HashMap详解:数据结构与源码分析
需积分: 10 31 浏览量
更新于2024-07-20
收藏 847KB PPT 举报
HashMap是一种基于哈希表的数据结构,它是Java中实现Map接口的常用实现之一。HashMap在Java 1.8中提供了高效、灵活的键值存储,支持null键和null值,并且不保证映射的顺序性。其内部数据结构是由数组和链表(在碰撞较多时转换为红黑树)组成的。
HashMap的关键属性包括:
1. **capacity**:HashMap的桶数量,初始化默认为16,后续扩容时会翻倍至2的幂。容量决定了哈希函数的计算范围。
2. **size**:存储的键值对数量,即Node的数量。
3. **loadFactor**:装载因子,衡量HashMap的填充程度,默认值为0.75,表示当size达到capacity的loadFactor时会触发扩容。
4. **threshold**:当size大于threshold时,HashMap会进行resize操作。threshold等于capacity乘以loadFactor。
HashMap有四种构造方法,其中一种接受用户自定义初始容量和默认loadFactor,会检查容量的有效性并计算出新的threshold。
核心的两个函数是:
- **Hash()函数**:计算键的散列值,用于确定键在哈希表中的位置。这个函数在键的数量超过2的16次方时才发挥作用,且经过优化,旨在减少哈希冲突。
- **Resize()函数**:当HashMap需要扩展时,这个函数负责调整数据结构的大小,确保键值对均匀分布在新的桶中。新表中,旧元素可能保持原位置或移动到新位置。
插入键值对(put)的过程涉及以下步骤:
1. 接收键值对。
2. 计算键的散列值,根据哈希函数确定其在数组中的初始位置。
3. 在该位置查找键,若不存在则插入一个新的Node;若存在,处理哈希冲突,通过链表或红黑树的方式存储冲突的键值对。
4. 插入完成后,更新size。
总结来说,HashMap的核心原理是利用散列函数将键快速定位到存储桶,通过数组、链表或红黑树结构处理哈希冲突,以保证插入和查找操作的时间复杂度在平均情况下为O(1)。理解HashMap的内部机制有助于深入学习和优化Map类的使用,特别是在处理大数据集时。
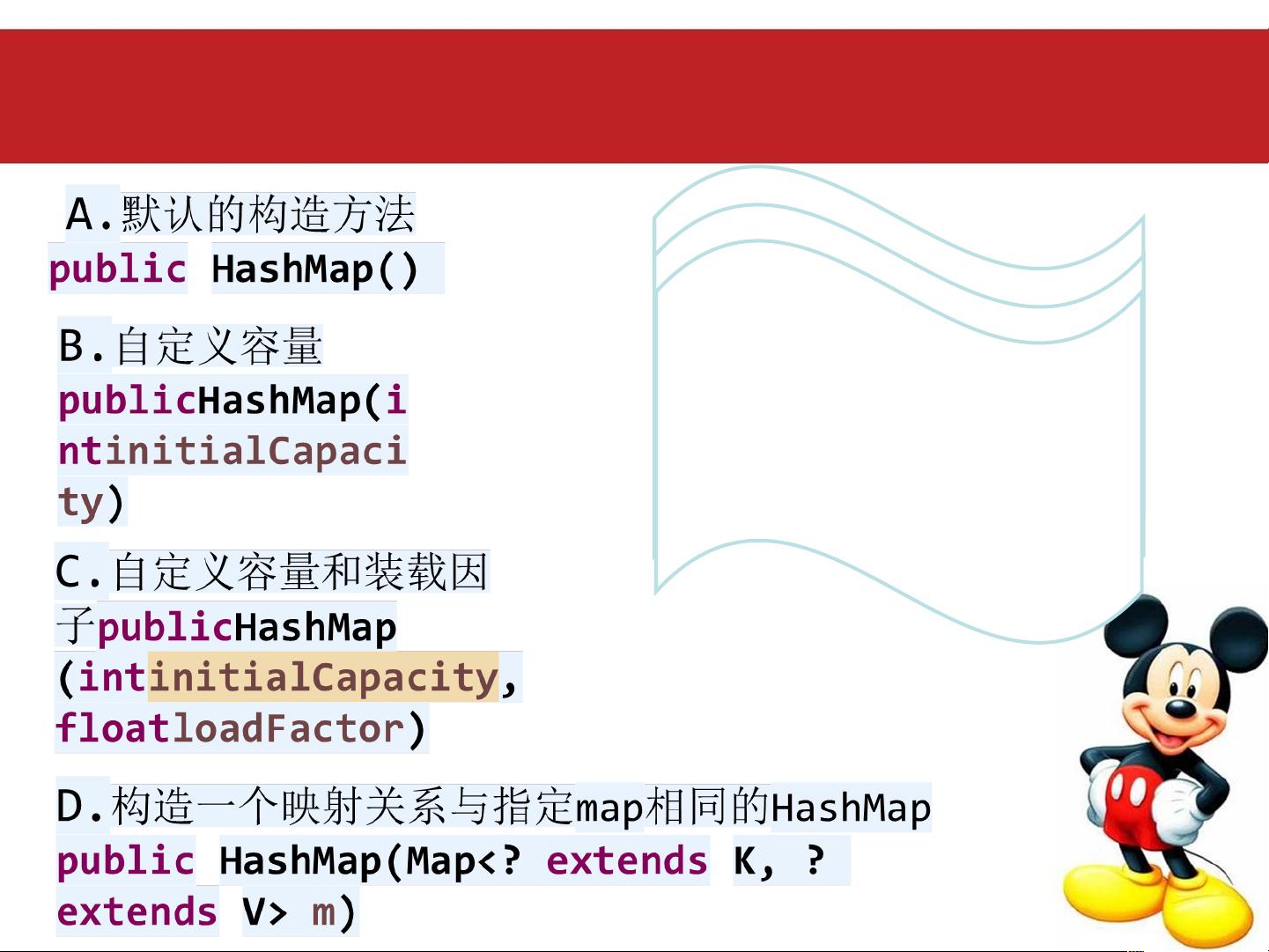
HashMap 四种构造方法
容量 = 16
装载因子 =0.75
this(initialCapacity,
DEFAULT_LOAD_FACTOR);
调用了重载方法 传入了自定义容
量和默认的加载因子
判断传入的自定义容量是否合法
重新计算阈值
剩余16页未读,继续阅读
点击了解资源详情
112 浏览量
点击了解资源详情
221 浏览量
209 浏览量
932 浏览量

NoClay
- 粉丝: 54
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







