端到端跨级别语义对齐的人物搜索:解决多尺度挑战
137 浏览量
更新于2024-06-20
收藏 2.22MB PDF 举报
"本文探讨了多尺度匹配在人物搜索中的应用,着重强调了跨级别语义对齐(CLSA)深度学习方法的创新性解决方案。作者指出,虽然当前的方法主要关注提高人检测的准确性,但多尺度匹配问题在人物搜索中更为关键。为此,他们提出了一种新的CLSA方法,该方法利用深度神经网络的特征金字塔结构,通过跨金字塔级语义对齐损失函数来学习更独特的身份特征表示,避免了对图像金字塔和复杂多分支网络的需求。实验结果证明,CLSA在人物搜索和多尺度匹配任务上表现出优越的性能,尤其是在两个大型数据集:中大中山大学和PRW上。"
人物搜索是一个复杂的问题,它不仅要求准确地检测场景中的人员,还要识别他们的身份,特别是在不受约束的环境中,如公共监控视频。与传统的人员重识别问题不同,人物搜索面临更多的挑战,如自动检测的边界框可能存在误差,以及目标人物在分辨率上的显著变化。
多尺度匹配是解决这些挑战的关键,因为人物在实际场景中的大小可能因距离和视角的变化而变化。以往的研究往往忽视了这一点,而CLSA的提出正是为了应对这一难题。CLSA通过深度学习模型内在的特征金字塔结构,允许模型在不同的尺度上捕获和对齐语义信息,从而增强身份特征的表示能力。这种方法减少了对额外计算资源的依赖,比如图像金字塔的构建,以及复杂网络架构的设计。
CLSA的创新之处在于其损失函数,它促进了跨不同金字塔级别的语义对齐,有助于在不同尺度的特征之间建立联系,使得模型在处理多尺度输入时能保持一致性。实验表明,这种方法在人物搜索的性能上超越了现有的先进方法,特别是在大规模数据集上的表现。
总结来说,本文的贡献在于提出了一个有效且高效的多尺度匹配方案,即跨级别语义对齐,这对于人物搜索领域的进步具有重要意义。这种方法有望在未来推动人物搜索技术的发展,使其在复杂环境中的应用更加广泛和精准。
4
A.作者和B。作者
无约束场景图像帧
(a)人物检
测
人物
检
测
(b)多尺度自动检测的人物边
界框
比例要素表达
(c)通过多重身份匹配
用CLSA
重新识别
网络
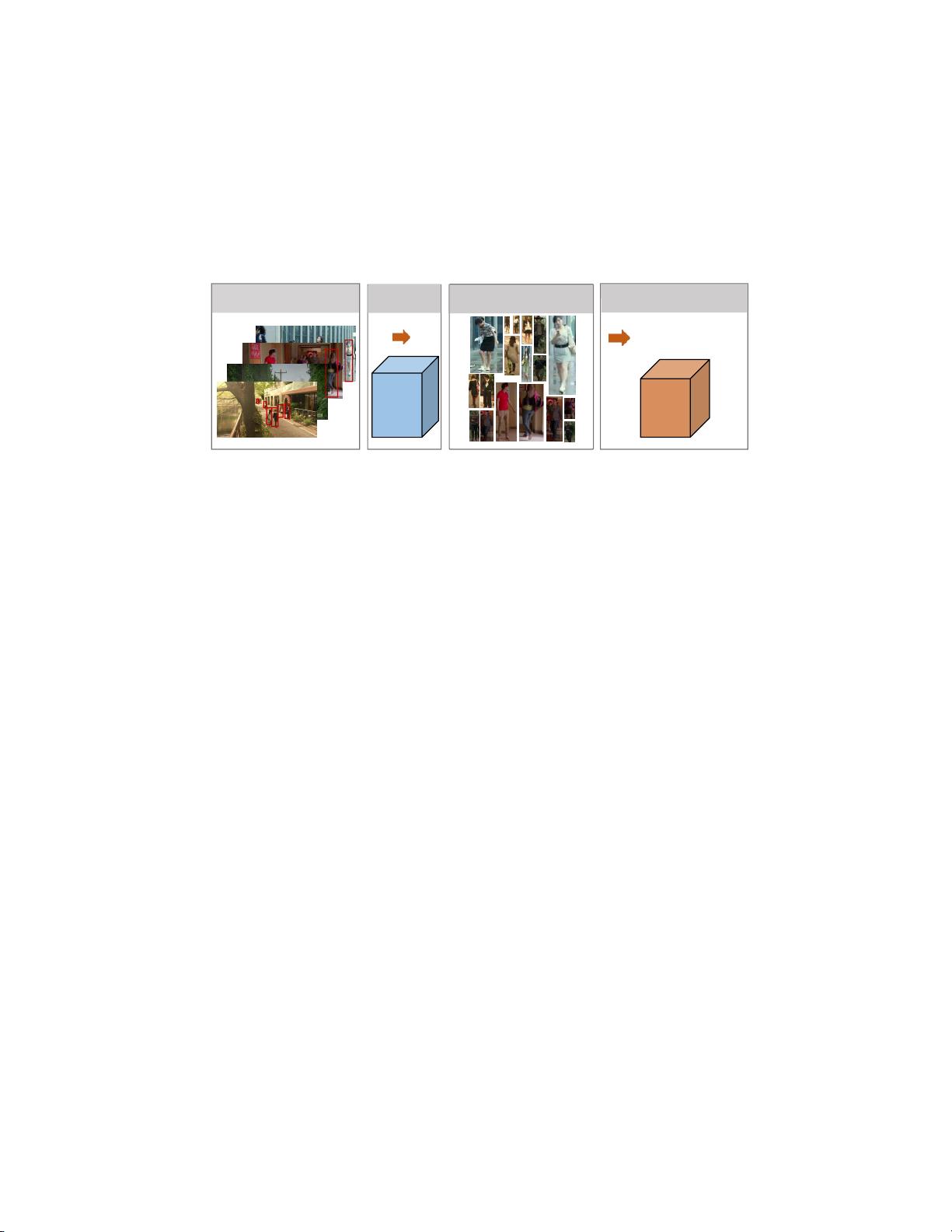
示于图二、CLSA包含两个组件:(1)人检测,其定位图库场景图像
中的所有人实例以促进后续身份匹配。(2)人员重新识别,其将探测图
像与大量任意比例图库人员边界框(CLSA的关键组成部分我们在下
面提供组件详细信息
图二.提出的多尺度学习人员搜索框架的概述。(a)用于以(b)变化的尺度
(分辨率)从整个场景图像裁剪人的人检测(c)然后通过re-id模型进行人员
身份匹配。
3.1
人物检测
作为预处理步骤,人员检测对于实现准确搜索很重要[41,47]。我们采
用Faster-RCNN模型[35]作为CLSA检测组件,因为它具有检测不同大小物
体的强大能力 在不受约束的场景中。为了进一步提高人检测的性能和
效率,我们引入了一些设计改进的原始模型。
(1)
我们没有使用传统的RoI(感兴趣区域)池化层,而是将区域特征
映射裁剪并调整为14×14像素,并进一步将其最大池化为7
×
7,以获
得更好的效率[4]。(2)在预训练图像Ne t -1 K上的背
基
R
es
Ne
t
-50
n
之后,
在对目标人员搜索数据进行微调时,我们确定了构建块(4层)。这
允许保留从较大大小的源数据学习的共享低级特征,同时使模型适应
目标数据。(3)我们保持和利用所有大小的建议,以减少错误检测率在
极端规模的非最大抑制(NMS)操作之前在部署中,我们考虑得分高
于0的所有检测框
。
5,而不是从每个场景图像中提取固定数量的框
[47]。这是因为图库场景图像可以包含变化的(先验未知的)数量的
人。
3.2
基于跨层次语义对齐的
鉴于自动检测的人边界框在任意尺度从画廊场景图像,我们的目标是
建立一个人的身份搜索模型鲁棒性的多
剩余16页未读,继续阅读
2022-06-23 上传
2021-09-23 上传
2023-09-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
166 浏览量
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
