HBase实战:RowKey设计与索引优化解析
版权申诉
196 浏览量
更新于2024-07-07
收藏 4.09MB PDF 举报
“HBase 实战经验分享.pdf”
在大数据领域,HBase作为一种分布式列式数据库,因其高扩展性、实时读写以及强大的大数据处理能力而备受关注。本资料主要涵盖了HBase的基础知识、需求调研、RowKey与索引设计以及实际应用案例,旨在帮助开发者更好地理解和运用HBase。
首先,HBase的基础概念是理解其工作原理的关键。HBase的数据模型基于KeyValue,每个单元格由RowKey、ColumnFamily和Timestamp三部分组成。RowKey是表中数据的唯一标识,它决定了数据在Region中的分布。Region是表的逻辑分区,随着数据量的增长,Region会自动分裂以保持性能。RegionServer是提供数据服务的进程,负责处理客户端请求,每个Region必须在其上运行才能提供读写服务。MemStore是RegionServer内存中的缓存,用于临时存储数据,达到一定大小后会写入持久化的HFile。HFile是HBase在底层分布式文件系统(如HDFS)上的数据存储格式,是有序的且支持高效的随机读取。
在需求调研阶段,设计者需要明确设计目标,了解负载特点、查询场景以及数据特点。这包括对数据规模的预估、数据访问模式的分析以及对数据生命周期的考虑,以便做出合理的设计决策。
RowKey与索引设计是HBase性能优化的核心。RowKey设计原则通常要求它具有较高的区分度,以便于快速定位数据。RowKey的长度和排序方式都会影响到数据分布和查询效率。二级索引可以在某些特定场景下提高查询性能,但需要注意其带来的额外存储和维护成本。组合索引设计则是在多个字段上创建索引,以满足多维度查询需求。
在设计案例分享部分,资料可能会提到OpenTSDB、JanusGraph和GeoMesa等具体应用场景。OpenTSDB是一个时序数据库,适合存储大量的时间序列数据;JanusGraph是一个图数据库,适用于复杂关系的查询;GeoMesa则是一个地理空间数据存储,能够处理地理位置信息。
这份HBase实战经验分享深入浅出地介绍了HBase的基本概念、系统架构、设计原则和实际应用,对于开发者来说是一份宝贵的参考资料,有助于提升在大数据环境下的数据存储和处理能力。通过学习这些内容,开发者可以更好地理解如何利用HBase解决大数据场景下的问题,进行高效的数据建模和优化。
Column Family
00001
00002
00003
00004
……...
99999
{Name->Lily}
{Name->Siky}
{Name->Lina}
{Name->Susan}
{Name->……..}
{Name->Jane}
{City->GuangZhou}
{City->ShenZhen}
{City->Shanghai}
{City->JiNan} {City-
>………..} {City-
>XiaMen}
{Phone->13333333333}
{Phone->13423333222}
{Phone->13322222222}
{Phone->14233884444}
{Ph one-> ……………..}
{Phone->18666666666}
{Gender->Male}
{Gender->Female}
{Gender->Male}
{Gender->Male}
{Gender->……}
{Gender->Male}
Column Family - A
MemStore
Column Family - B
MemStore
HFile HFile HFile HFile
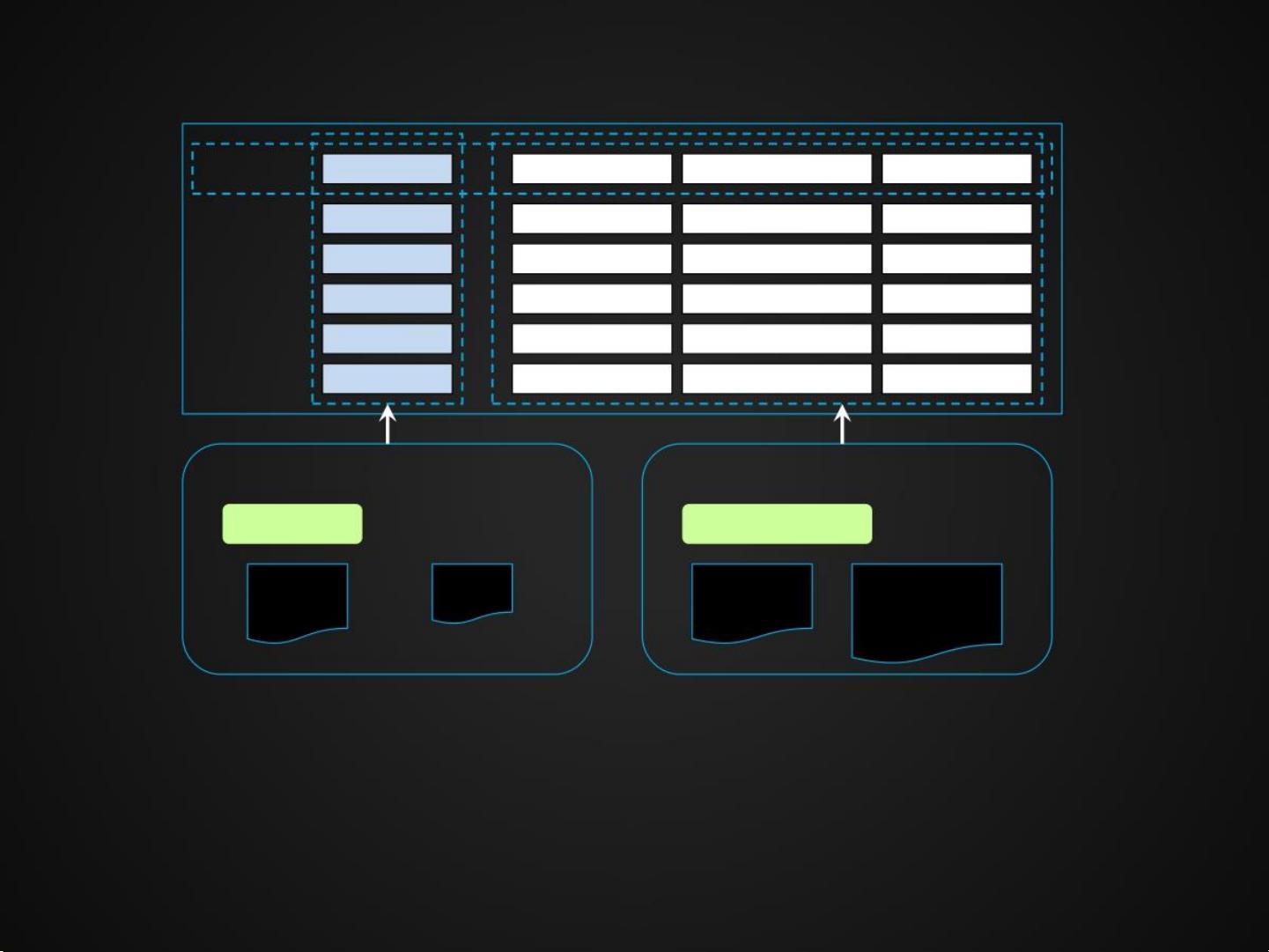
假设为表设置了两个列族,而且,定义了每一个列族中要存放的列,如左图所示:
{Name} -> Column Fam ily-A, {City, Phone, Gender} -> Column Family-B
不同列族的数据会被存储在不同的路径中。即,设置多个列族时一行数据可能存在于两个路径中。
整行读取的时候,需要将两个路径中的数据合并在一起才可以获取到完整的一行记录。但如果仅
仅读取Name一列的话,只需要读取Column Family-A即可。
11

剩余58页未读,继续阅读
2019-08-29 上传
点击了解资源详情
2023-06-27 上传
2017-11-12 上传
2018-03-14 上传
2021-08-24 上传


智慧化智能化数字化方案
- 粉丝: 1420
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- NetDocuments-crx插件
- 更丰富:TypeScript后端框架专注于开发效率,使用专用的反射库来帮助您愉快地创建健壮,安全和快速的API
- bianma.rar_Java编程_Java_
- 简单的editActionsForRowAt功能,写在SWIFTUI上-Swift开发
- 反弹:抛出异常时立即获取堆栈溢出结果的命令行工具
- zap-android:专注于用户体验和易用性的原生android闪电钱包:high_voltage:
- Doc:文献资料
- KobayashiFumiaki
- naapurivahti:赫尔辛基大学课程数据库应用程序项目
- Cura:在Uranium框架之上构建的3D打印机切片GUI
- SwiftUI中的倒计时影片混乱-Swift开发
- Example10.rar_串口编程_Visual_C++_
- GeraIFRelatorio:GeraIFRelatorio项目-自动化以帮助在Eclipse引擎上开发的Cobol语言项目编码
- CyberArk Identity Browser Extension-crx插件
- 智能汽车竞赛:完全模型组学习软件资源
- 键盘:在Windows和Linux上挂钩并模拟全局键盘事件
