ChatGPT在大数据场景的应用实例:Hadoop、Pyspark与Hive操作
需积分: 0 198 浏览量
更新于2024-08-03
收藏 779KB DOCX 举报
在当前的IT领域,ChatGPT作为一款强大的语言模型,正逐渐被应用到各个业务场景中,特别是大数据处理方面。本文将重点探讨ChatGPT在大数据场景中的具体应用,通过实例展示其在数据处理、分析和查询中的潜在价值。
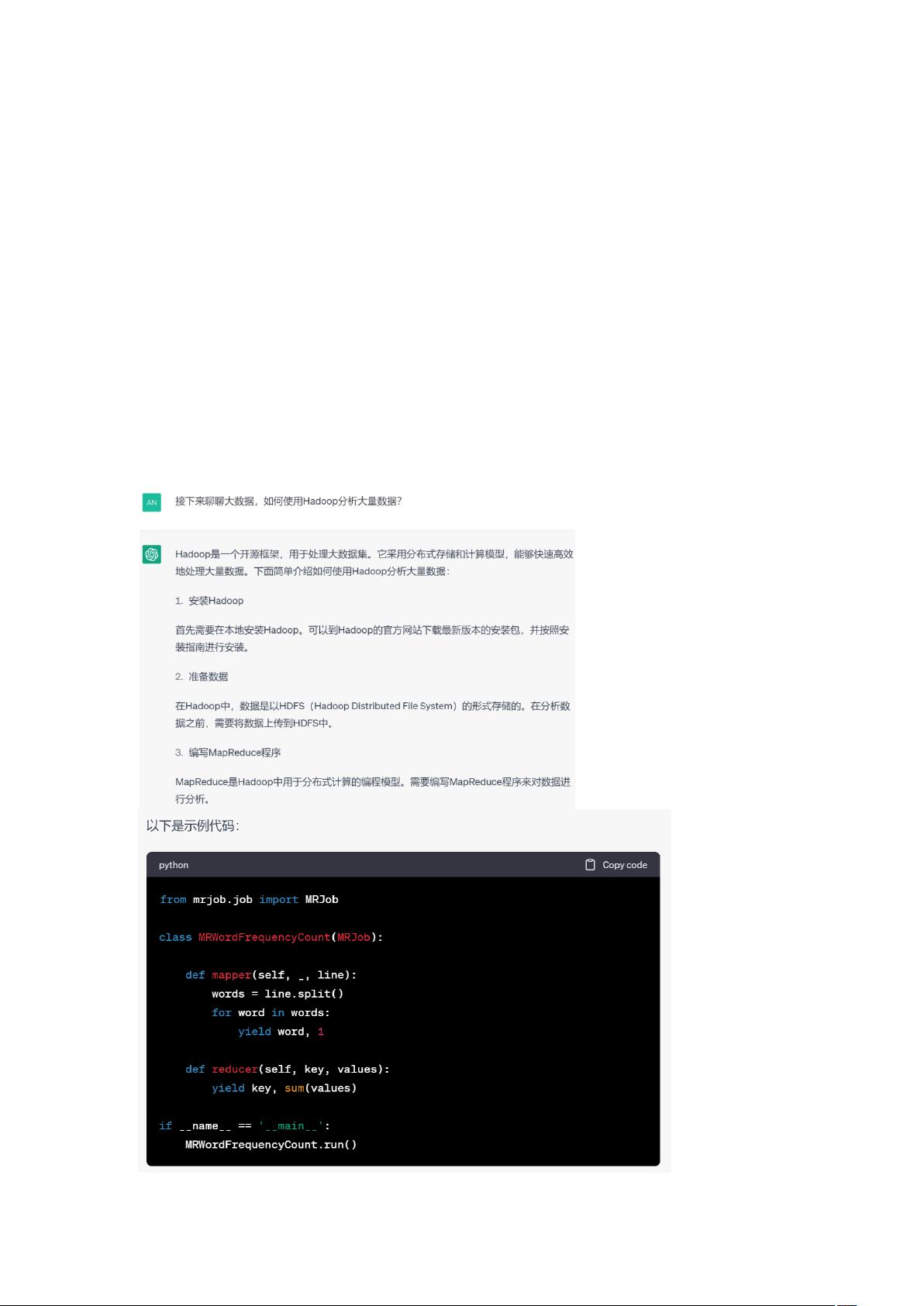
首先,ChatGPT可以作为学习和参考工具来指导用户如何使用Hadoop进行大数据分析。Hadoop是一个分布式计算框架,常用于存储和处理大规模数据集。利用ChatGPT,开发者可以获取关于Hadoop分布式文件系统HDFS的配置、MapReduce编程模型的解释,以及如何有效地进行数据划分和并行处理的建议。ChatGPT能够提供清晰的步骤指导,如配置环境、编写Mapper和Reducer代码,甚至提供优化策略,帮助简化大数据分析流程。
其次,对于使用Python的Pyspark进行词频统计,ChatGPT也能给出实用的指导。Pyspark是基于Spark的Python接口,常用于大规模数据处理。ChatGPT可以解释如何加载数据、创建DataFrame、应用WordCount函数,以及如何清洗和整理文本数据以便进行词频统计。通过这种方式,ChatGPT不仅提供理论知识,还能演示实际代码片段,使得学习者能够快速上手。
再者,ChatGPT能协助用户理解如何在Hive中查询大型数据集。Hive是一个基于Hadoop的数据仓库工具,允许用户以SQL的方式查询存储在Hadoop分布式文件系统中的数据。ChatGPT可以提供关于Hive的SQL语法解释,包括如何创建表、编写复杂的Join操作,以及如何优化查询性能。它还可以解答关于连接大型数据表、分组聚合以及条件筛选等问题。
ChatGPT在大数据场景中的应用有助于提升数据分析师、开发人员和管理人员的工作效率。无论是初学者还是经验丰富的专业人士,都能从中受益于ChatGPT提供的即时反馈、最佳实践和代码示例。然而,值得注意的是,虽然ChatGPT能提供大量信息,但它的智能水平目前仍受限于训练数据,所以在处理复杂问题时,结合人类的专业判断和实践经验仍然是关键。
不同业务场景使用 ChatGPT——2.大数据场景使用 ChatGPT
七篇相关文章:
1.ChatGPT 简介
2.大数据场景使用 ChatGPT
3.机器学习深度学习场景使用 ChatGPT
4.数据库管理场景使用 ChatGPT
5.后端开发使用使用 ChatGPT
6.自动化测试中使用 ChatGPT
7. Web 开发中使用 ChatGPT
2.
(1)如何使用 hadoop 进行大数据分析
下载后可阅读完整内容,剩余3页未读,立即下载
2024-12-25 上传

相交弦
- 粉丝: 75
- 资源: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- 2019-is262b-techdmgt:is262b类访问的回购
- 基于java的开发源码-很不错的计算器.zip
- Royale:加利福尼亚州阿纳海姆市-Minecon 2016展览展示。 大逃杀
- poker:扑克培训网站
- GGRD_DataBase
- good-for-nothing-compiler:这是 Joel Pobar 和 Joe Duffy 于 2005 年在 PDC 上提出的 C# 中旧的 Good for Nothing Compiler 的延续
- 基于java的开发源码-局域网广播系统Java源码.zip
- PML-30:在Phys-Math Lyceum 30的“ CGSG”课程中制作的项目
- DesignPatterns:Java23种设计模式代码练习
- DSW-FedericoMurillo
- JS调试工具源码-易语言
- roformer-pytorch:Roformer的实现,这是一种带有旋转位置嵌入的变压器,这是一种未公开的相对位置编码新技术,正在中国的NLP圈子中流传
- 行业分类-设备装置-可随升降架运动的独立转料平台.zip
- Estudos-em-Geral:Projetos criados nas aulas e cursos
- JMS:基于Apache ActiveMQ JMS实现的远程服务分发提供程序
- node-redis-namespace:命名空间 Redis 键
