正性几何与N=4 SYM散射振幅的解析结构
147 浏览量
更新于2024-07-16
收藏 1.1MB PDF 举报
本文深入探讨了正性几何在平面N = 4超级杨米尔斯(SYM)散射振幅中的核心作用。作者首先概述了正格拉斯曼几何的基础,这部分内容涵盖了普吕克坐标和简化格拉斯曼几何的表述,这些是理解树级和循环级别的散射过程的关键工具。普吕克坐标是一种特殊坐标系统,它在格拉斯曼子空间中提供了一种直观的几何表示,有助于解析复杂的多粒子相互作用。
文章的核心内容分为四个方面:
1. **正成分与BCFW递归关系**:作者提出了“正分量”这一概念,这是一种基础构建块,用于构造正矩阵。通过仅仅依赖于正性原则,作者能够直接推导出树级和1环BCFW(Britto-Cachazo-Feng-Witten)递归关系,这是一种计算高阶散射振幅的有效方法,其在量子场论中扮演着重要角色。
2. **Grassmannian几何与符号表示**:作者利用格拉斯曼几何的性质,特别是普吕克坐标,来解析N2MHV同源性的符号,这些符号揭示了Yangian不变量之间的关联。更重要的是,它们揭示了大多数符号其实隐藏着简单的NMHV(next-to-maximally helicity-violating)多项式身份,这是理论物理中的重要发现。
3. **堆积正关系与矩阵参数化**:文章还介绍了堆积正关系,这是一种强大的工具,用于以d log形式参数化矩阵,使得对给定几何配置的正矩阵的表示更为简洁。这种方法与简化格拉斯曼几何的表示结合,提供了一种独立于BCFW桥组合法的求解路径,对于理解多粒子系统的行为具有重要意义。
4. **优雅的BCFW递归关系**:最后,作者提出了一个优雅且精细的BCFW递归关系版本,特别适用于树级幅。这个版本展示了BCFW轮廓与简化格拉斯曼几何之间深刻的三角形结构,这种几何表示使得对散射振幅的分析更加直观和高效。
这篇论文将正性几何与动量旋扭草丛正几何相结合,为平面N = 4 SYM散射振幅的研究提供了新的洞察和计算策略,对于深化我们对量子场论基本原理的理解具有重要的学术价值。

JHEP12(2017)147
relations. The Jacobian J is fixed such that the integral remains invariant under the
uniform GL(1) rescaling, since it helps compensate the rescaling weight. It is easy to check
that this new integral reduces to the familiar one if columns 1, . . . , k are fixed to be a
unit matrix, without loss of generality. In fact, we have done nothing new but renaming
C
αa
=(−)
k−α
∆
1 ... bα ... k a
for a=k+1, . . . , n.
In the Pl¨uckerian integral formulation, its gauge fixing is simplified to choosing a
Pl¨ucker coordinate to be any non-vanishing value (usually, it is unity), rather than fixing
a k × k sub-matrix of C. It is more convenient to switch the gauge in order to suitably
characterize each cell now. We will use this technique extensively in section 4, which proves
to be efficient for determining the signs of homological identities.
One may ask how we express the super delta function in (2.2), in terms of Pl¨ucker
coordinates as
δ
4k|4k
(C
αa
(∆)Z
a
), (2.23)
the general answer is unknown, but for the canonical gauge above, we can simply follow
the substitution C
αa
=(−)
k−α
∆
1 ... bα ... k a
which is similarly a trivial renaming.
2.3 Reduced Grassmannian geometry
While the Grassmannian geometric configurations can be explicitly parameterized by
Pl¨ucker coordinates, for plenty of cells it is practical to characterize them in a more com-
pact form, with the price of suppressing their parameterizations. These notations are the
(reduced) Grassmannian geometry representatives, as we have met in the introduction.
Here, a more systematic exposition will be presented.
First, we use “empty slots”, such as [i], to denote removed columns. It is worth
emphasizing that all these symbols only make sense when k and n are specified. For
example, when k = 1, n = 6, [6] means the 6th entry is absent in the Yangian invariant,
so the resulting quantity is a 5-bracket [12345] (to avoid confusion, we will stress it when
a 5-bracket shows up). They are multiplicative, for instance, [6][7] = [67]. As we have
mentioned, such a product is simply a superposition of all constraints.
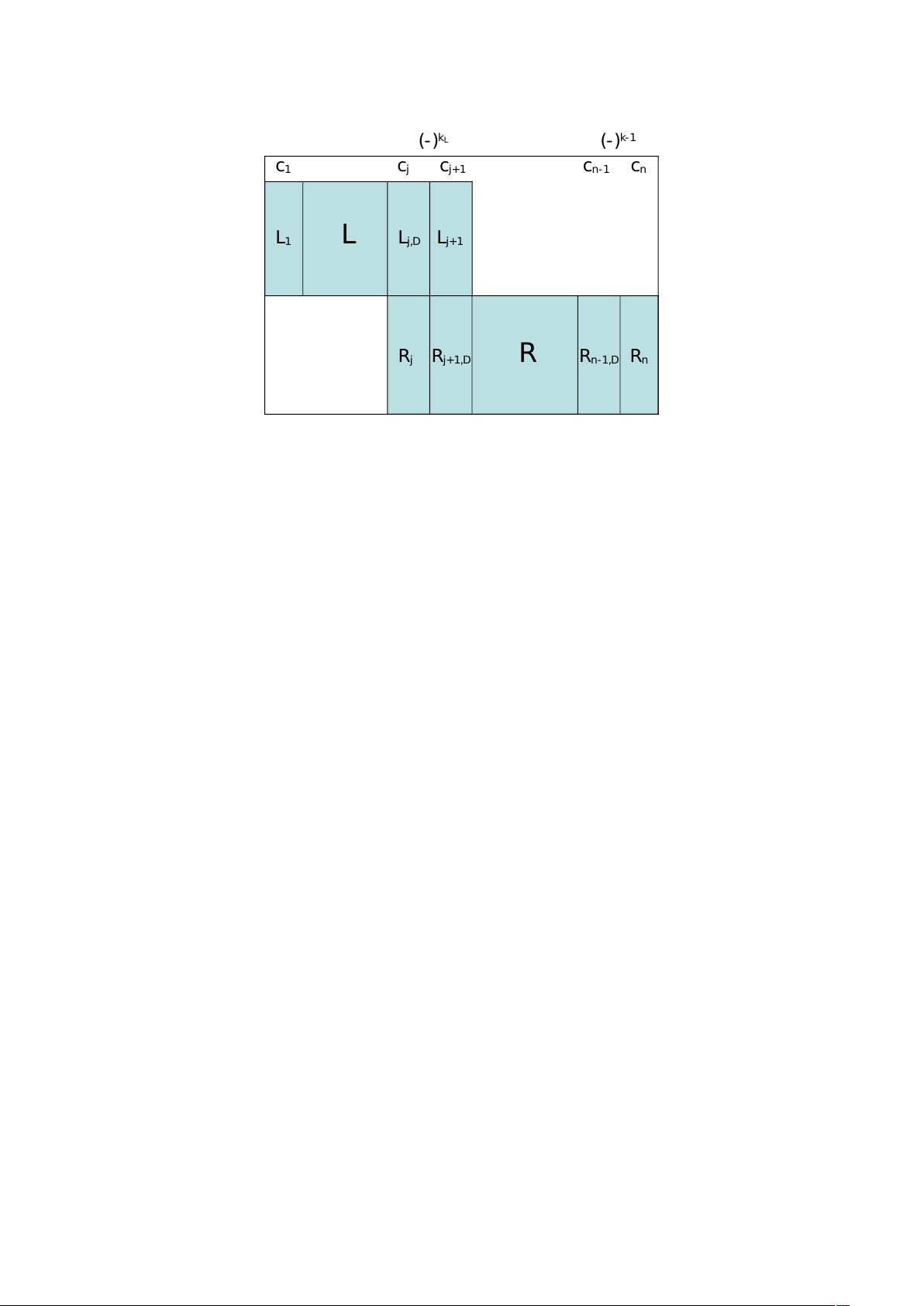
Then, for k ≥ 2 we use (ij) to denote that columns i, j are proportional, which is
also multiplicative. For the example (23)(67) in (2.7), it is now nontrivial to read off the
Yangian invariant, but of course we refrain from doing so. Still we must at least ensure
that it has the correct dimension, which in this case is k(n−k)−2=4k = 8. When k ≥3, the
dimension counting is not transparent in general, and that’s one of the reasons to introduce
the reduced Grassmannian geometry.
The first example is the cell (23)(456) of N
3
MHV n = 8 amplitude in (1.14), where
columns 2, 3 are proportional and columns 4, 5, 6 are “minimally” linearly dependent. We
see that (23) leads to (123) = (234) = 0, but the latter does not necessarily lead to (23).
For both clarity and conciseness, we will use distinct notations for these two different
constraints. This is called the reduced Grassmannian geometry, where its term “reduced”
means that we will only extract the essential geometric information and nothing more than
that. For example, when k =4, (34) will lead to (234)= (345)=(1234) =(2345)=(3456) =0,
still we should write (34) only. Note that (34) also denotes the vanishing of an arbitrary
– 13 –



剩余92页未读,继续阅读
2009-04-25 上传
2020-03-24 上传
2021-05-12 上传
2020-05-03 上传
2020-03-30 上传
2020-04-30 上传
2020-04-16 上传
2020-04-06 上传

weixin_38704835
- 粉丝: 4
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
