大规模图像检索:哈希算法详解与效率提升
需积分: 17 133 浏览量
更新于2024-07-20
收藏 1.82MB PDF 举报
大规模图像检索哈希算法选讲是一篇关于在海量图像检索场景中应用哈希技术的文章,着重于解决如何快速、有效地在大量图像中查找与查询图像相似的图片问题。文章首先介绍了基于内容的图像检索基本流程,包括用户提交原始图像,预处理(如调整大小、增强等),然后进行特征提取,构建图像特征库,以及用户输入待检索图片后的查询过程。
哈希算法的核心概念是将图像的特征转换为一段固定长度的二进制编码,其主要优点在于显著提高了检索速度。通过使用哈希算法,如将传统的特征提取时间(例如SIFT-FV)从0.673s降低到0.106s,同时K-nearest neighbors检索的时间提升接近20倍,达到0.168s,大大提升了系统的实时性能。
有效的哈希算法应满足两个关键特性:一是二进制编码长度要短,以保持速度优势;二是确保相似的图像具有相近的哈希编码,即保持相似性(similarity-preserving)。文章列举了几种常见的哈希算法类别,包括:
1. 数据独立哈希(如局部敏感哈希LSH):这些方法基于数据本身的特性,如LSH通过构造多个随机投影矩阵,将数据映射到低维空间,使得相似的数据点有更高的概率被映射到同一哈希桶。
2. 谱哈希(SH)和量化迭代(ITQ):属于基于数据的无/有监督学习方法,利用矩阵分解或迭代优化技术生成哈希码。
3. 线性和非线性模型:如CCA-ITQ和DBC,以及KSH和BRE,这些可能是结合了深度学习的深度哈希方法,如基于CNN的哈希算法,利用深度神经网络提取高级特征并进行哈希编码。
4. 监督和无监督方法的区别:监督方法通常需要训练样本标签,如深度哈希基于有标注数据进行学习,而无监督方法则无需标签,如LSH和SH。
在数据库预处理阶段,LSH常用于在线查询加速。它通过对原始特征数据进行哈希映射,使得相似数据点更可能出现在同一个哈希桶中,查询时只需找到待查询特征对应的桶,然后在桶内进行线性搜索,降低了复杂度。嵌入过程涉及将高维特征映射到Hamming空间,二级哈希进一步将数据压缩到较小的桶(比如由C维数据压缩到k维,并用一个数值表示桶序号)。
然而,哈希算法也存在一些缺点,如哈希碰撞(不同的图像可能映射到相同的哈希值)、信息损失(编码过程中可能会丢失部分原始特征信息)和计算效率与准确性的权衡。因此,在实际应用中,选择合适的哈希算法需要根据具体需求和数据特性来决定。
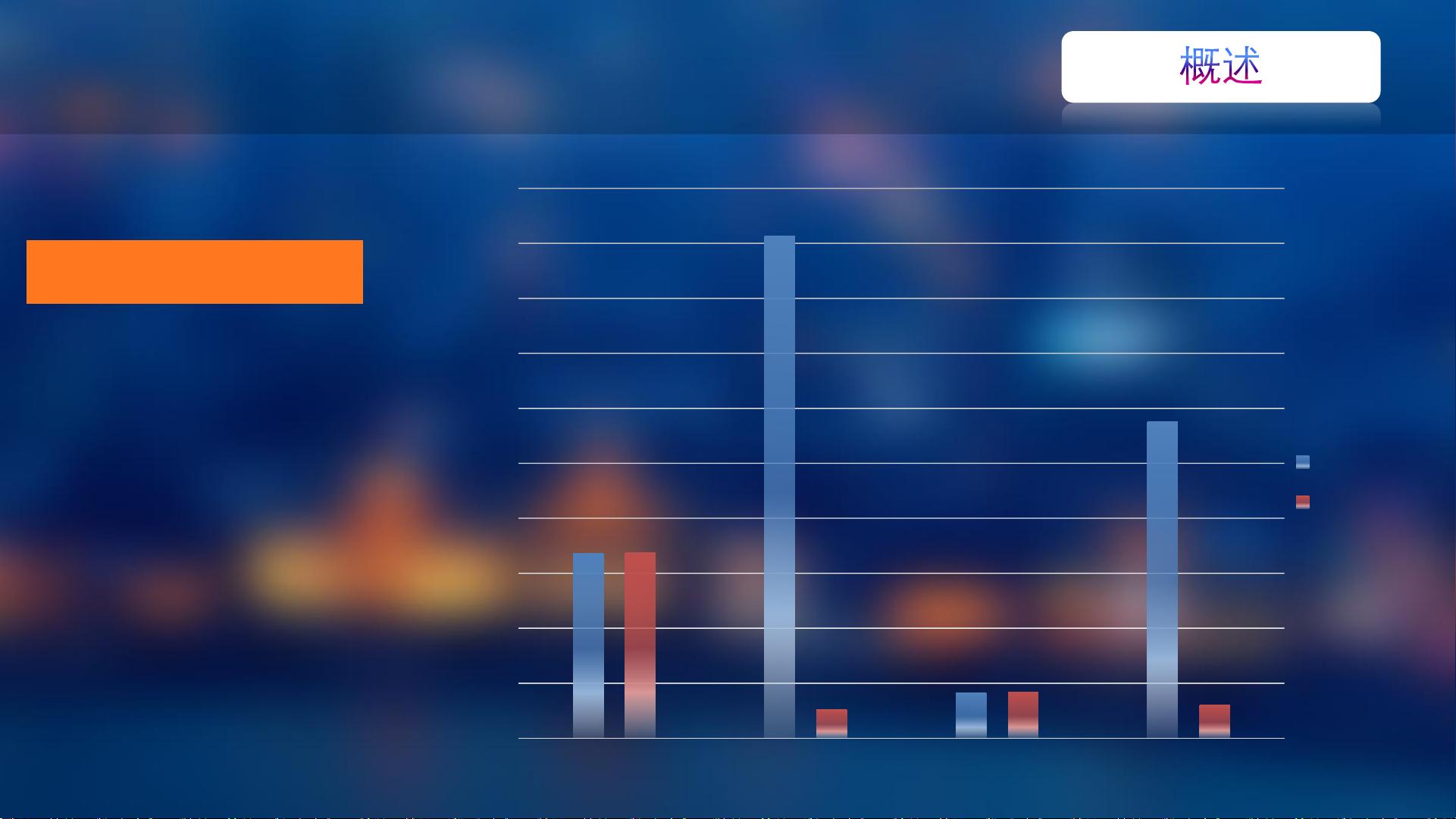
为什么使用哈希算法?
快!!
特征提取的时间只增加了0.002s,
而 K-nearest 检索的速度提升
将近20倍!
0.673
1.828
0.166
1.152
0.675
0.106
0.168
0.121
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
cnn提取特征
cnn近邻检索
sift-fv提取特征
sift-fv近邻检索
ITQ编码前
ITQ编码后
© Copyright FYT 2016
剩余16页未读,继续阅读
点击了解资源详情
344 浏览量
240 浏览量
298 浏览量
333 浏览量
172 浏览量
259 浏览量
点击了解资源详情
122 浏览量

Yetongfff
- 粉丝: 8
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 预测ABO3-结构
- 易语言-易语言超级列表框分页
- redux-fundamentals-example-app:Redux基础知识示例应用程序
- C#实体类生成器
- 获取多个游标的坐标8.2_labview获取游标_
- cli-rustdoc:用于Rust包或库的Buildsfinds文档
- react-flask-todilo:React + Flask =待办事项!
- 新海螺模板M3.2版本苹果cms模板全开源源码免授权无后门
- 光电通OEM3000DN兆芯.7z
- shariff-backend-perl:Shariff的Perl(Mojolicious)后端。 Shariff使网站用户可以共享自己喜欢的内容,而不会损害其隐私
- Diagnoser:运行AutoFixer诊断程序任务的脚本
- keras-基础学习课件(追光者).zip
- remote-camera:电子应用程序示例,该应用程序创建Web服务器,然后将连接的用户的远程网络摄像头流式传输到本地计算机
- 2020-2021年-CSAAI-实践:Misprácticasde CSAAI del curso 2020-2021年
- Python系统化基础知识思维导图
- gift-app-node
