Spark集群搭建与入门指南
需积分: 16 57 浏览量
更新于2024-07-22
1
收藏 685KB DOCX 举报
"Spark集群部署及入门文档提供了一步一步的指南,适合初学者了解如何在Linux环境中搭建Spark集群,包括硬件环境需求、JDK安装、Spark安装以及Zookeeper集群的构建。"
在深入理解Spark集群部署之前,首先要了解Spark的基础知识。Spark是一款快速、通用且可扩展的大数据处理框架,它提供了高级的编程模型和优化引擎,能够高效地执行批处理、交互式查询、流处理和机器学习任务。Spark的核心特性是其弹性分布式数据集(Resilient Distributed Datasets, RDD),这是一种容错的、可以在集群中并行操作的数据结构。
硬件环境方面,文档提到的示例是一个具有I5core双核四线程CPU和12GB内存的系统。这可以满足基本的Spark集群运行需求,但实际生产环境中可能需要更高的配置来处理大规模数据。
JDK是Java Development Kit的缩写,是运行Java应用程序所必需的。在Spark部署中,JDK1.7被提及,因为它与Spark1.2.0兼容。安装JDK通常包括上传安装包、解压和设置环境变量,确保系统可以在任何路径下执行Java命令。
在软件安装部分,文档指示在Linux环境下创建一个名为`toolkit`的目录来存放所有的软件安装包,并创建`labsp`文件夹作为实验环境目录。Spark的安装涉及下载特定版本的Spark二进制包,例如Spark-1.2.0与Hadoop2.3兼容的版本,以及与其匹配的Scala版本2.10.3。Scala是Spark的编程语言基础,因此版本的匹配至关重要。
Zookeeper是Apache的一个分布式协调服务,对于Spark集群来说,它用于管理集群的元数据,如driver的位置、job的状态等。文档中展示了如何上传、解压Zookeeper,配置`zoo.cfg`文件,创建必要的数据目录,并将配置复制到其他节点,这些都是Zookeeper集群的基本步骤。
在Spark集群环境中,通常会有多台服务器构成,每台服务器都安装了Spark、JDK和Zookeeper。一旦所有节点都配置完毕,就可以通过Spark的`sbin`目录下的脚本启动和管理集群,如`start-all.sh`和`stop-all.sh`,并使用`spark-submit`命令提交应用程序。
这个文档为初学者提供了一个详尽的Spark集群部署教程,从硬件准备、JDK安装、软件包管理到Zookeeper集群的配置,涵盖了Spark集群部署的关键步骤。对于想要学习和实践Spark的人员来说,这是一个非常实用的参考资料。
10使用 命令将上述文件拷贝到 节点的相同路径下
面
!4"45&&%>35&%%:
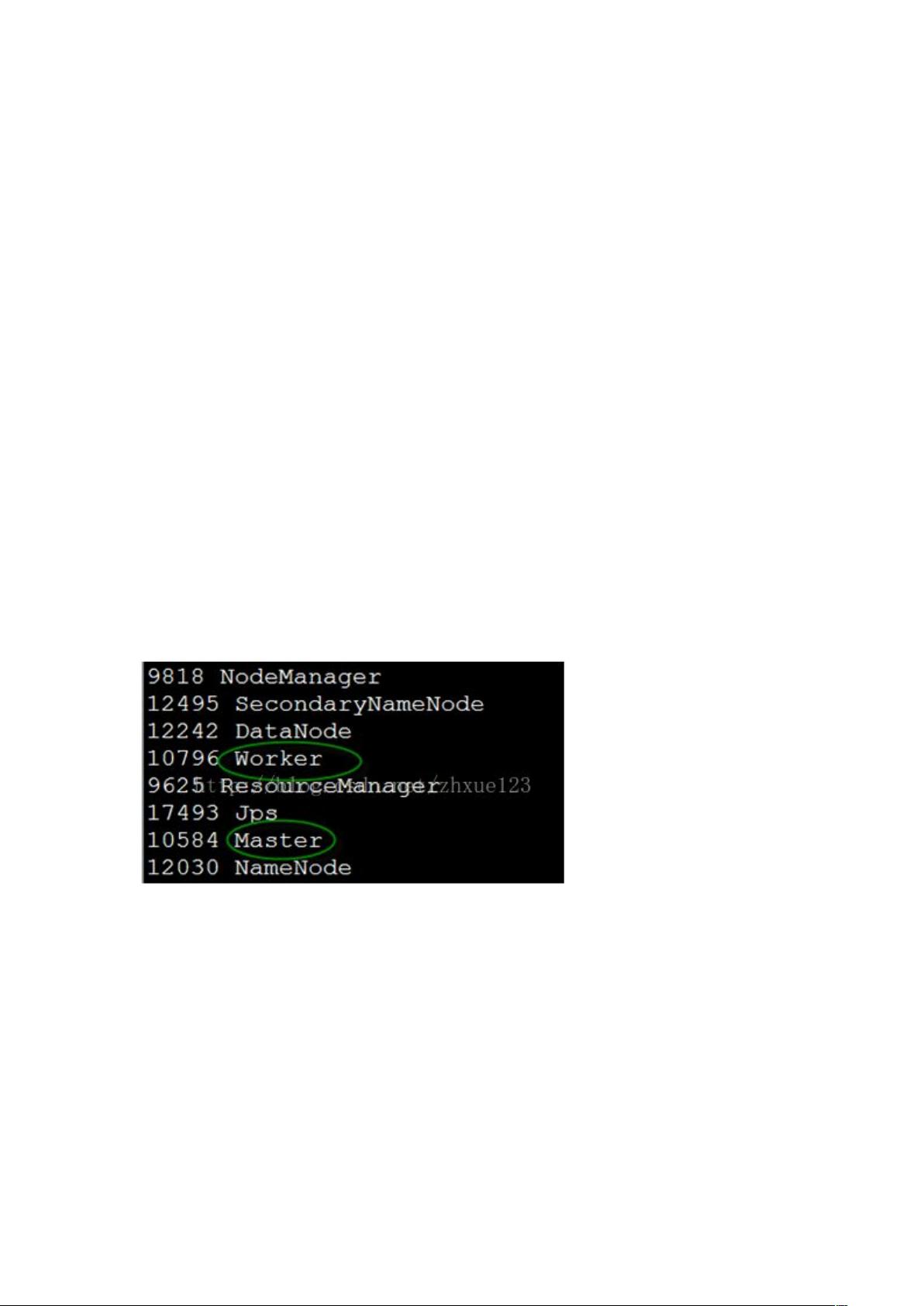
在 上启动 集群2并检查进程是否成功启动。
启动 spark 集群
5<.0*
5#.0((
关闭 spark 集群
5<.0*
5#.0((
如下 % 和 &% 已经成功启动。
使用浏览器打开 53????????3!!,其显示如下所示:
剩余28页未读,继续阅读
2021-04-26 上传
2018-01-16 上传
2021-03-02 上传
2024-04-07 上传
2020-08-19 上传
2020-06-30 上传

巴岸
- 粉丝: 5
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- STC12C5A60S2单片机A/D采样在OLED做一个简易的电压表
- api.woopms:免费的开源酒店物业管理系统
- terraform-azurerm-iq3-agw-内部-https
- JavaWeb期刊管理系统_课程设计附课设报告.zip
- pixelflut-client
- structurizr-dot:使用structurizr库生成图的示例
- UIScrollView-InfiniteScroll:UIScrollView∞滚动类别
- drupal-ping:这提供了一个_ping.php文件,该文件可在负载均衡器中用于检查实例是否正常
- butterfly-admin:基于 amis 并适配 butterfly 的后台模板
- 能力
- SaveReload-crx插件
- auraforce
- email-admin:这个 api 为每个 uesr 创建一个随机电子邮件
- wallabag:wallabag是一个可自我托管的应用程序,用于保存网页:保存和分类文章。 以后再阅读。 自由地
- LaraOngkir:Laravel Ongkir使用RajaOngkir api支票邮政费jne,pos,tiki
- workshop_asp_net_core_mvc
