Hadoop在异常检测与相似度计算中的应用优化
"Hadoop在相似度计算中的优化_林述民"
本文主要探讨了Hadoop在相似度计算中的优化,特别是在互联网广告反作弊场景下的应用。作者林述民提到了广告行业的常见结算方式,如CPD、CPM、CPC、CPA和CPS,并指出反作弊的核心是异常检测。在广告业务中,识别异常行为对于防止作弊至关重要。
异常检测面临着六个挑战,包括正常行为的定义、恶意行为的快速适应性、正常行为的演变、不同领域的要求差异、充足且平衡的标注数据需求以及噪声数据的影响。异常类型分为点异常、上下文异常和组合异常,它们分别基于剩余数据、特定上下文和整个数据集来定义。
在反作弊技术方法中,作者列举了几种常见的策略,如分类、聚类、密度检验、假设检验、信息论方法和降维处理。这些方法在处理大量数据时,尤其是在Hadoop这样的分布式计算框架下,显得尤为重要。
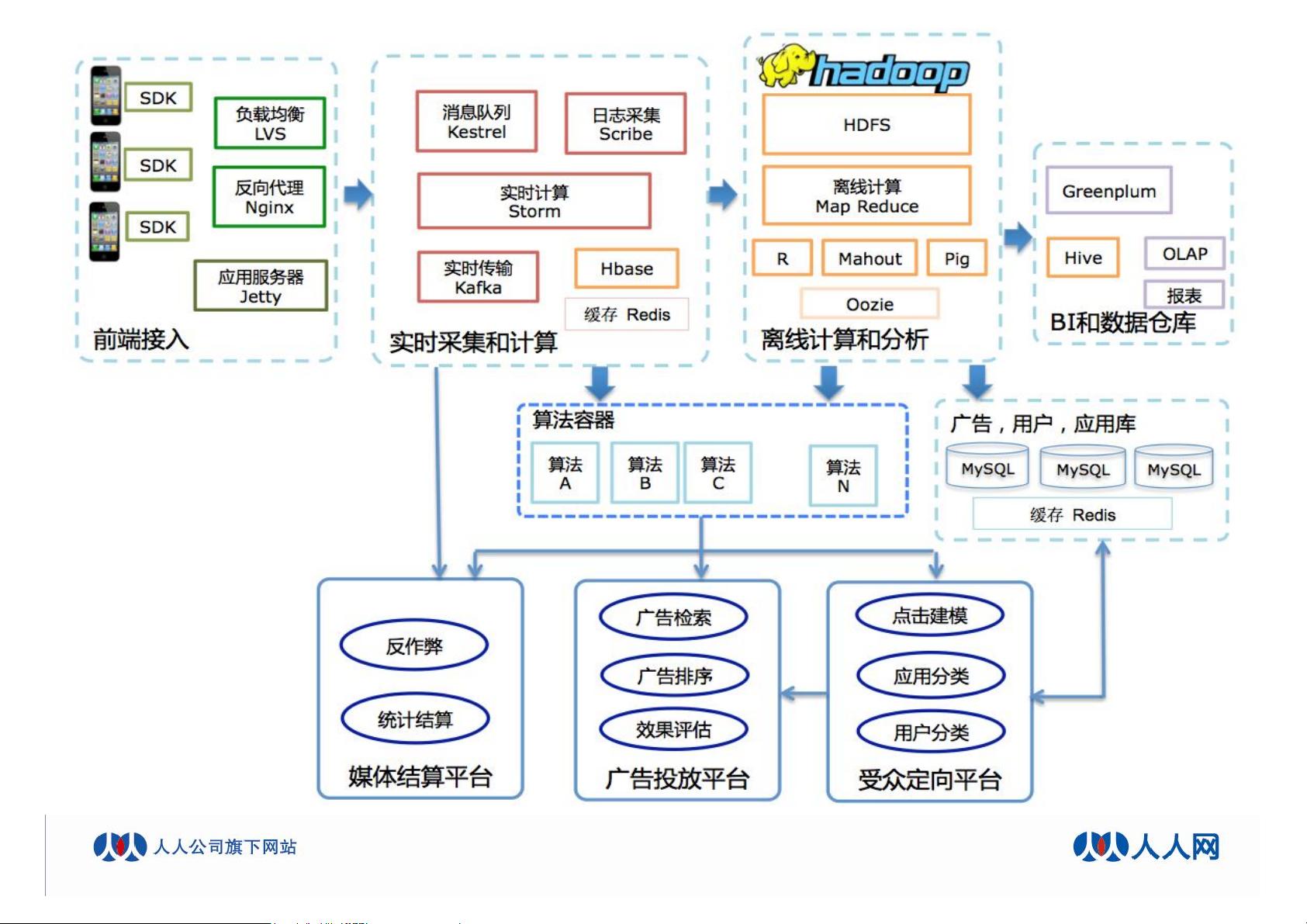
文章以一个具体的案例展示了如何利用Hadoop MapReduce计算用户相似度。在用户行为分析的场景下,用户喜欢的应用(Apps)可以作为特征,通过计算用户间的相似度矩阵来识别用户群体的行为模式。例如,用户U1对F1、F2、F3和F4四个应用的喜好程度可以通过某种相似度算法(如余弦相似度或Jaccard相似度)进行量化,从而找出具有相似兴趣的用户。
在实际操作中,这些用户行为数据可能会存储在HBase这样的NoSQL数据库中,经过MapReduce处理后生成中间结果,进一步计算得到用户相似度矩阵,最终存储在HDFS上。此外,用户画像(User Profile)等信息可能也参与到相似度计算中,以提升分析的准确性。最后,这些结果会被用于生成报告,帮助决策者了解用户行为并识别潜在的异常行为,以防止广告作弊。
总结来说,Hadoop在相似度计算中的优化对于大规模数据处理和异常检测至关重要,尤其在互联网广告反作弊领域。通过利用分布式计算的优势,可以高效地处理和分析海量用户行为数据,有效地识别异常,从而保障广告系统的公正性和安全性。
反作弊常用的技术方法
方法名称
1 分类(Classification)
2 聚类(Clustering)
3 密度检验(Nearest Neighborhood)
4 假设检验(Statistical)
5 信息论方法(Information Theoretic)
6 降维处理(Spectral)
剩余30页未读,继续阅读
2013-06-11 上传
2022-03-20 上传
2022-09-23 上传
2022-09-14 上传
2022-06-10 上传
点击了解资源详情
2019-03-28 上传
2022-09-24 上传
2014-09-22 上传

manyi100
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | python-gitlab-0.14.tar.gz
- bmed-4460-6460:生物图像分析课程的源代码(BMED 44606460)
- rpgit-system:rpgit系统
- ListBox.zip源码Labview个人项目资料程序资源下载
- sympathetic-synth:交感合成器系统Mk1
- launch-extension-context-data-tools:提供操作和一些工具,使您可以使用contextData变量进行跟踪
- Look4:基于MVI,附近连接API和Hilt的约会应用
- TWB:TWB 网络应用程序
- fps沙箱
- Python库 | python-ftx-0.1.0.tar.gz
- GenGen:通用的世代系统
- 感言
- lunchlady:一个基于NodeJS的愚蠢,简单的无后端CMS
- 资源fastjson-get-post.zip
- sssnap-api:已弃用 - 用于 sssnap 的 REST JSON API
- Excel模板开票申请单模板.zip
