MapReduce编程模型与实现解析
需积分: 12 41 浏览量
更新于2024-07-26
收藏 586KB PDF 举报
"MapReduce是Hadoop框架中的一个分布式计算模型,用于处理和生成大规模数据集。该模型基于函数式编程理念,旨在简化大规模数据处理的复杂性,并能有效地利用分布式计算环境。"
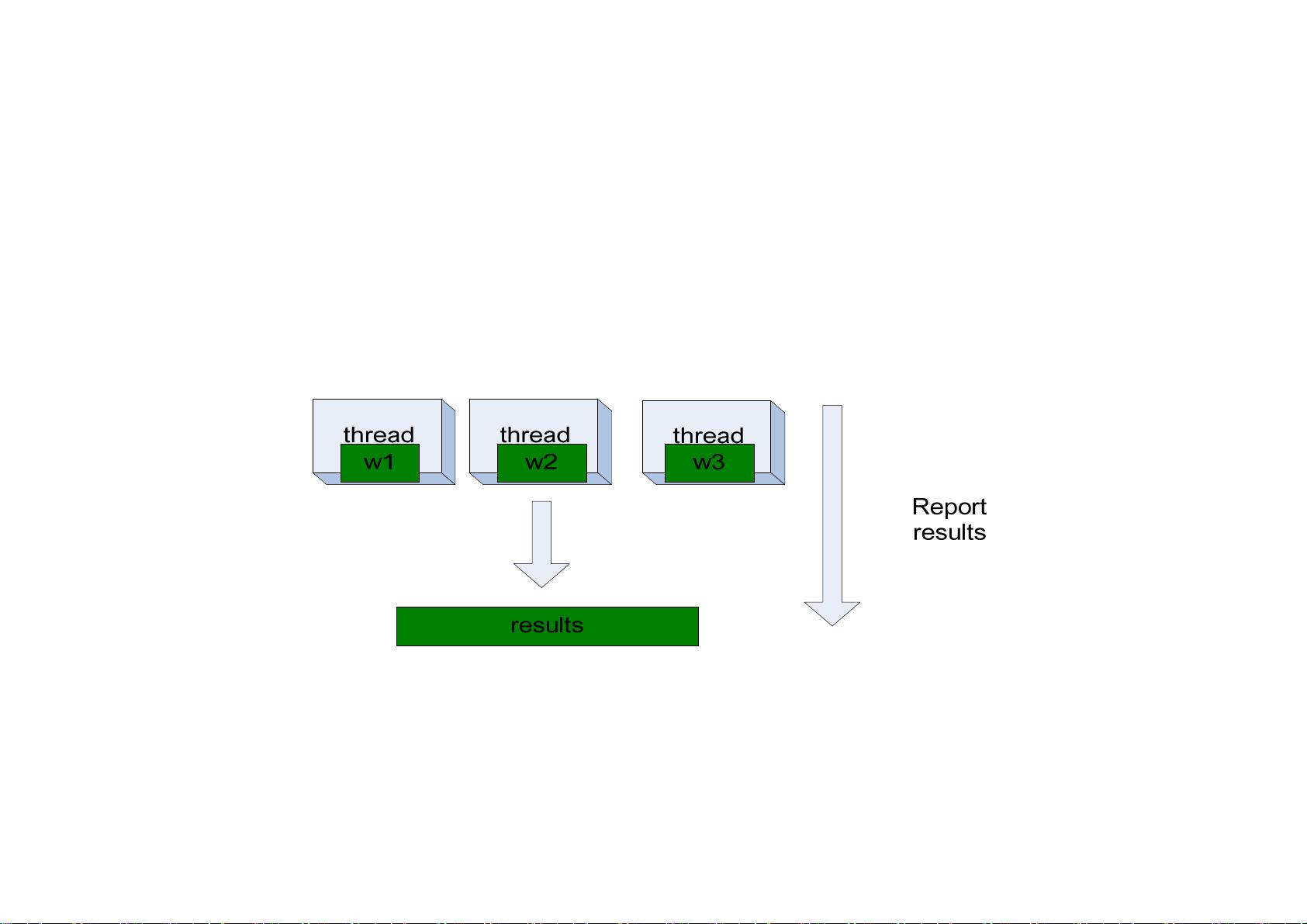
MapReduce的核心在于两个主要操作:Map和Reduce。Map阶段将输入数据集切分成多个小块,然后在各个计算节点上并行处理这些数据块。每个节点应用用户定义的映射函数,将原始数据转换为键值对形式。这一阶段的结果是大量的中间键值对。
Reduce阶段则负责聚合Map阶段产生的中间键值对。系统通过分区和排序中间结果,确保相同键的所有值被传递到同一个Reduce任务。然后,用户定义的归约函数会在每个键的所有值上执行,产生最终的输出。这个过程有助于确保计算的正确性和一致性。
并行化是MapReduce效率的关键。为了处理海量数据,它将工作负载分布到多台计算机(称为节点)组成的集群上。这种分布式计算模型能够显著减少处理时间。例如,对于Google这样的大型数据集,单机处理可能需要数月,而使用MapReduce可以在三小时或更短的时间内完成。
MapReduce处理的问题包括但不限于单词计数、搜索匹配(Grep)、创建倒排索引、数据排序等。它适合处理亿级别以上的数据量,并且能够在包含数千甚至上万台节点的集群上运行。
MapReduce的设计还考虑了容错性。当某个节点发生故障时,系统能够自动检测并重新分配任务给其他健康的节点,保证计算的连续性。此外,为了确保所有工作已完成并汇总结果,MapReduce会跟踪任务的进度,并在所有任务完成后进行结果整合。
函数式编程在MapReduce中起到关键作用,因为其避免了数据的修改(即不可变性),使得并行计算更为简单。运算顺序的无关性使得任务可以自由地在不同节点上执行,而函数作为参数的特性则允许将用户定义的计算逻辑(如Map和Reduce函数)轻松地应用于大规模数据。
总结来说,MapReduce是一种解决大数据处理问题的高效工具,它借鉴了函数式编程的特性,结合分布式计算的优势,提供了一种抽象且易于编程的模型,使开发者能够专注于业务逻辑,而不是底层的并行计算细节。随着大数据和云计算的发展,MapReduce的实现和优化持续进行,以适应不断变化的计算需求和未来的挑战。


119 浏览量
615 浏览量
239 浏览量
214 浏览量
443 浏览量
169 浏览量

lsw0930
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高速电路设计 A Practical Guide to High-Speed Printed-Circuit-Board
- 2006年4月二级C语言笔试试题.doc
- 华为编程规范.pdf
- Tapestry开发指南.pdf
- liferay portlet二次开发宝典
- C#自学笔记(崔北为)
- 一些软件公司的笔试题
- FORTRAN 77
- STATA 面板数据处理
- Beginning PHP and Oracle From Novice to Professional.2007
- C#,深入浅出全接触
- C#.NET 开发者手册
- 2410根文件系统实验
- C# Language Specification
- Flex 3 Cookbook 中文版.pdf
- s3c2410uboot移植实验
