FPGA上的LDPC解码器:一项综合调查
需积分: 9 127 浏览量
更新于2024-07-19
收藏 3.6MB PDF 举报
"A Survey of FPGA-Based LDPC Decoders"
这篇论文深入探讨了基于FPGA(Field-Programmable Gate Array,现场可编程门阵列)的低密度奇偶校验(Low-Density Parity Check,LDPC)解码器的设计关键因素,并对当前文献进行了广泛的回顾。LDPC解码器在通信系统中广泛应用,因其出色的错误校正性能和适合并行硬件实现而受到青睐。研究者们投入大量精力设计能充分利用FPGA灵活性、高速处理能力和并行性的LDPC解码器。
FPGA设备在设计原型和小批量生产设备制造方面具有优势,因为它们的在系统可编程性使得其成本效益远超ASIC(Application-Specific Integrated Circuit,专用集成电路)。然而,公开文献中发布的FPGA基LDPC解码器设计在设计选择和性能指标上存在很大差异,这使得对比分析变得困难。论文对140个已发表的设计(包括学术界和工业界的)进行了深入比较,分析了相关性能权衡,并指出了七个关键性能特征:
1. 处理吞吐量:衡量解码器在单位时间内可以处理的数据量。
2. 处理延迟:从接收到数据到完成解码所需的时间。
3. 硬件资源需求:解码器所需的逻辑资源,如逻辑单元、存储器等。
4. 错误校正能力:解码器能够纠正的错误程度或错误率。
5. 处理能量效率:解码器在执行任务时的功耗与性能之间的关系。
6. 带宽效率:解码器利用输入/输出带宽的能力。
7. 灵活性:解码器适应不同编码参数或操作条件的能力。
论文提供了一些建议,以促进未来设计的公平比较,并为改进FPGA基LDPC解码器的设计提供了机会。这些设计不仅涉及技术层面,还涵盖了算法优化、资源分配和架构创新等多个方面,旨在提升解码器的性能和效率。通过对这些性能特性的分析,研究人员和工程师能够更好地理解各种设计决策的影响,从而推动LDPC解码器技术的进一步发展。

IEEE COMMUNICATIONS SURVEYS AND TUTORIALS 5
achieves a strong error correction capability is a complex task,
so this is usually the first aspect of the code to be designed.
Following this, the generator matrix G can be derived from
H, by following the reverse of the process described above.
3) Factor graphs: The PCM H can also be visualised
graphically using a factor graph, which is also known as a
Tanner graph [18]. This is exemplified in Fig. 4 for the PCM
of (13). A factor graph is comprised of two sets of connected
nodes, namely N Variable Nodes (VNs) for representing the
columns of H and M Check Nodes (CNs) for representing
the rows.
˜
P
1
v
1
˜
P
2
v
2
˜
P
3
v
3
˜
P
4
v
4
˜
P
5
v
5
˜
P
6
v
6
˜
P
7
v
7
˜
P
8
v
8
˜
P
9
v
9
˜
P
10
v
10
c
1
c
2
c
3
c
4
Variable nodes
Edges
Check nodes
˜q
4−1
˜r
4−9
Fig. 4. A factor graph for an example LDPC code
The connections
˜
P
i
above each VN in Fig. 4 pertain to
LLRs associated with the N codeword bits of ˆc. An edge
connects the i-th VN v
i
to the j-th CN c
j
if there is a non-
zero element in the i-th column and j-th row of H, H
ji
= 1.
To illustrate this, all of the edges that are connected to the 1
st
CN c
1
in Fig. 4 are shown with thicker lines. These edges are
connected to the 1
st
, 4
th
, 5
th
, 9
th
and 10
th
VNs, in accordance
to the position of the 1s in the top row of H in (13).
The degree of a node is defined as the number of other nodes
that it is connected to and is equal to the corresponding row or
column weight in H. The degree of the CNs D
c
and the degree
of the VNs D
v
are important parameters in an LDPC code. If
all CNs have the same degree D
c
and all VNs have the same
degree D
v
, the LDPC code is said to be regular. If either value
varies from node to node, the code is said to be irregular and
D
c
and D
v
can be expressed as the average degree over all
nodes. For example, the factor graph of Fig. 4 is irregular with
D
c
= 5.75 and D
v
= 2.3. In any case, the number of 1s in
the PCM H must be the same regardless, whether it is viewed
row-by-row or column-by-column, giving D
c
×M = D
v
×N ,
with D
v
= D
c
× (1 − R).
C. LDPC decoding
LDPC codes are typically decoded using a belief propa-
gation (BP) algorithm in which messages – typically in the
form of LLRs – are iteratively passed in both directions along
the edges between connected nodes [19]. For example, Fig. 4
illustrates a message ˜q
4−1
sent from the 4
th
VN v
4
to the 1
st
CN c
1
, while the message ˜r
4−9
is sent from the 4
th
CN c
4
to the 9
th
VN v
9
. The messages provided as inputs to a node
are processed by activating that node, causing it to create new
output messages that are sent back to the nodes it is connected
to. Thus the processing of the LDPC decoder is delegated to
the many individual calculations performed by the individual
nodes, rather than being a single monolithic global equation.
An important facet of the belief propagation algorithm is that
any message sent to a particular node does not depend on
the message received from that node. For example, CN c
2
is connected to VNs v
2
, v
3
, v
5
, v
8
and v
10
; however, the
message ˜r
2−5
it sends to v
5
will be calculated based only
on the messages it has received from v
2
, v
3
, v
8
and v
10
.
Nodes are activated in an order determined by the LDPC de-
coder’s schedule. This has a significant effect upon the LDPC
decoder’s error correction capability, as well as on its other
characteristics. Many different schedules exist and the most
common options will be outlined in Section II-C1. Following
this, variations of the specific calculations performed within
CNs and VNs will be presented in Sections II-C2 and II-C3
respectively.
1) Scheduling: The schedule of the LDPC decoding pro-
cess determines the order in which VNs and CNs are pro-
cessed, as well as whether multiple nodes are processed in
parallel. Many scheduling variations exist, but the three most
common schedules are described here, namely flooding [20],
Layered Belief Propagation (LBP) [21] and Informed Dynamic
Scheduling (IDS) [22].
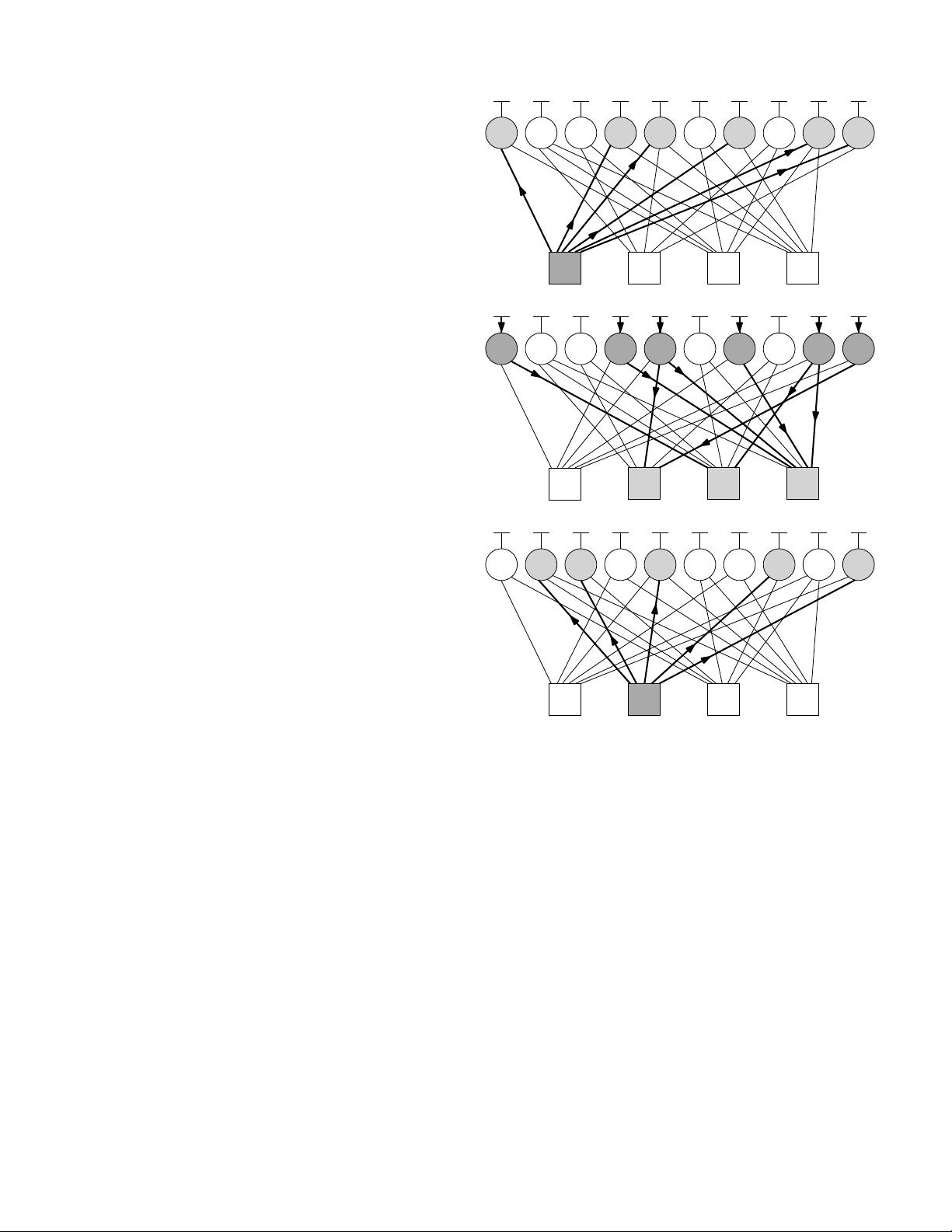
Flooding is perhaps the most conceptually simple LDPC
decoding schedule. Here, the factor graph is processed in an
iterative manner, where each iteration comprises the simul-
taneous activation of all CNs, followed by the simultaneous
activation of all VNs [19]. An example of this schedule is
depicted in Fig. 5. It can be seen that at first the CNs c
1
–c
4
shown in dark grey calculate their messages, which are then
˜
P
1
v
1
˜
P
2
v
2
˜
P
3
v
3
˜
P
4
v
4
˜
P
5
v
5
˜
P
6
v
6
˜
P
7
v
7
˜
P
8
v
8
˜
P
9
v
9
˜
P
10
v
10
c
1
c
2
c
3
c
4
˜
P
1
v
1
˜
P
2
v
2
˜
P
3
v
3
˜
P
4
v
4
˜
P
5
v
5
˜
P
6
v
6
˜
P
7
v
7
˜
P
8
v
8
˜
P
9
v
9
˜
P
10
v
10
c
1
c
2
c
3
c
4
Fig. 5. An example of the flooding schedule
剩余25页未读,继续阅读
2022-07-13 上传
2021-02-07 上传
2021-02-07 上传
2021-02-09 上传
2021-06-16 上传
2021-05-22 上传
2017-10-23 上传
2021-05-02 上传
2021-06-01 上传

斩月904
- 粉丝: 77
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
