HBase面试精华:存储结构与优缺点解析及写数据流程详解
需积分: 5 56 浏览量
更新于2024-08-03
收藏 376KB PDF 举报
Apache Hadoop生态系统中的HBase是一款分布式、开源、NoSQL数据库,特别适合处理大规模、高并发、非结构化或半结构化的数据。本文将深入探讨HBase的核心特性和其在面试中可能遇到的问题。
首先,HBase的存储结构主要基于行键(RowKey)- 值对的模型,类似于Google的Bigtable。它的优点包括:
1. **灵活性**:HBase支持动态列族(Column Family),这使得数据存储更为灵活,对于那些数据结构不定、字段变化频繁的场景非常适用,例如社交网络、用户行为日志等。
2. **空间效率**:与关系型数据库不同,HBase对NULL值的处理更高效,只存储实际存在的数据,节省存储空间且提高查询速度。
3. **多版本支持**:HBase可以保存任意数量的版本,这对于记录历史记录或审计跟踪非常有用,如用户更改历史。
4. **低事务要求**:HBase适用于对事务性要求不高的场景,如数据流处理或实时分析,即使出现短暂的数据不一致也不会像金融系统那样严重。
5. **高可用性和大数据处理**:HBase利用Write Ahead Log (WAL)实现数据持久化和故障恢复,支持PB级别的数据存储,特别适合大量写入操作,比如日志系统和时间序列数据。
6. **简单业务场景**:HBase的设计初衷是提供一个简单的数据存储解决方案,避免了复杂的关系型数据库特性,如复杂的JOIN操作和事务处理。
然而,HBase也存在一些限制:
1. **查询局限**:由于基于单一RowKey的结构,HBase难以进行多条件查询,对于复杂的查询需求可能不那么友好。
2. **扫描性能**:HBase不适合全表扫描,特别是大范围的数据查询,可能会消耗较多时间和资源。
3. **SQL支持有限**:HBase不直接支持标准SQL查询,用户需要借助Hive、HBase Shell或其他工具来间接访问数据。
关于HBase的写入流程,客户端首先通过ZooKeeper获取Region的信息,然后根据RowKey、表名和Namespace定位到相应的RegionServer。数据先写入WAL(Write Ahead Log),接着存储到内存中的MemStore。当MemStore达到预设阈值或StoreFile文件达到一定大小(可通过配置调整)时,触发小合并操作,将多个StoreFile合并成一个或多个更大的StoreFile。最后,数据会被持久化到磁盘,确保数据的可靠性和持久性。
面试者需要了解这些关键点,以便在实际项目中正确评估和使用HBase,并准备好解答与之相关的技术问题。
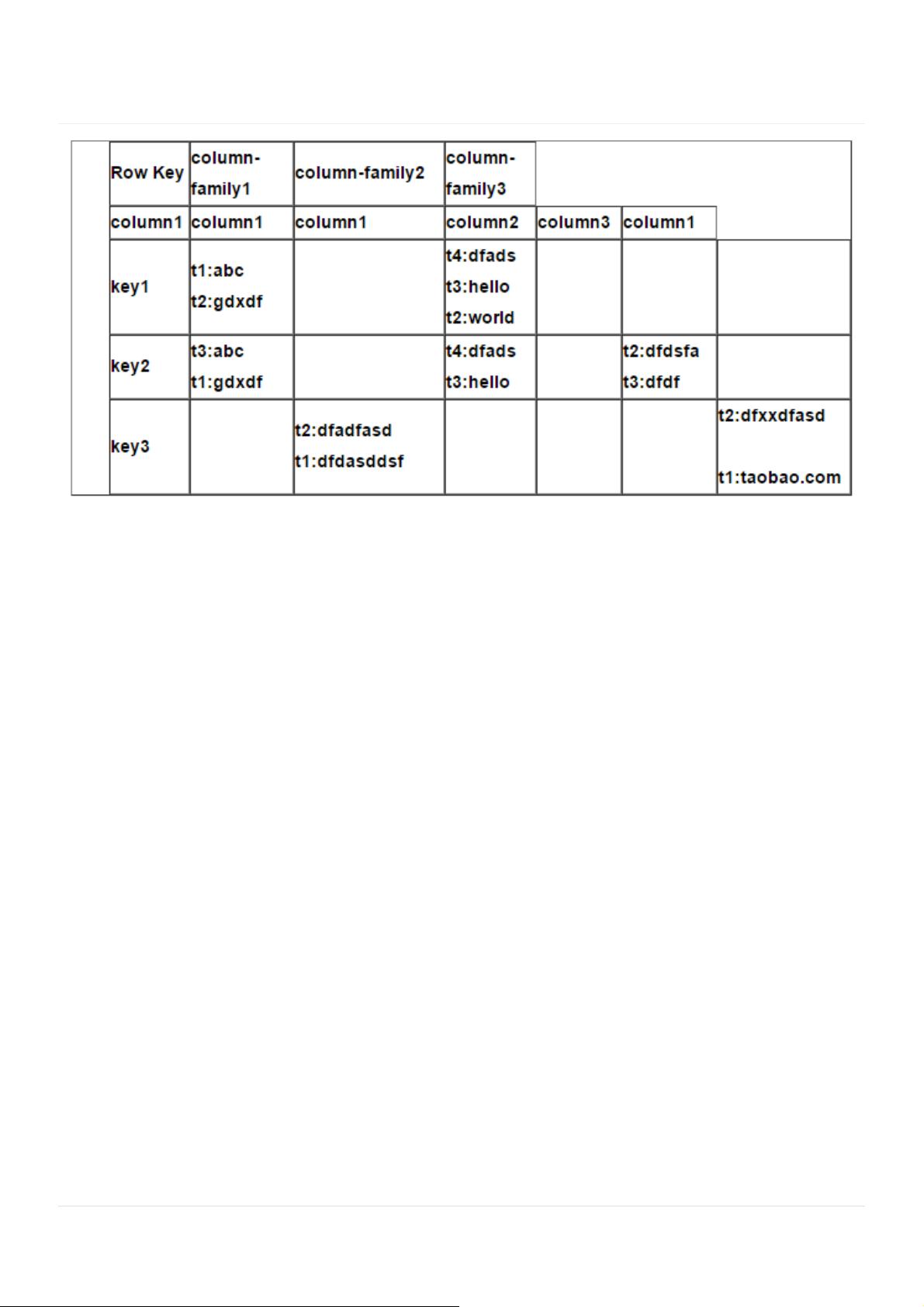
1. 讲⼀下HBase的存储结构,这样的存储结构有什么优缺点
HBase的优点及应⽤场景:
1. 半结构化或⾮结构化数据:
对于数据结构字段不够确定或杂乱⽆章⾮常难按⼀个概念去进⾏抽取的数据适合⽤HBase,因为HBase⽀持
动态添加列。
2. 记录很稀疏:
RDBMS的⾏有多少列是固定的。为null的列浪费了存储空间。HBase为null的Column不会被存储,这样既节
省了空间⼜提⾼了读性能。
3. 多版本号数据:
依据Row key和Column key定位到的Value能够有随意数量的版本号值,因此对于须要存储变动历史记录的
数据,⽤HBase是很⽅便的。⽐⽅某个⽤户的Address变更,⽤户的Address变更记录也许也是具有研究意义
的。
4. 仅要求最终⼀致性:
对于数据存储事务的要求不像⾦融⾏业和财务系统这么⾼,只要保证最终⼀致性就⾏。(⽐如
HBase+elasticsearch时,可能出现数据不⼀致)
5. ⾼可⽤和海量数据以及很⼤的瞬间写⼊量:
WAL解决⾼可⽤,⽀持PB级数据,put性能⾼
适⽤于插⼊⽐查询操作更频繁的情况。⽐如,对于历史记录表和⽇志⽂件。(HBase的写操作更加⾼效)
6. 业务场景简单:
不需要太多的关系型数据库特性,列⼊交叉列,交叉表,事务,连接等。
HBase的缺点:
1. 单⼀RowKey固有的局限性决定了它不可能有效地⽀持多条件查询
2. 不适合于⼤范围扫描查询
3. 不直接⽀持 SQL 的语句查询
2. 讲⼀下HBase的写数据的流程
下载后可阅读完整内容,剩余4页未读,立即下载
207 浏览量
2024-06-17 上传
点击了解资源详情
最全的大数据大厂面试宝典,大数据面试题,大数据面试,王傲旗的大数据之路,大数据成神之路,Flink,Spark,Hadoop,Hbase,Hive,Impala,Hbase,MapReduce.zip
2025-01-01 上传
2024-03-04 上传
148 浏览量
2019-08-09 上传
162 浏览量
2466 浏览量

荒野无尽
- 粉丝: 0
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- ImageAnnotation:有关如何使用Photoshop提取视频帧和注释图像的教程。 提供了两个脚本来计算每个类别的覆盖率和图像大小(R和Matlab)
- mixchar:R包“ mixchar”的存储库
- MFCApplication1.rar
- 在安卓上使用的app例程
- test01:这只是一个git测试库。 测试Git及其功能
- MFC自定义按钮实现
- part_2a_decoding_with_loops.zip
- 行业文档-设计装置-一种具有储水功能的花盆.zip
- EVERSON
- 个人偏好:这些是我使用的所有东西,可能会忘记的事情。 所以我把它们都收集在这里。 这可能对您有用:)
- 验证码训练、识别数据集,共1070个验证码图片
- 华科网络内容管理系统 v5.3 手机+PC
- SSM整合jar包
- matlab确定眼睛的代码-BME3053C-final-project:实验大鼠鬼脸秤的机器识别
- Naga-Phaneendra.Ghantasala_152681_phase2
- 行业文档-设计装置-一种平台升降装置.zip
