使用Halcon 10进行图像分类:GMM、SVM与神经网络算法解析
"Halcon 10 图像分类算法"
在机器视觉领域,Halcon是一种广泛使用的图像处理软件,尤其在图像分类方面具有强大的功能。Halcon 10 提供了多种算法来应对图像分类任务,包括高斯混合模型(GMM)、支持向量机(SVM)以及神经网络。这些算法在不同场景下各有优势,可以根据具体需求选择合适的分类方法。
1. **高斯混合模型(GMM)**:
GMM 是一种统计建模技术,它假设数据由多个高斯分布混合而成。在图像分类中,GMM 可用于对像素或特征进行建模,通过学习各个类别的概率分布,将新图像分配到最匹配的类别。GMM 的优点在于它能处理多峰分布,并且在有限的数据集上也能表现良好。
2. **支持向量机(SVM)**:
SVM 是一种监督学习模型,其目标是找到一个超平面,最大化不同类别之间的间隔。在图像分类中,SVM 可以通过学习训练样本的特征向量,构建决策边界来区分不同类别。SVM 对于非线性可分问题有很好的处理能力,且在小样本情况下表现优秀。
3. **神经网络**:
神经网络是一种模拟人脑神经元结构的计算模型,可以用于图像分类、物体识别等复杂任务。在Halcon 10中,可能包含前馈神经网络和卷积神经网络(CNN)。前馈网络适用于一般的特征学习,而CNN则特别适合图像处理,因为它可以自动学习和提取图像的局部特征。CNN通过多层结构和池化操作,提高了对图像内容的理解能力。
在实际应用中,Halcon 提供的这些分类方法不仅限于单独使用,还可以结合使用,以达到更优的分类效果。例如,可以先用SVM初步分类,然后用神经网络进行细粒度分类。用户可以通过调整算法参数、优化网络结构以及选择合适的训练策略,来提升分类的准确性和鲁棒性。
Halcon 的解决方案指南提供了详细的使用教程,指导用户如何配置和训练这些分类算法。用户可以学习如何准备训练数据、设置模型参数、评估模型性能以及如何将模型部署到实际应用中。此外,手册还可能包含实例代码和示例图像,帮助用户快速上手并理解分类过程。
对于想要深入了解Halcon 10 图像分类的用户,建议访问官方网址 http://www.halcon.com/ 获取更多详细信息、文档和最新资源,以便更好地利用这些强大的工具解决实际问题。同时,Halcon 还可能涉及到其他专利技术,使用时需遵守相关法律法规。

D-16 Classification: Theoretical Background
Figure 3.1: Region features of oranges and lemons are extracted and can be added as samples to the
classifier.
a feature space can have any dimension, depending on the number of features contained in the feature
vector. For visualization purpose, here a 2D feature space is shown. In practice, feature spaces of higher
dimension are very common.
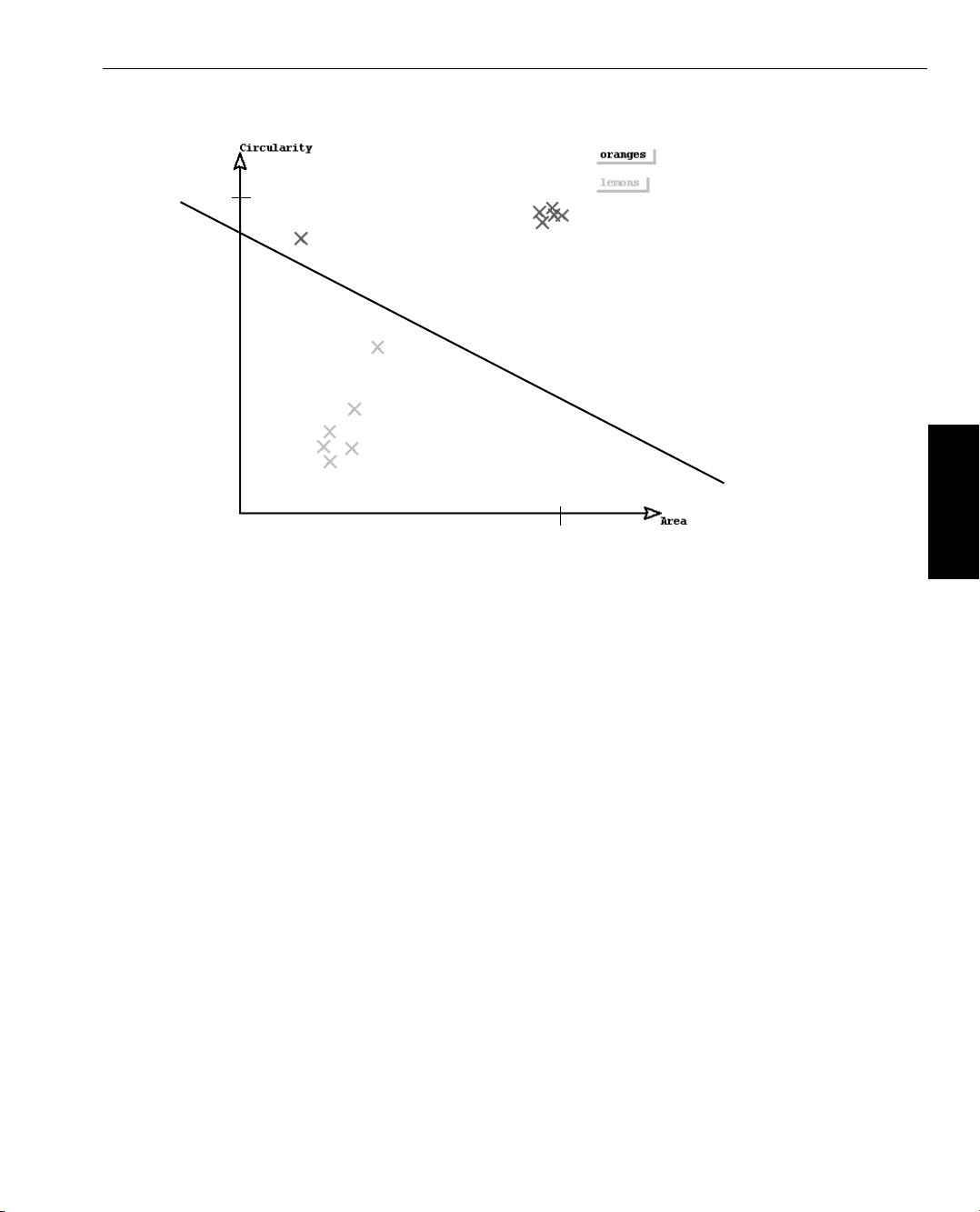
In figure 3.2 the feature vectors of the fruits shown in figure 3.1 are visualized in a 2D graph, for which
one axis represents the ’area’ values and the other axis represents the ’circularity’ values. Al-
though the regions vary in size and circularity, we can see that they are similar enough to build clusters.
The goal of a classifier is to separate the clusters and to assign each feature vector to one of the clusters.
Here, the oranges and lemons can be separated, e.g., by a straight line. All objects on the lower left side
of the line are classified as lemons and all objects on the upper right side of the line are classified as
oranges.
As we can see, the feature vector of a very small orange and that of a rather circular lemon are close to
the separating line. With a little bit different data, e.g., if the small orange additionally would be less
circular, the feature vectors may be classified incorrectly. To minimize errors, a lot of different samples
and in many cases also additional features are needed. An additional feature for the citrus fruits may
be, e.g., the gray value. Then, not a line but a plane is needed to separate the clusters. If color images
剩余115页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-04-18 上传
点击了解资源详情
点击了解资源详情
2024-06-26 上传
2021-09-12 上传
2009-07-10 上传

starluckwang
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 802.16入网退避算法的设计
- iso C99 standard
- MiniGUI编程指南
- 计算机操作系统(汤子瀛)习题答案
- 《构建高性能Web站点》节选 - 动态脚本加速 - 避免重复编译.pdf
- D语言参考文档,第二版
- 民航订票系统 软件工程
- Oracle Database 10g - DBA
- S3C2410 linux 移植中文手册
- Java语言编码规范(pdf)
- D语言参考手册,第一版
- Data Mining: Practical Machine Learning Tools and Techniques
- jms规范教程,JMS相当的技术规范
- MPEG数字视音频压缩编码原理及应用
- 2008年网络原理试题
- 图形学实验题目(08年)
