支持向量机回归教程:算法与应用
"这篇教程是关于支持向量回归(Support Vector Regression, 简称SVR)的介绍,由Alex J. Smola和Bernhard Scholkopf撰写,属于GMD NeuroCOLT技术报告系列。文章涵盖了SVR的基本概念、训练算法以及处理大规模数据集的高级方法,并提到了一些对SVR的改进和扩展。"
支持向量机(Support Vector Machines, SVM)最初是作为分类工具被提出的,但后来发展出支持向量回归(Support Vector Regression, SVR)以应对连续变量预测问题。在SVR中,模型的目标是找到一个能够最小化预测值与真实值之间误差的超平面。这个超平面通过最大化与最近的数据点(称为支持向量)的距离来确定,从而确保模型具有良好的泛化能力。
本文首先介绍了SVR的基本思想:通过构造一个间隔最大化的边界来拟合数据,这个边界可以容忍一定程度的误差,即ε-范数损失函数。ε-范数允许在模型预测值与实际值之间存在一定的差距(ε-tube),只要大部分数据点在这个范围内,模型就被认为是有效的。
接着,教程详细讲解了训练SVR的算法。最常用的是基于凸优化问题的Quadratic Programming(QP)求解器,这包括解决线性可分情况下的硬间隔最大化和非线性情况下的软间隔最大化。对于非线性问题,SVM通常采用核技巧,如高斯核(RBF)、多项式核或Sigmoid核,将数据映射到高维空间,使得原本在原始空间中难以分离的数据在新空间中变得容易处理。
对于大规模数据集,传统的QP方法可能会面临计算复杂性和内存限制。因此,文章提到了一些高效算法,如Sequential Minimal Optimization (SMO) 和 Cutting Plane Methods,它们能够在训练过程中有效地处理大量数据,同时保持较好的性能。
最后,作者讨论了对SVR的一些修改和扩展,例如引入惩罚项以控制模型复杂度,防止过拟合;或者使用在线学习算法进行增量训练,适应动态数据流。此外,他们还可能涉及了多任务学习、异常检测等应用场景,以及如何结合其他机器学习方法提升SVR的性能。
这篇教程对于理解支持向量回归的核心原理及其在实际应用中的优化策略具有很高的参考价值,适合对机器学习和统计建模感兴趣的读者深入学习。

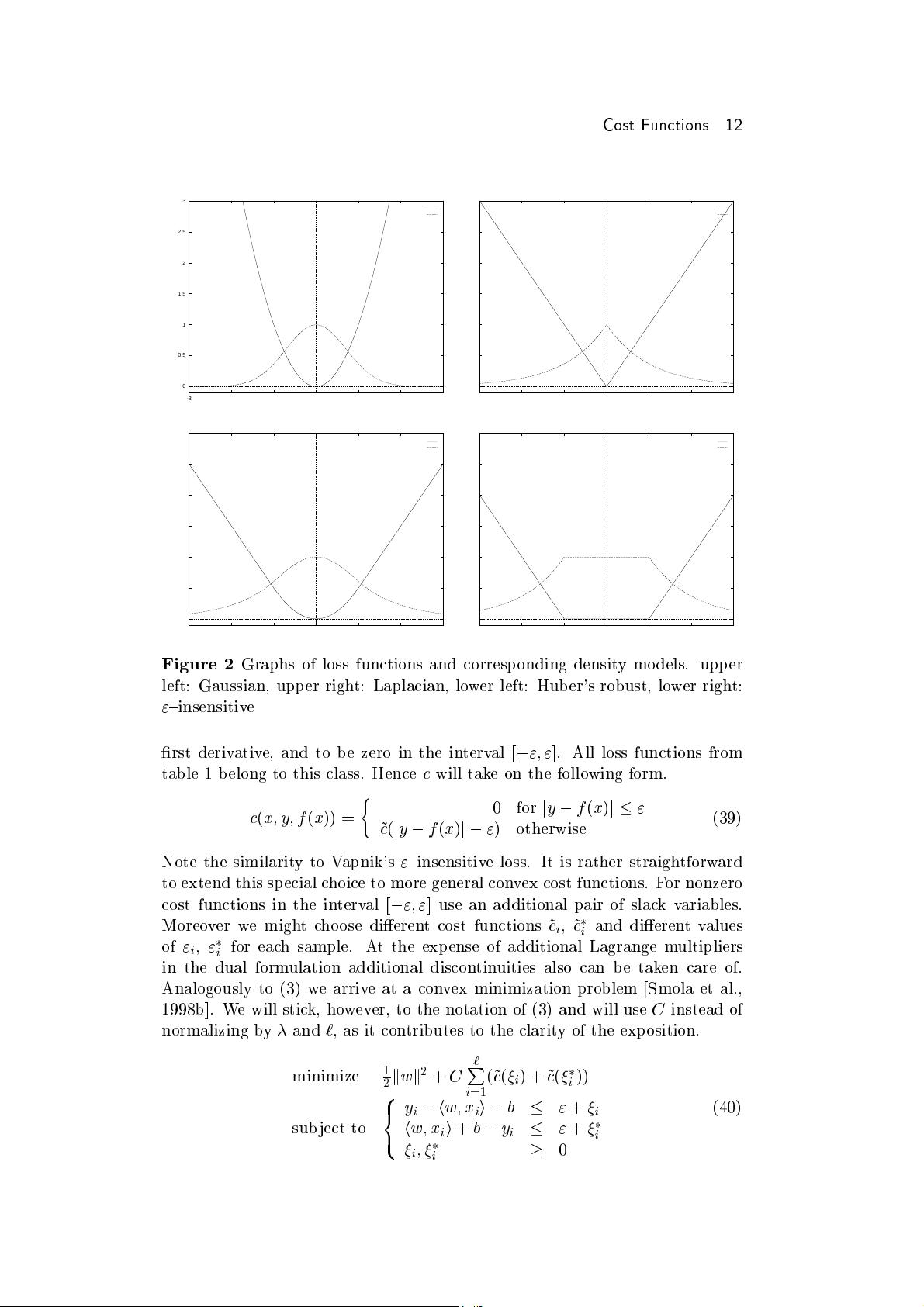
Cost Functions 10
instance when dealing with few data in very high-dimensional spaces, this may
not be a good idea, as it will lead to overtting and thus bad generalization
prop erties. Hence one should add a capacity control term, whichintheSVcase
results to b e
k
w
k
2
, which leads to the regularized risk functional Tikhonov and
Arsenin, 1977, Morozov, 1984, Vapnik, 1982]
R
reg
f
]:=
R
emp
f
]+
2
k
w
k
2
(33)
where
>
0isaso called
regularization
constant. Many algorithms like regu-
larization networks Girosi et al., 1993] or weight decay networks Bishop, 1995]
minimize an expression similar to (33).
5
3.2 Maximum Likeliho o d and Density Mo dels
Now the question arises, which cost functions
c
(
x y f
(
x
)) should be used in
(33). The standard setting in the SV case is, as already mentioned in section
1.2,
c
(
x y f
(
x
)) =
j
y
;
f
(
x
)
j
"
:
(34)
It is straightforward to show, that minimizing (33) with the particular loss
function of (34) is equivalenttominimizing (3), the only dierence b eing that
C
=1
=
(
`
).
Loss functions suchlike
j
y
;
f
(
x
)
j
p
"
with
p>
1may not b e desirable, as the
sup erlinear increase leads to a loss of the robustness prop erties of the estimator
(see e.g. Hub er, 1981]): in those cases the derivative of the cost function may
grow without b ound. For
p<
1 the loss function b ecomes nonconvex.
For the case of
c
(
x y f
(
x
)) = (
y
;
f
(
x
))
2
we recover the least mean squares
t approach, which, unlike the standard SV loss function, leads to a matrix
inversion instead of a quadratic programming problem.
The question that now arises is which cost function should b e used in (33).
On the one hand we will want to avoid using a very complicated function
c
as this may lead to dicult optimization problems. On the other hand one
should use that particular cost function that suits the data b est. For instance
wemay b e given a cost function ~
c
by some real world problem, hence we should
use this particular one. Moreover, under the assumption that the samples
were generated by an underlying functional dep endency plus additive noise
y
i
=
f
true
(
x
i
)+
i
with density
p
(
) the optimal cost function in a maximum
likeliho od sense would b e
c
(
x y f
(
x
)) =
;
log
p
(
y
;
f
(
x
))
:
(35)
This can b e seen as follows. The likeliho od of an estimate
X
f
:=
f
(
x
1
f
(
x
1
))
:::
(
x
`
f
(
x
`
))
g
(36)
5
See Smola, 1998] for a discussion of other regularization terms and invariance properties
of quadratic regularization functionals.


剩余72页未读,继续阅读
2018-08-01 上传
2021-04-05 上传
2021-04-27 上传
点击了解资源详情
2024-12-26 上传

Lin-JM
- 粉丝: 1083
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- capistrano-memcached:Capistrano 任务用于自动和合理的内存缓存配置
- lab33-CAP-APWM,c#医院缴费系统源码,c#
- HBD-Chrome-Extension-crx插件
- IO_2020_2021_QuadclubApp:罗兹大学软件工程课程中实施的项目
- qr-code-generator-chrome-extension:Chrome扩展程序-一键QR代码生成器
- 美味
- StudentManagementSystem
- 龙卷风图:这会根据指定的灵敏度值创建龙卷风图。-matlab开发
- abc,c#bs框架源码,c#
- jerseywildfly:Projeto utilizando实现工具Eclipse Jersey https:eclipse-ee4j.github.io
- Create-Your-Own-Image-Classifier-Project-Submission:创建自己的图像分类器项目提交
- AzureDevOps
- distractor_neurons
- poject1:项目描述
- GCMT:Gentoo集群管理工具-开源
- stm32motor,c#开启动画源码,c#
