Flink Standalone模式安装与WordCount实战指南
需积分: 9 122 浏览量
更新于2024-08-05
收藏 497KB DOCX 举报
"Flink安装-简介"
Apache Flink是一个开源流处理框架,它提供了一种在无界和有界数据流上进行低延迟、高性能、分布式处理的能力。本指南将介绍如何在本地环境下安装和配置Flink的独立(Standalone)模式,并进行简单的WordCount示例测试。
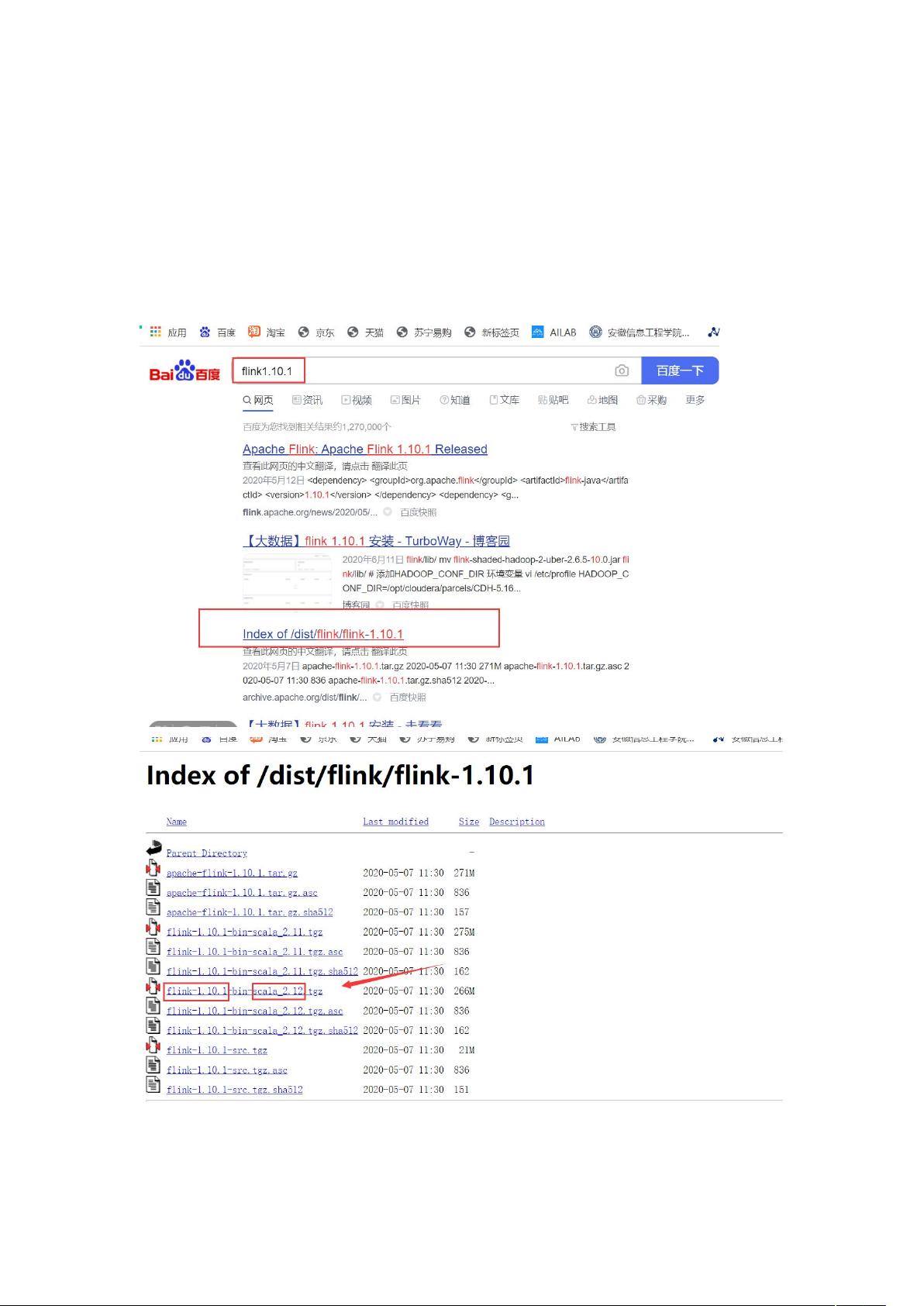
首先,我们需要选择合适的Flink版本。在这个例子中,选择了Flink 1.10.1版本。这个版本支持Scala 2.12,因此下载对应的二进制包`flink-1.10.1-bin-scala_2.12.tgz`,并将其解压缩到指定目录,如 `/iflytek/`。
安装完成后,配置文件是Flink运行的关键。主要的配置文件位于`conf/`目录下的`flink-conf.yaml`。这个文件包含了许多可调整的参数,例如JobManager(JOP)的RPC通信地址、端口、JVM堆内存大小以及任务内存大小等。你需要根据实际的硬件配置和需求来修改这些参数。例如,将JOP的Rpc通信地址从`localhost`更改为实际的主机名或IP地址,以适应分布式环境。
`conf/master`和`conf/slaves`文件也需要进行相应的修改。`master`文件列出了JobManager的地址,`slaves`文件则包含了TaskManager的节点列表。在独立模式下,`localhost`可以替换为你的虚拟机IP别名,以确保集群能够正常启动。
启动Flink Standalone模式的步骤如下:
1. 进入到`flink-1.10.1`目录。
2. 切换到`bin/`子目录。
3. 运行命令`./start-cluster.sh`,这将启动JobManager和TaskManager进程。
为了验证Flink的正确安装和配置,我们通常会执行一个简单的WordCount示例。`Examples`目录包含了预置的示例代码,其中就包括了`WordCount`。首先,创建一个包含单词的文本文件(如`1.txt`),然后将Java编译后的`WordCount.jar`(或者直接使用未编译的`.java`源码通过IDEA编译生成)与该文本文件一起放在`bin/`目录下。
运行WordCount示例的命令如下:
```bash
./flink run ../examples/streaming/WordCount.jar --input iflytek/flink-1.10.1/bin/1.txt --output iflytek/flink-1.10.1/bin/2.txt
```
执行后,结果会被写入到`2.txt`文件中,显示每个单词及其出现的次数,如`(hello,1)`, `(hdfs,1)`, `(hadoop,1)`, `(spark,1)`。
通过这个过程,你已经成功地在本地安装了Flink并运行了第一个流处理任务。为了进一步了解和使用Flink,你可以探索更多高级特性,如窗口操作、状态管理、检查点以及Flink与其他大数据组件(如Hadoop、HDFS和Spark)的集成。
Flink 安装(Standnole 模式)
1. 版本选择(Flink1.10.1)
下载后可阅读完整内容,剩余4页未读,立即下载
2019-08-26 上传
2019-06-17 上传
2019-03-19 上传
2020-06-11 上传
2020-06-12 上传
2020-06-12 上传
2021-08-28 上传
2024-05-13 上传
2020-04-23 上传

lune_Lucky
- 粉丝: 4633
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
