文本相似性度量与表示方法探究
需积分: 9 118 浏览量
更新于2024-07-17
收藏 11.1MB PPTX 举报
"该资源为2017年的PPT材料,主要讲解了文本挖掘的一般流程,包括文本相似性度量方法和文本表示方法,特别提到了一种新的表示方法CCODM。涉及的标签有文本挖掘、文本表示、分类、聚类和关联规则。在内容中提到了文本预处理、特征抽取与选择、模型评价、结果可视化等关键步骤,以及各种文本表示模型如向量空间模型、词共现模型、主题模型、词向量模型和文档向量模型。此外,还涵盖了文本分类、聚类和关联规则的应用。"
文本挖掘是信息技术领域的一个重要分支,它致力于从海量文本数据中提取有价值的信息和知识。这个过程通常包括多个阶段,首先是文本预处理,针对中文文本,可能涉及到分词、去除停用词、同义词合并、词性筛选等;而英文文本则可能进行词干化和停用词移除等处理。预处理的目的是使原始文本更适合后续分析。
特征抽取是文本挖掘的关键步骤,通过转换原始数据为更有意义的表示,例如使用词频-逆文档频率(tf-idf)等方法。特征选择则进一步减少特征数量,保留最能反映数据本质的特征。PCA(主成分分析)、LDA(线性判别分析)和DP(聚类)等技术有助于降低维度,提高模型效率。
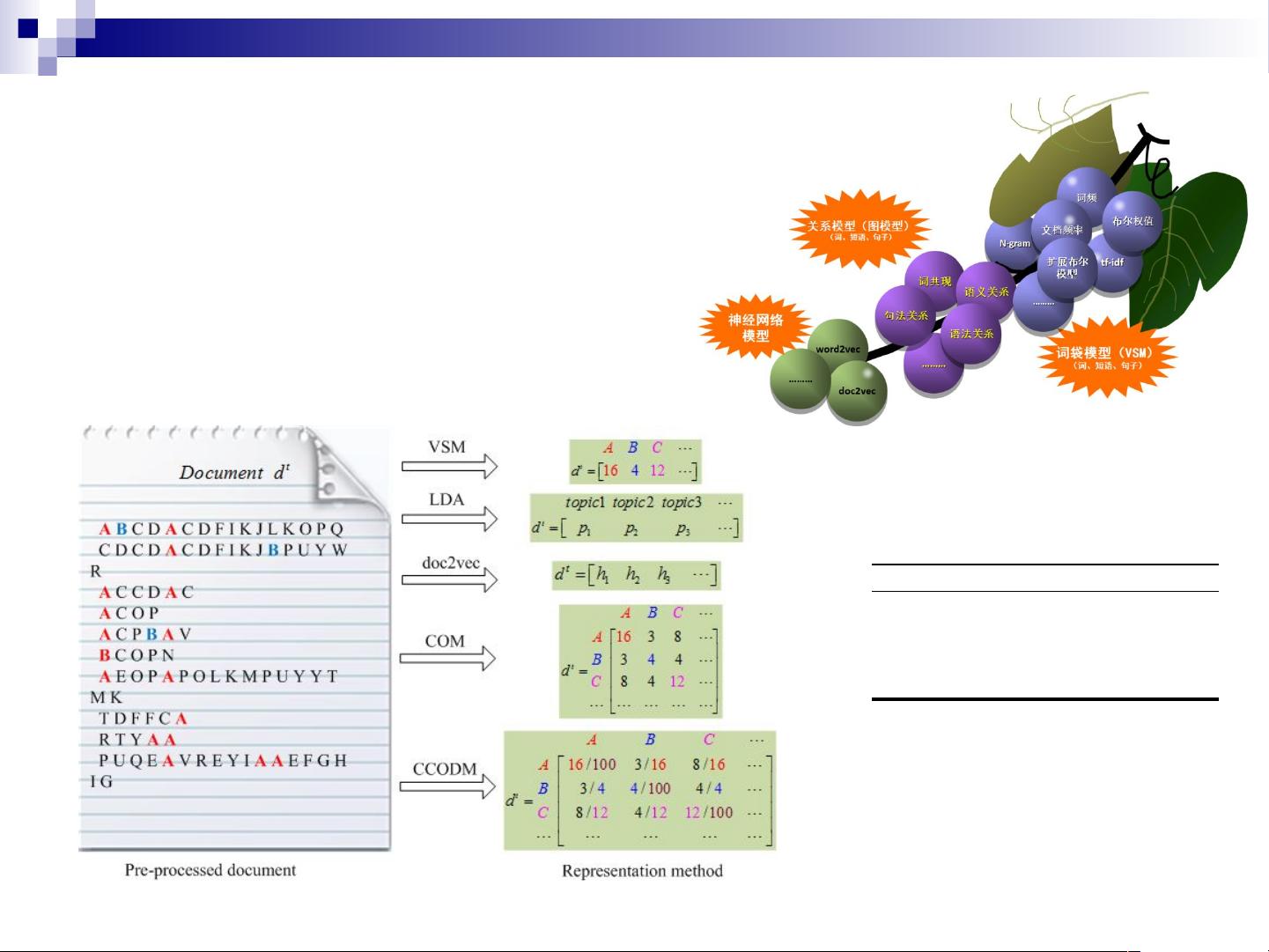
文本表示是将非结构化的文本转化为可计算的形式,常见的模型有向量空间模型(如词袋模型BoW)、词共现模型、主题模型(如LDA)以及近年来流行的词向量模型(word2vec)和文档向量模型(doc2vec)。这些模型能够捕捉词汇间的语义关系,提升文本相似性计算的准确性。
文本分类是将文本分配到已知类别,可以采用监督学习的方法,如朴素贝叶斯、支持向量机等。聚类则是无监督学习,将文本按照相似性分组,如K-means、层次聚类等。关联规则分析则寻找文本中的频繁模式,如Apriori算法,用于发现文本间的隐藏联系。
CCODM是一种新的文本表示方法,可能是在传统方法的基础上进行了创新,旨在提高文本相似性的计算效率和准确性。具体细节未在摘要中详细说明,但可以看出它在当时是一个研究的热点。
文本挖掘是一个复杂而全面的过程,涵盖了从数据预处理到模型构建、评估和应用的各个环节,通过有效的文本表示方法和相似性度量,可以揭示文本数据中的潜在结构和模式,为企业决策、信息检索、情感分析等多个领域提供有力支持。
Institute of Systems Engineering, DLUT
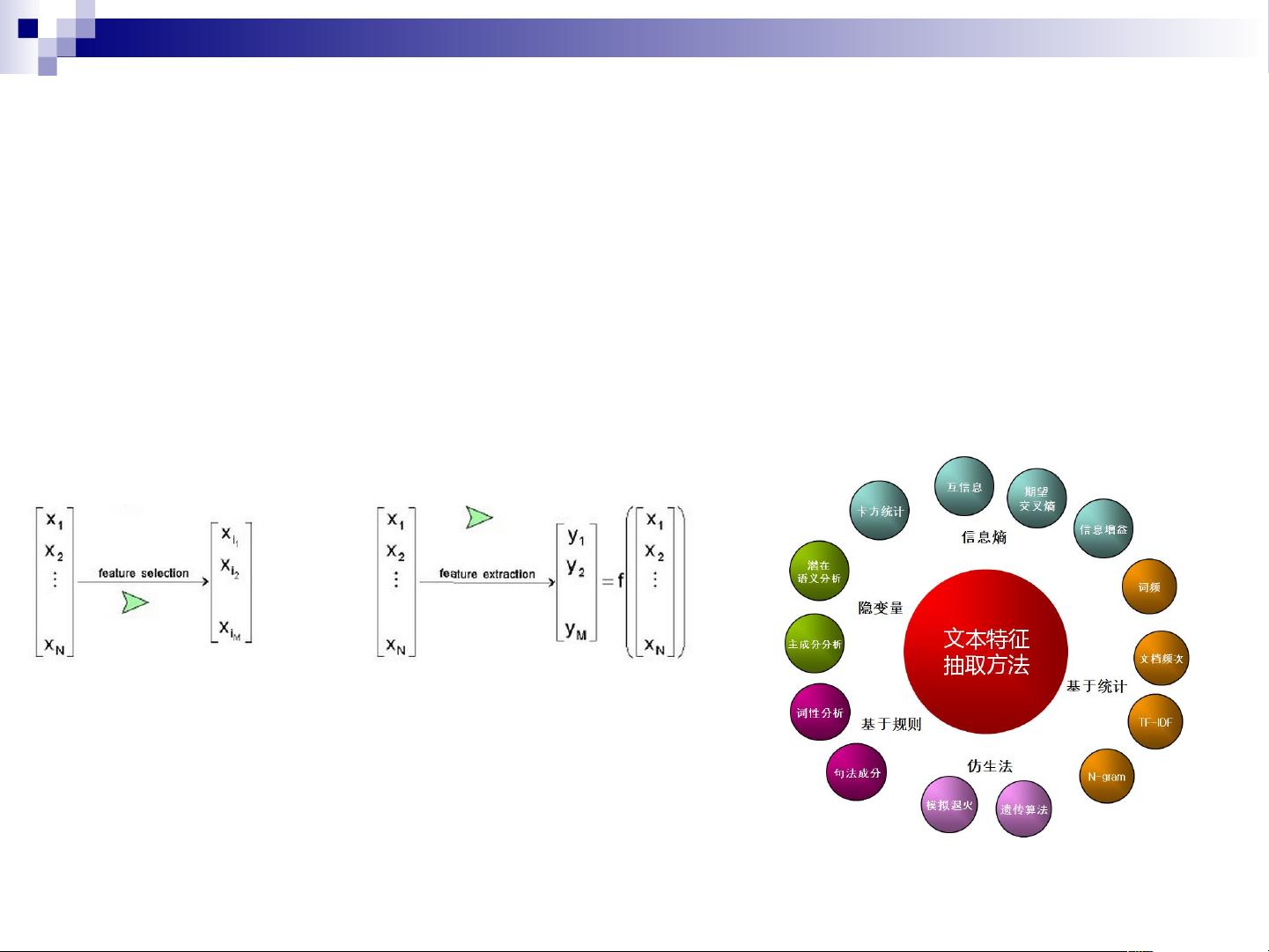
特征抽取 & 特征选择
特征抽取和特征选择是降维的两种方法,针对于维数灾难,都可以达
到降维的目的。但是这两个有所不同。
特征抽取( Feature Extraction ) : 特征抽取后的新特征是原来特征
的一个映射。
特征选择( Feature Selection ) : 特征选择后的特征是原来特征的
一个子集。
PCA, LDA, DP, et al tf, idf, tf-idf, IG, ECE, et al
剩余41页未读,继续阅读
2022-06-03 上传
2022-06-03 上传
2019-06-14 上传

Veyoun123
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
