Kafka消息格式演进揭秘:从v0到v1的优化与挑战
169 浏览量
更新于2024-08-29
收藏 226KB PDF 举报
一文看懂Kafka消息格式的演变
Kafka作为一款重要的开源流处理平台,消息格式的演进反映了其核心功能和性能优化的不断提升。从0.8.x版本到1.1.x,Kafka的消息格式经历了三个主要阶段,这些版本之间的变化不仅涉及功能扩展,还直接影响性能表现。
v0版本(Kafka 0.10.0之前):
- 这是Kafka消息格式的早期版本,消息结构包括固定的"RECORD"部分,其中包含offset(逻辑偏移量)和messagesize(消息大小)两个字段。这两个字段构成了日志头部,对记录进行标识。offset用于定位消息在分区中的位置,但并非物理偏移,而是逻辑上的顺序标记。
v1版本(0.8.x - 0.10.x):
- 在这个版本中,Kafka引入了timestamp字段,解决了v0版本中的问题。尽管最初版本中没有这个字段,它在后续版本中被添加,以支持日志保存、切分策略以及消息审计等高级功能。时间戳的存在允许更精确的时间追踪,但也增加了解析消息的复杂性。为了减少解析开销,Kafka将时间戳存储在value字段前,通过指针偏移来快速访问,这种设计提高了性能。
性能优化与冗余字段:
- 避免冗余字段是优化性能的关键。例如,过长的消息体可能导致存储和网络传输开销增加,进而影响整体性能。Kafka在设计时力求精简消息结构,避免不必要的字段,以实现更高效的存储和数据传输。
分区管理与水平扩展:
- 每条消息在发送到Kafka时,会依据特定规则被分配到一个或多个分区。合理的分区策略有助于消息均匀分布,从而支持水平扩展。分区大小的优化与消息格式紧密相关,过度的冗余字段会导致分区变大,降低扩展性。
总结:
- Kafka的消息格式演变体现了技术的不断迭代和优化。从v0版本的简单记录结构,到v1版本引入时间戳并优化解析,Kafka在追求功能性和性能之间找到了平衡。理解这些演变有助于开发者更好地利用Kafka进行高效的消息处理和系统设计。
一文看懂一文看懂Kafka消息格式的演变消息格式的演变
摘要
对于一个成熟的消息中间件而言,消息格式不仅关系到功能维度的扩展,还牵涉到性能维度的优化。随着Kafka的迅猛发展,
其消息格式也在不断的升级改进,从0.8.x版本开始到现在的1.1.x版本,Kafka的消息格式也经历了3个版本。本文这里主要来
讲述Kafka的三个版本的消息格式的演变,文章偏长,建议先关注后鉴定。
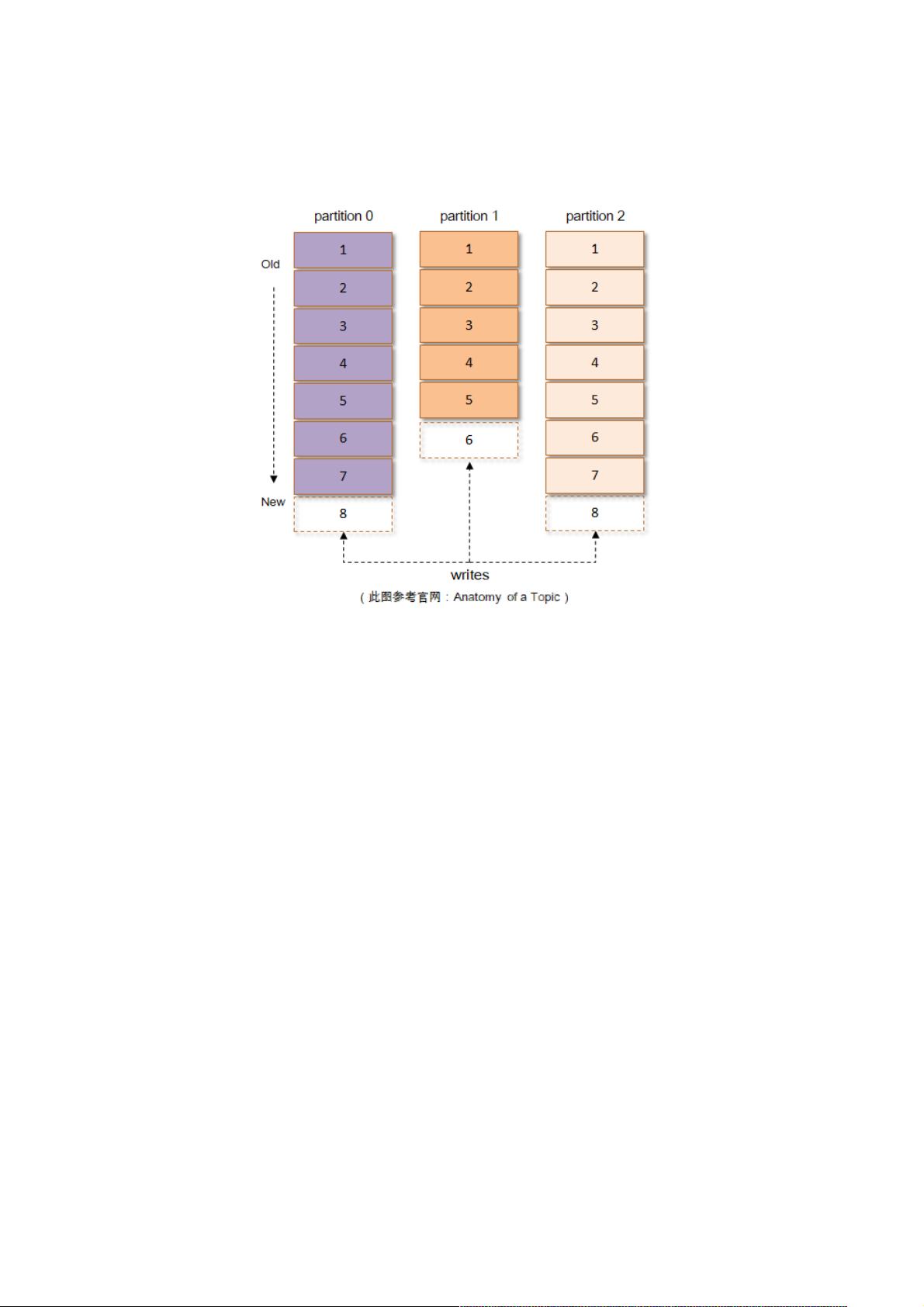
每一条消息被发送到Kafka中,其会根据一定的规则选择被存储到哪一个partition中。如果规则设置的合理,所有的消息可以
均匀分布到不同的partition里,这样就实现了水平扩展。如上图,每个partition由其上附着的每一条消息组成,如果消息格式
设计的不够精炼,那么其功能和性能都会大打折扣。比如有冗余字段,势必会使得partition不必要的增大,进而不仅使得存储
的开销变大、网络传输的开销变大,也会使得Kafka的性能下降;又比如缺少字段,在最初的Kafka消息版本中没有timestamp
字段,对内部而言,其影响了日志保存、切分策略,对外部而言,其影响了消息审计、端到端延迟等功能的扩展,虽然可以在
消息体内部添加一个时间戳,但是解析变长的消息体会带来额外的开销,而存储在消息体(参考下图中的value字段)前面可
以通过指针偏量获取其值而容易解析,进而减少了开销(可以查看v1版本),虽然相比于没有timestamp字段的开销会差一
点。如此分析,仅在一个字段的一增一减之间就有这么多门道,那么Kafka具体是怎么做的呢?本文只针对Kafka 0.8.x版本开
始做相应说明,对于之前的版本不做陈述。
v0版本
对于Kafka消息格式的第一个版本,我们把它称之为v0,在Kafka 0.10.0版本之前都是采用的这个消息格式。注意如无特殊说
明,我们只讨论消息未压缩的情形。
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-07 上传
2018-09-07 上传
2024-08-23 上传
2022-08-15 上传
2021-01-07 上传

weixin_38584642
- 粉丝: 5
- 资源: 945
 我的内容管理
展开
我的内容管理
展开







最新资源
- myilportfolio
- GH1.25连接器封装PCB文件3D封装AD库
- Network-Canvas-Web:网络画布的主要网站
- 基于机器学习和LDA主题模型的缺陷报告分派方法的Python实现。原论文为:Accurate developer r.zip
- ReactBlogProject:Blog项目,测试模块,React函数和后端集成
- prefuse-caffe-layout-visualization:杂项 BVLC Caffe .prototxt 实用程序
- thresholding_operator:每个单元基于阈值的标志值
- 基于深度学习的计算机视觉(python+tensorflow))文件学习.zip
- app-sistemaweb:sistema web de citas medicasRuby在轨道上
- 记录书籍学习的笔记,顺便分享一些学习的项目笔记。包括了Python和SAS内容,也包括了Tableau、SPSS数据.zip
- bpm-validator:Bizagi BPM 验证器
- DocBook ToolKit-开源
- file_renamer:通过文本编辑器轻松重命名文件和文件夹
- log4j-to-slf4j-2.10.0-API文档-中文版.zip
- django-advanced-forms:Django高级脆皮形式用法示例
- android-sispur
