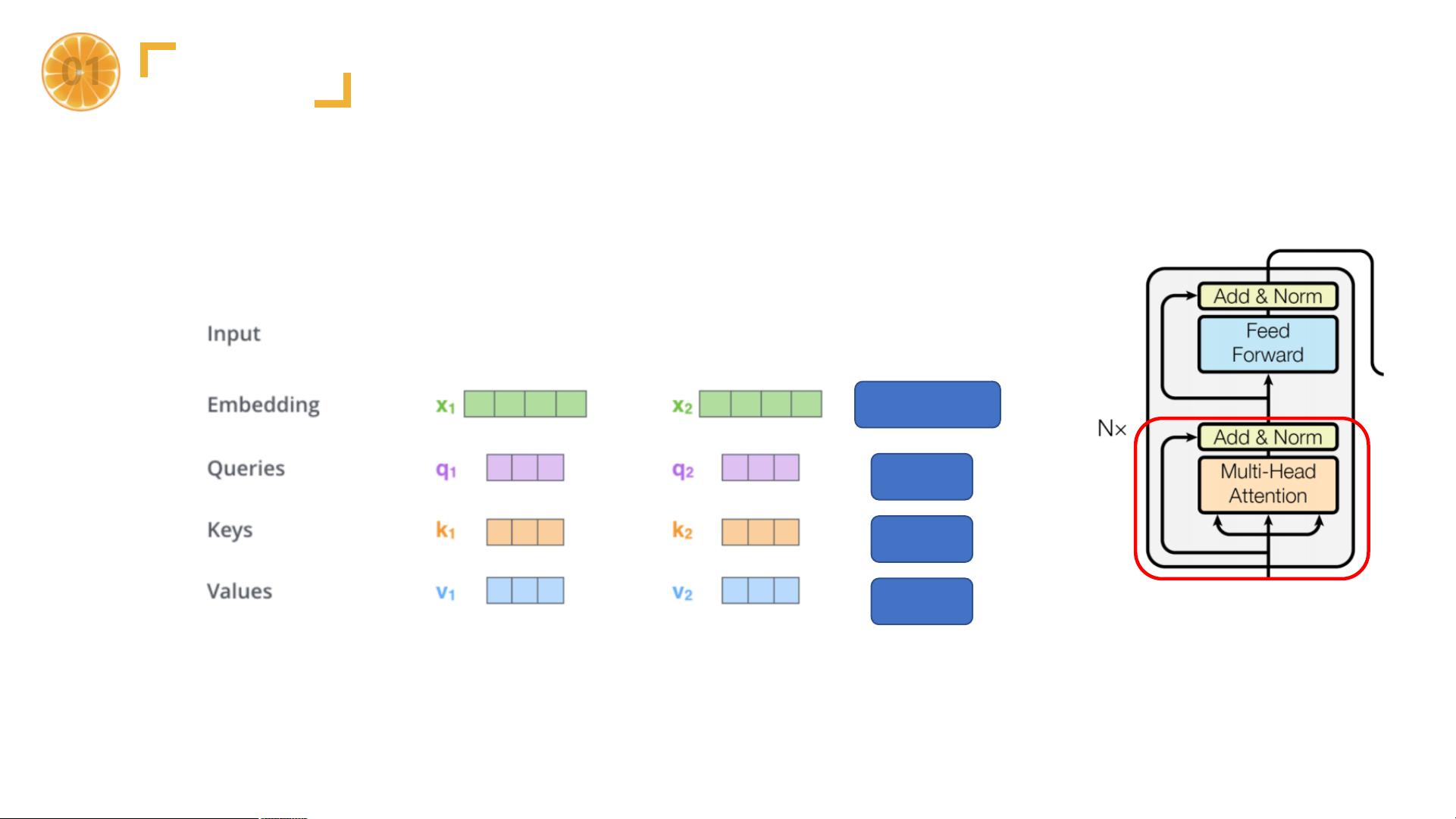
1. 输入部分:包括源文本嵌入层和位置编码器。源文本和目标文本的单词被转换为向量表示,位置编码则用来保留序列信息,因为纯基于注意力的模型无法内建顺序信息。
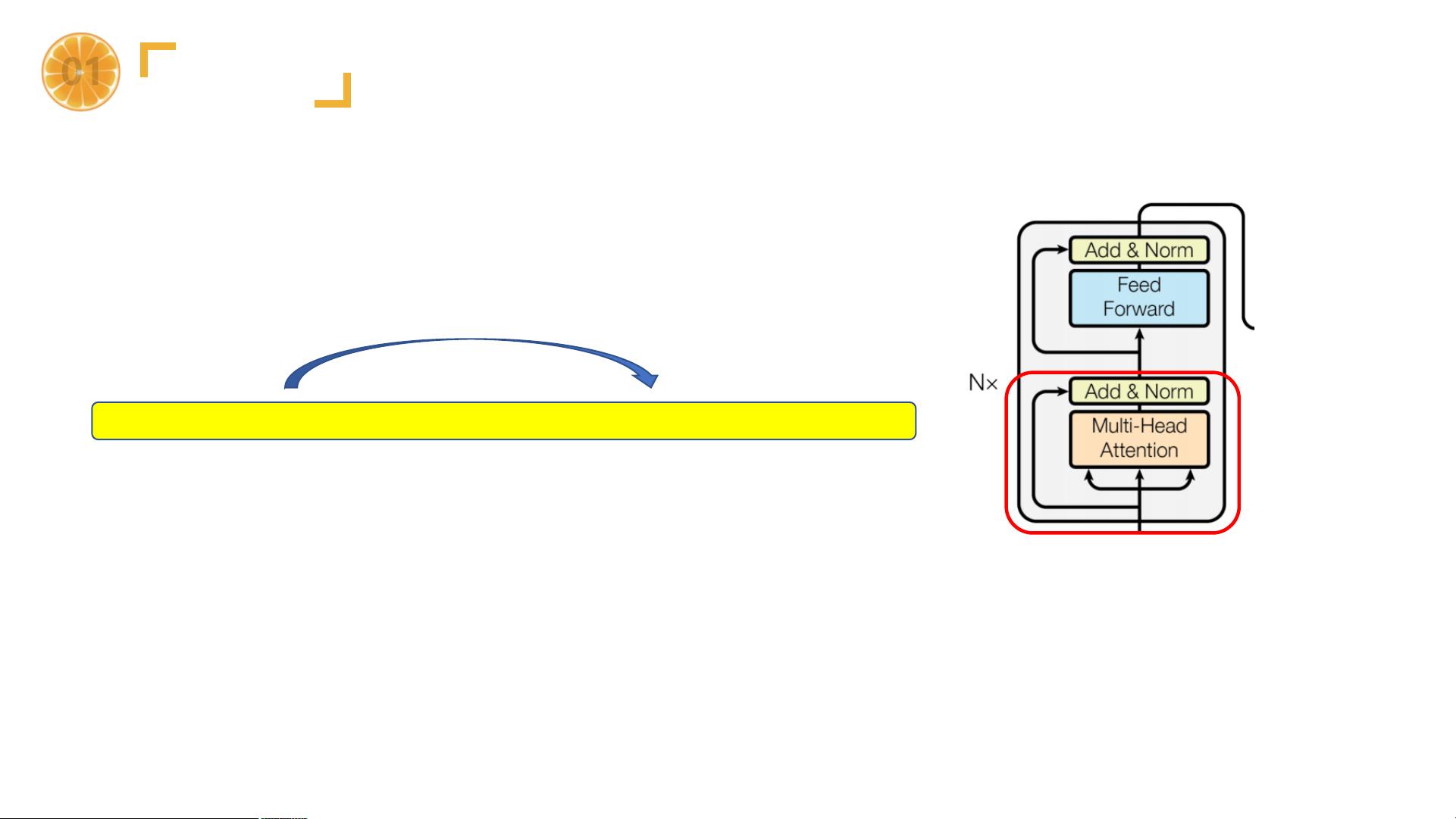
2. 编码器:由多个相同的编码器层堆叠而成,每个编码器层包含多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Network)。自注意力允许模型在处理序列中的每一个元素时,考虑全局的信息。
3. 解码器:同样由多个相同的解码器层组成,每个解码器层包含自注意力、编码器-解码器注意力以及前馈神经网络。解码器在编码器的基础上增加了掩蔽操作,防止了目标序列的未来信息泄露,保证了预测的顺序性。
4. 输出部分:经过解码器处理后的信息会通过一个线性层和softmax函数转换为概率分布,用于预测下一个词或执行其他任务。
Transformer的成功不仅限于NLP领域,它也逐渐被应用到计算机视觉(CV)任务中。例如,ViT(Vision Transformer)将图像切割为固定大小的patches,然后将这些patches转化为向量,用Transformer进行处理,开创了Transformer在CV领域的应用先河。此外,GPT系列(GPT-1, GPT-2, GPT-3)和BERT等预训练模型的出现,极大地推动了NLP的发展,它们利用Transformer架构进行大规模的无监督学习,然后在各种NLP任务上进行微调,取得了显著的效果。
最近,InstructGPT和ChatGPT展示了Transformer模型在对话理解和生成方面的巨大潜力,它们能更好地理解和遵循用户指令,提供更加自然的人机交互体验。同时,Diffusion Model和DALL-E(包括DALL-E-1和DALL-E-2)展示了Transformer在图像生成领域的强大能力,结合CLIP和DALL-E技术,Transformer不仅能够理解文本,还能生成高质量的图像。
总结来说,Transformer模型以其独特的注意力机制和模块化设计,彻底改变了深度学习在NLP和CV领域的实践。从最初的机器翻译任务到现在的文本生成、图像理解甚至对话交互,Transformer已经成为最先进AI技术的核心组成部分,持续推动着人工智能的进步。

2023-06-15 上传
2021-04-22 上传
2024-06-18 上传
2024-06-11 上传
2024-01-22 上传
2022-04-21 上传
点击了解资源详情
2022-04-23 上传

小怪兽会微笑
- 粉丝: 2w+
- 资源: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
