Akka实战指南:构建高可用分布式系统
"Akka in Action" 是一本深入讲解使用Akka构建消息驱动系统的实战教程,由Manning Early Access Program出版,适用于第13版。本书专为Scala开发者设计,旨在简化开发并发分布式应用的过程。Akka的核心是Actor模型,它基于独立执行的进程通过消息传递进行通信,从而实现高度容错的应用,即使单个Actor失败也不会导致整个系统崩溃。Akka特别适合处理高流量、需要快速扩展的场景,无论是多核处理器还是服务器节点都能提供高效的可伸缩解决方案。
书中的章节结构详细且实用,分为17部分:
1. **入门**:介绍Akka的基本概念和原理,帮助读者建立起对Actor模型的理解。
2. **上手操作**:引导读者通过实践快速掌握Akka,每个新概念都配以实例演示,包括代码实现和单元测试。
3. **测试与Actor系统**:学习如何测试和部署Actor系统,以及如何利用Akka的故障 tolerance特性。
4. **Futures**:探索异步编程在Akka中的应用,理解如何利用Futures处理并发任务。
5. **首个分布式应用**:搭建和扩展第一个分布式Akka应用。
6. **配置、日志和部署**:讲解如何设置和管理Akka的配置,以及日志记录和部署策略。
7. **系统架构**:探讨系统组织结构和组件之间的交互。
8. **路由**:理解如何在大型系统中有效地路由消息。
9. **消息通道**:深入研究不同类型的消息通道和其在系统中的作用。
10. **有限状态机和代理**:学习如何使用这些抽象来设计复杂的行为。
11. **事务处理**:理解事务在Actor模型中的应用,确保数据一致性。
12. **集成**:探讨与其他技术的集成,如数据库和APIs。
13. **集群**:实现Akka集群,提高系统的可用性和可扩展性。
14. **Akka Persistence**:了解持久化机制,确保数据持久化和恢复。
15. **性能分析与调优**:学习如何分析和优化Akka应用的性能。
阅读这本书,读者不仅能掌握Akka的实战技能,还能学习到如何设计健壮的事件驱动系统,以及如何在实践中应用如Event Sourcing和CQRS等模式。此外,书中还提供了版权信息和读者评论渠道,鼓励反馈以提升书籍质量。通过本书,读者将建立起坚实的Akka开发基础,并有能力构建高效、弹性、可扩展的分布式应用。

1.
2.
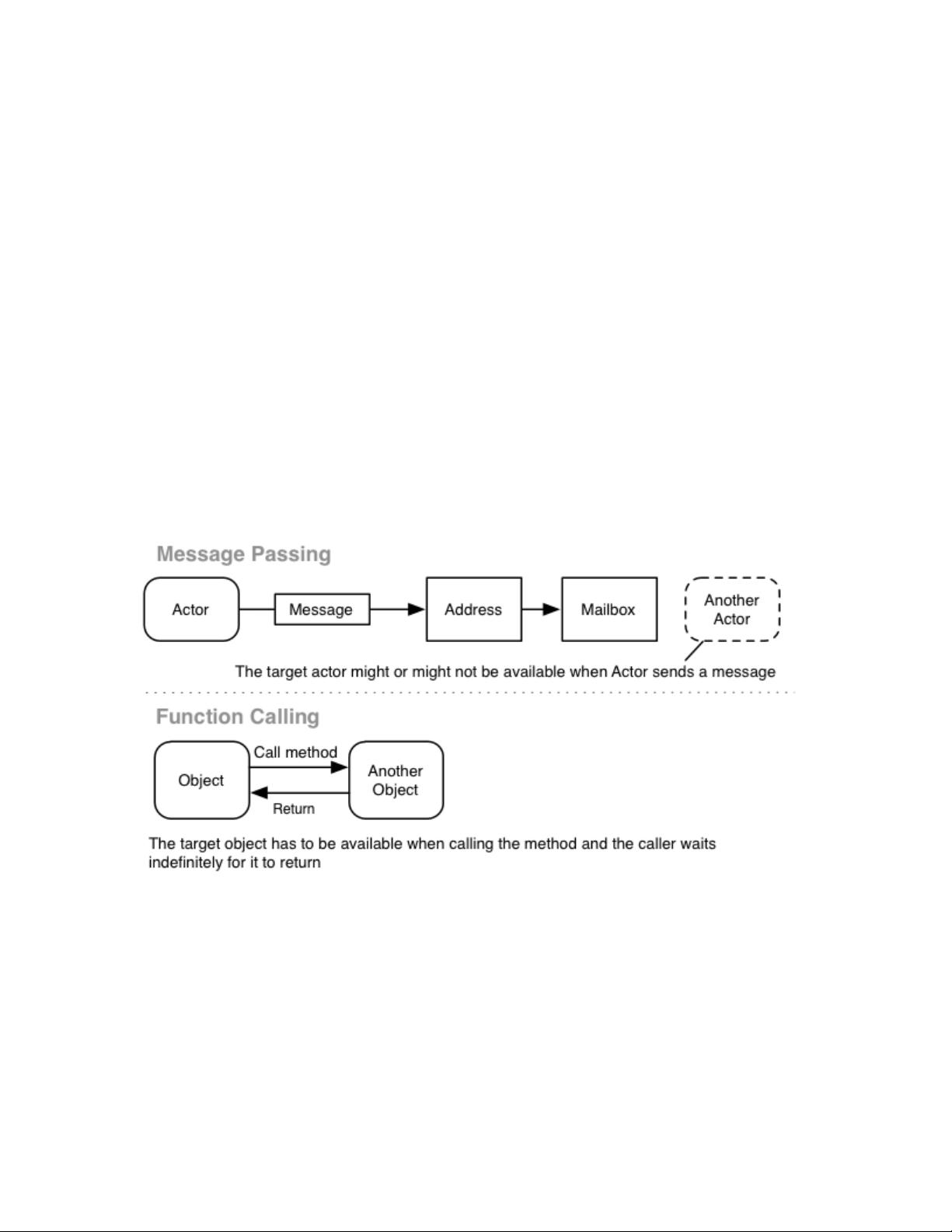
So are there no concurrency primitives like locks used in Akka? Well, ofat all
course there are, it's just that don't have to deal with them . Everythingyou directly
still eventually runs on threads and low level concurrency primitives. Akka uses
the java.util.concurrent library to coordinate message processing and takes great
care to minimize the number of locks used to an absolute bare minimum. It uses
lock free and wait free algorithms where possible, for example compare-and-swap
(CAS) techniques, which are beyond the scope of this book. And because nothing
can be shared between actors, the shared locks that you would normally have
between objects are not present at all. But as we will see later, we can still get into
some trouble if we accidentally share state.
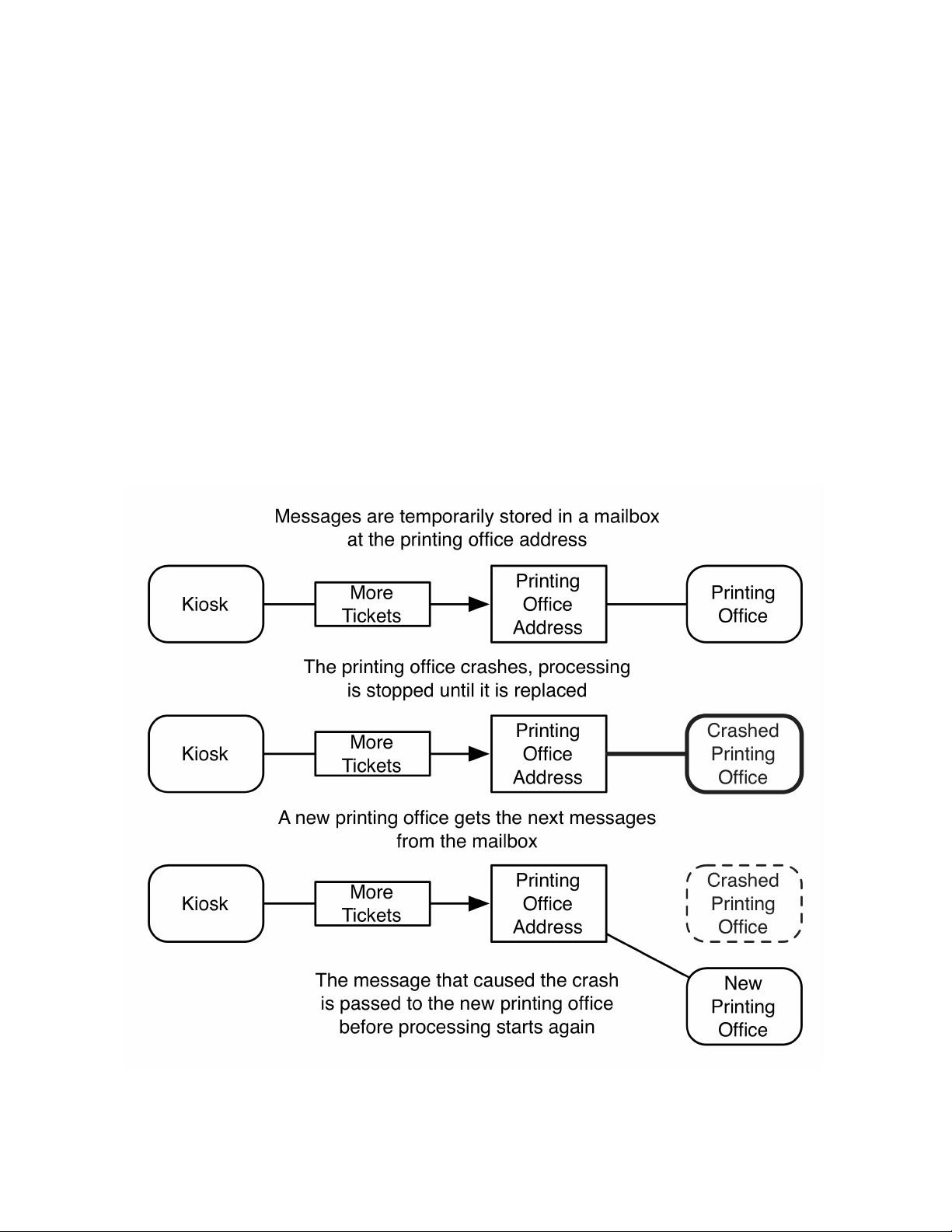
We also saw that in the message passing approach we needed to find a way to
redistribute the tickets. We had to model the application differently, which is what
you would probably expect, no such thing as a free lunch. But the advantage is that
we have traded unknown, perhaps vast amounts of work in scaling and preventing
disasters, for a few amendments to the interactions of the core collaborators, in this
case, simply distributing the load (as tickets to be sold). Later in the book, we will
see that having load accommodations in the domain layer will be beneficial when
we want to scale, as we have already provided a means of spreading the work
around to make use of additional resources.
There are other benefits that stem from the message passing approach that Akka
uses, which we will discuss in the next sections. We have touched on them briefly
already:
Even in this first, simple example, the message passing approach is clearly more fault
tolerant, averting catastrophic failure if one component (no matter how key) fails.
The shared mutable state is always in one place in the example (in one JVM if it is kept
entirely in memory). If you need to scale beyond this constraint, you will have to
(re)distribute the data somehow. Since the message passing style uses addresses, looking
ahead, you can see that if local and remote addresses were interchangeable, scaling out
would be possible without code changes of any kind.
So again, we have paid a small price in terms of more explicit cooperation, but
reaped a clear long-term benefit.
©Manning Publications Co. We welcome reader comments about anything in the manuscript - other than typos and
other simple mistakes. These will be cleaned up during production of the book by copyeditors and proofreaders.
http://www.manning-sandbox.com/forum.jspa?forumID=835
13
Licensed to Konstantinos Pouliasis <konstantinos.pouliasis@gmail.com>


剩余393页未读,继续阅读
2017-12-04 上传
2016-10-14 上传
2020-02-22 上传
点击了解资源详情
点击了解资源详情
2023-10-05 上传
2021-02-15 上传
2021-04-28 上传

麻团
- 粉丝: 5
- 资源: 83
 我的内容管理
展开
我的内容管理
展开







