Selenium爬取中国大学MOOC的Python课程数据
需积分: 38 100 浏览量
更新于2024-09-06
5
收藏 1.19MB PDF 举报
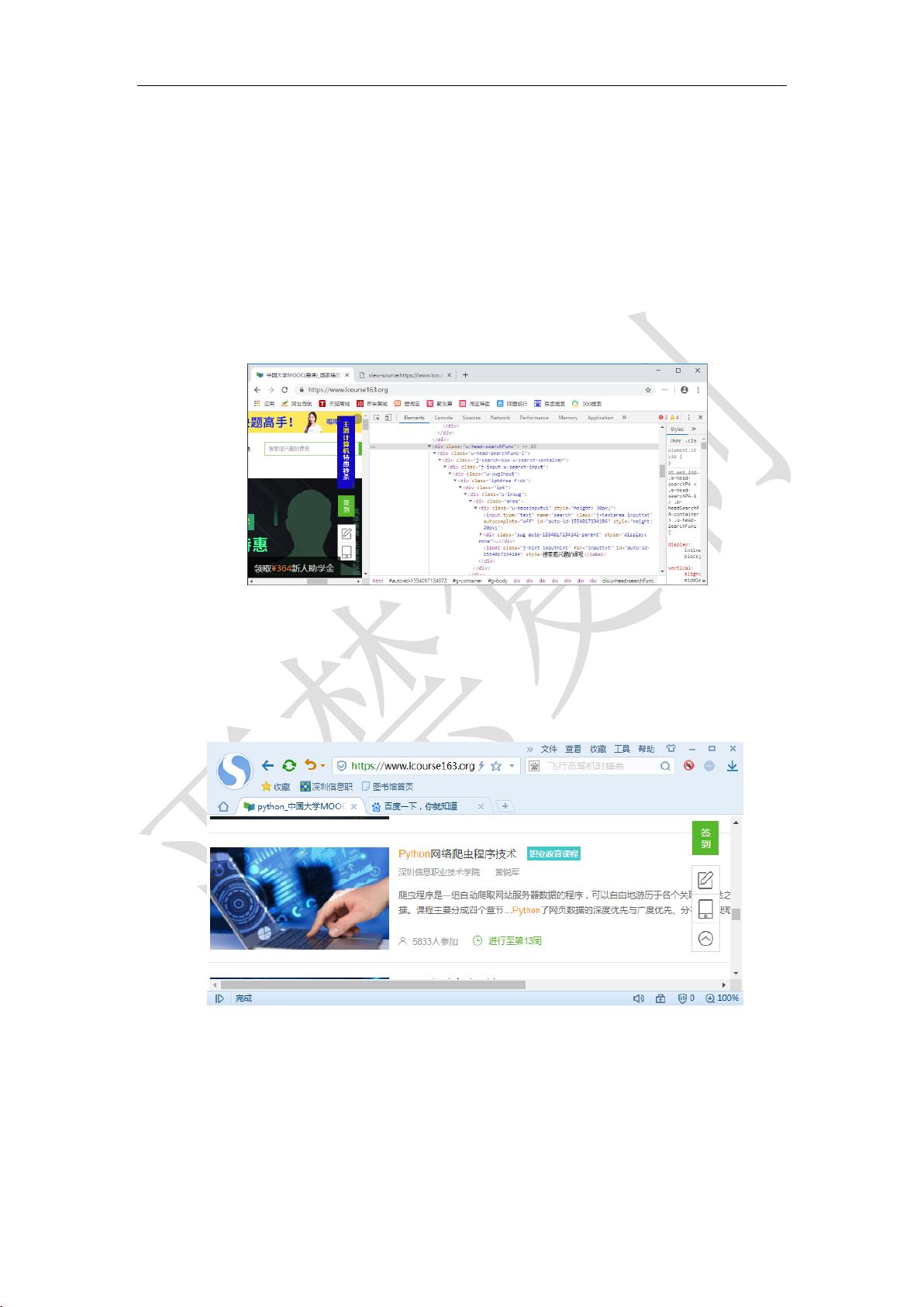
在这个关于爬取中国大学MOOC课程数据的项目中,主要任务是利用Python和Selenium技术从该知名在线教育平台获取Python类型的课程信息。首先,我们通过Selenium模拟浏览器操作,访问中国大学MOOC的首页(<https://www.icourse163.org>),并利用XPath表达式定位查找框(`//div[@class='u-head-searchFunc']//div[@class='j-search-box u-search-container']`),输入关键词“python”进行搜索。搜索后,会跳转到包含相关课程的结果页面。
在课程页面,我们需要解析HTML代码以提取所需数据。例如,当右键点击一个课程名时,可以看到其HTML结构中包含了课程的基本信息,如链接(`data-href="/course/ZIIT-1002925008"`)和课程ID(`data-label="1002925008_1003114015"`)。HTML代码中包含课程图片(`<img>`标签)以及可能的课程名称和描述等。
具体解析步骤如下:
1. **网页解析与数据提取**
- **XPath选择器的使用:**XPath是一种强大的查询语言,用于在XML和HTML文档中定位元素。在这里,它被用来定位输入框、按钮以及课程链接等关键元素。
- **模拟用户交互:**Selenium模拟真实用户的行为,包括输入关键词、点击搜索按钮,以及处理可能出现的JavaScript动态加载内容。
- **HTML解析库:**Python中的BeautifulSoup或lxml库可以帮助解析复杂的HTML结构,提取出课程的名称、链接、图片地址等信息。
- **数据存储:**爬取到的数据通常会被保存到CSV、JSON或其他数据结构中,以便后续分析或进一步处理。
2. **处理异常和错误:**在代码实现过程中,可能会遇到网络连接问题、页面结构变化或元素找不到等异常情况,需要使用try-except语句捕获并记录这些错误。
3. **性能优化与反爬虫策略:**为了防止频繁爬取导致IP被封禁,可以设置延迟(time.sleep())或使用代理IP。同时,注意遵守网站的robots.txt规则,尊重版权和爬虫政策。
4. **课程数据筛选:**由于可能存在大量的Python课程,可以通过正则表达式或字符串操作过滤出真正相关的课程,比如只保留那些标签或描述中包含“Python”的课程。
5. **自动化和可扩展性:**将整个爬虫流程封装成函数或模块,方便在需要时重复调用,提高代码的复用性和可维护性。如果网站结构有较大变化,只需更新XPath表达式即可适应。
总结来说,这个项目是运用Python爬虫技术,结合Selenium模拟浏览器行为,从中国大学MOOC网站高效地抓取Python课程数据,并通过解析HTML结构获取课程详情,为学习者提供有价值的数据源。同时,遵循良好的编程实践,确保爬虫的稳定性和可扩展性。
1
爬取中国大学 MOOC 课程数据
任务:
在中国大学 MOOC 网站中有很多课程,这个项目的任务就是使用 Selenium 爬取网站中
Python 类型的课程的数据。
一、解析网页
(1) 网页分析
1、查找课程
进入中国大学 MOOC 网站 https://www.icourse163.org,在查找框中输入”python”就可以
查找到 Python 一类的课程,网址变成:
https://www.icourse163.org/search.htm?search=python#
如图 1 所示。
图 1 MOOC 网课程
编写程序完成这个动作:
def process(self, url, key):
try:
self.chrome.get(url)
div = self.chrome.find_element_by_xpath(
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
2021-04-21 上传
2021-04-21 上传
2021-07-18 上传

wangyqid
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
