TinyC编译器实现与技术解析
需积分: 9 91 浏览量
更新于2024-07-15
收藏 8.08MB DOCX 举报
"该文档是关于编译器的答辩材料,主要涵盖了编译器的前端部分,TinyC编译器的运行成果展示,编译器的架构,以及TinyC编译器的核心技术,包括词法分析、语法分析、中间代码生成和目标代码生成等关键步骤。"
在编译器领域,前端部分主要负责将源代码转化为机器可以理解的形式。文档中提到了NFA转换为DFA项目集规范族,这是词法分析的一个重要环节,确保编译器能正确识别和处理输入的字符序列。词法分析器calc.l是lex(或flex)工具生成的,用于识别并生成词法单元(tokens),而语法分析器calc.y是bison(或yacc)工具根据语法规则生成的,用于解析这些词法单元并构建抽象语法树。
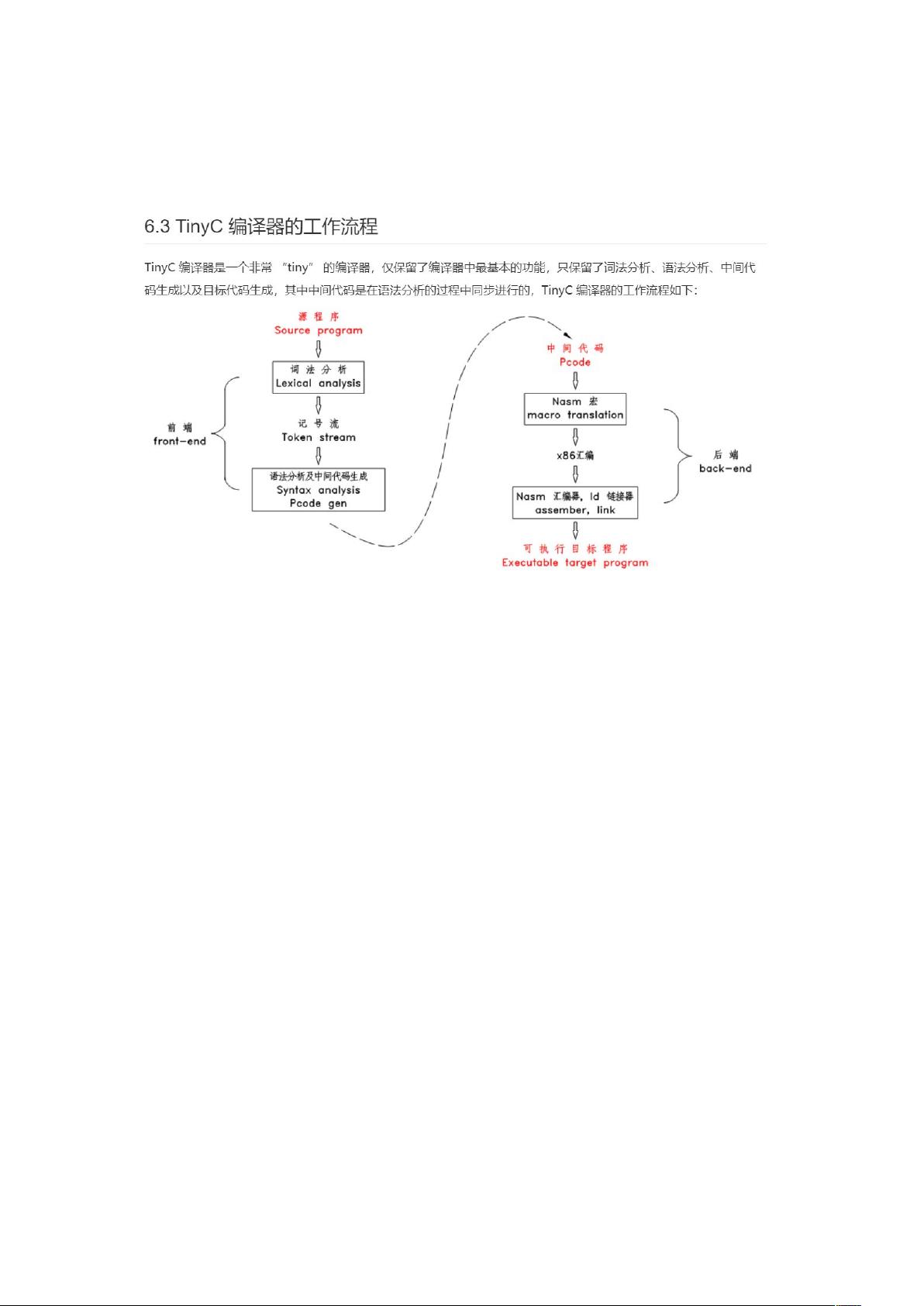
TinyC编译器是一个简化版的C语言编译器,其语法只包含C语言的基本元素,如int数据类型、void和int作为函数返回值,单行和多行注释,预定义的print和readint函数,以及有限的控制结构(if, while)。变量必须先声明再使用,且不支持直接初始化,程序需包含main函数作为起点。TinyC语言的运算符包括基本的算术、比较和逻辑操作。
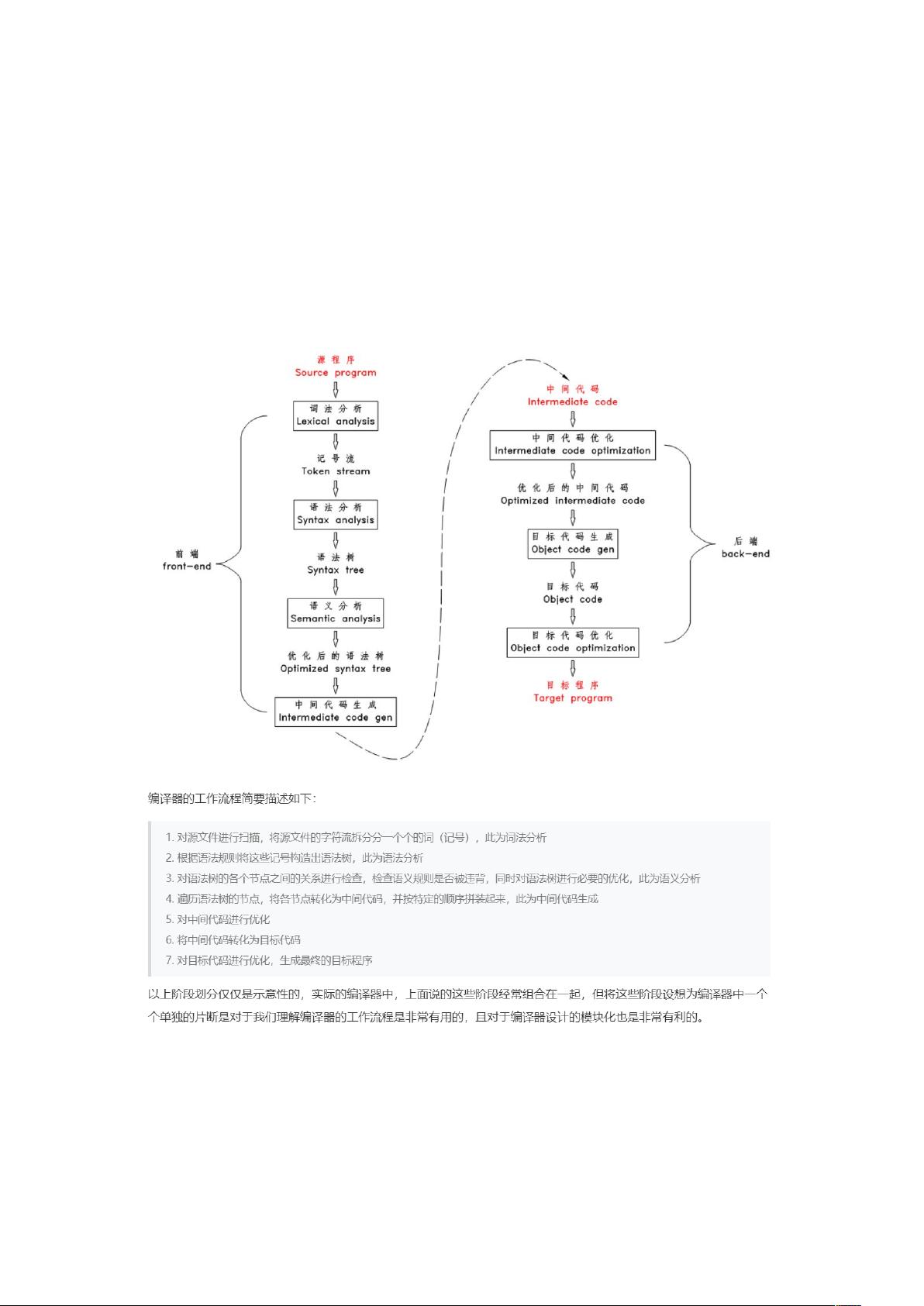
编译器架构部分讨论了完整的编译器的组成,包括词法分析器、语法分析器、中间代码生成器和目标代码生成器。TinyC编译器的架构展示了一个简单的流程,从源代码到最终的机器码,涉及扫描、规约、碎化、宏编译、连接和运行等多个阶段。
核心编译技术部分深入讲解了词法分析、语法分析、中间代码生成和目标代码生成。词法分析是将源代码拆分成一个个独立的符号或token;语法分析利用bison生成的解析器对这些token进行解析,形成抽象语法树;中间代码生成是为了简化问题,提高代码的可移植性和优化可能性;目标代码生成则涉及到汇编语言,例如使用NASM宏进行指令编写,将中间代码转化为特定机器的机器码。
在NASM宏的示例中,展示了如何定义和使用宏来简化指令序列,如add0和sub0宏,它们分别用于实现加法和减法操作,这种宏的使用可以提高代码的可读性和复用性。
这份答辩材料详细阐述了编译器的工作原理和TinyC编译器的设计实现,对于理解和研究编译器技术具有很高的参考价值。
三.编译器架构
3.1 完整的编译器
剩余53页未读,继续阅读
2023-08-05 上传
2021-12-05 上传
2022-01-24 上传
293 浏览量
2024-07-30 上传
2024-07-30 上传

Mario:)
- 粉丝: 55
 我的内容管理
展开
我的内容管理
展开







最新资源
- Win7系统下的一键式笔记本显示器关闭解决方案
- 免费替代Visio的流程图软件:DiaPortable
- Polymer 2.0封装的LineUp.js交互式数据可视化库
- Kotlin编写的Linux Shell工具Kash:强大而优雅的命令行体验
- 开源海军贸易模拟《OpenPatrician》重现中世纪北海繁荣
- Oracle 11g 32位客户端安装与链接指南
- 创造js实现的色彩识别小游戏「看你有多色」
- 构建Mortal Kombat Toasty展示组件:Stencil技术揭秘
- 仿驱动之家触屏版手机wap硬件网站模板源码
- babel-plugin-inferno:JSX转InfernoJS vNode插件指南
- 软件开发中编码规范的重要性与命名原则
- 免费进销存软件的两个月试用体验
- 树莓派从A到Z的Linux开发完全指南
- 晚霞天空盒资源下载 - 美丽实用的360度全景贴图
- perfandpubtools:MATLAB性能分析与发布工具集
- WPF圆饼图控件源代码分享:轻量级实现
