深度学习驱动的图像视频编码:现状与前景
87 浏览量
更新于2024-08-30
收藏 1.31MB PDF 举报
随着深度学习在人工智能领域的飞速发展,神经网络在图像视频编码领域的应用已成为研究焦点。这篇论文,由贾川民、赵政辉、王苫社和马思伟四位作者从北京大学出发,深入探讨了基于不同神经网络架构的图像和视频编码技术。
首先,他们梳理了多层感知机(Multi-layer Perceptron, MLP),一种基本的前馈神经网络,其在图像压缩中的应用。MLP通过学习输入数据的非线性映射,可以实现特征提取和量化,对于降低图像数据的复杂度起到关键作用。
接着,论文介绍了随机神经网络(Random Neural Network)的应用,这种网络结构通常用于处理不确定性和复杂的数据模式,对于图像编码中的噪声抑制和压缩算法有潜在价值。
卷积神经网络(Convolutional Neural Networks, CNN)是核心部分,由于其局部连接和权值共享特性,特别适合处理空间结构数据,如图像。CNN在图像编码中的应用包括特征提取、编码器-解码器结构以及最近流行的基于深度卷积的高效编码技术。
循环神经网络(Recurrent Neural Networks, RNN)因其在序列数据处理上的优势,也被应用于视频编码,尤其是视频帧间的预测和压缩编码,能够捕捉时间序列中的时序信息。
生成对抗网络(Generative Adversarial Networks, GANs)作为新兴的模型,它们不仅用于生成逼真的图像,也在视频编码中展现了潜力,通过生成器和判别器的竞争合作,优化编码效率并提升重建质量。
论文还概述了深度学习驱动的各种视频编码工具,这些工具利用端到端学习方法,能够自动优化编码过程,减少人工干预,提高了编码效率和压缩性能。
最后,作者对未来基于神经网络的图像视频编码技术的发展趋势进行了分析和展望。他们强调,随着硬件的进步和算法的不断优化,神经网络编码将更加高效、低功耗,可能还会出现集成多种网络结构的新型编码框架,以满足更高的视觉质量和实时性的需求。
总结来说,这篇论文为我们提供了对神经网络在图像视频编码领域广泛应用的深入理解,涵盖了多种基础和前沿技术,并为该领域的发展方向提供了有价值的洞见。
专题:智能通信技术及应用 ·34·
了一种基于参数共享的轻量级卷积神经网络用
于手写字识别任务。同期,为了解决时域信号梯
度计算复杂度过高以及信号依赖问题,Hochreiter
等人
[10]
提出长短期记忆(long short-term
memory,LSTM)结构,通过循环网络结构控制
梯度传递实现对序列信号的高效学习。Nair 等人
[11]
通过对受限玻兹曼机(restricted Boltzmann
machine,RBM)的每一层进行分层预训练,使
得深层的神经网络训练变得可能。在解释了
MLP 结构具有更为优异的特征学习能力的同
时,MLP 在训练上的复杂度还可以通过逐层
初始化和预训练来有效缓解。从此具有多隐含
层的 MLP 结构研究再次成为热点,而神经网
络也有了一个新的名称——深度学习(deep
learning,DL)。
神经网络作为优化算法以及信号紧凑表征形
式,与图像视频压缩结合的交叉研究早已有之。
本文梳理了相关技术的发展历史和现状,以神经
网络结构为主线对基于神经网络的图像压缩进行
了系统性的介绍,并对各类神经网络编码工具和
基于神经网络的端到端视频编码进行了详细介
绍。同时展望了图像和视频编码领域目前面临的
挑战以及未来的发展方向与机遇。
2 基于神经网络的图像压缩
在图像压缩中应用神经网络技术最早起源于
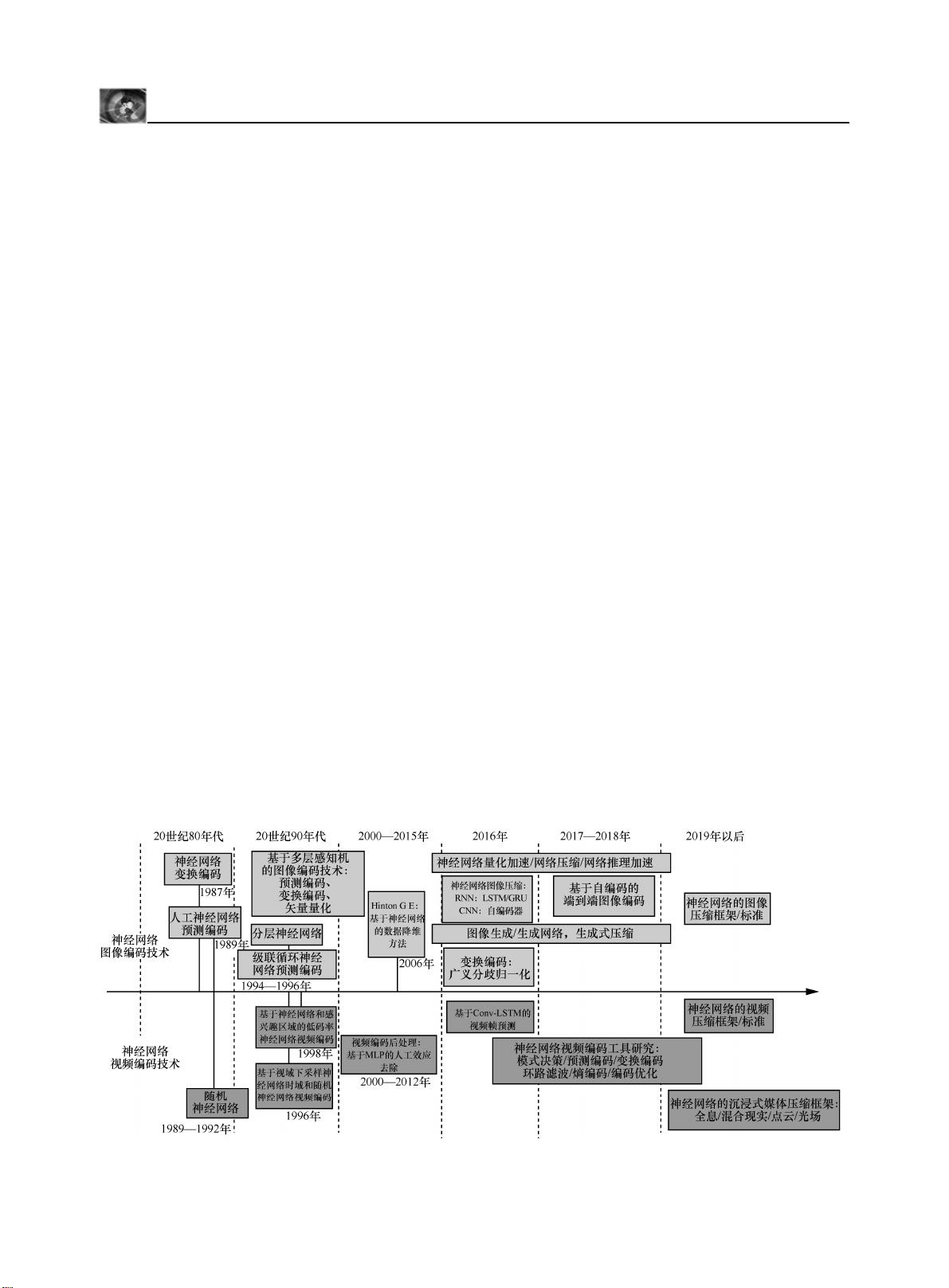
19 世纪 80 年代,如图 2 所示。此后伴随神经网络
结构的发展,多层感知机网络、随机神经网络、
卷积神经网络、循环神经网络以及生成对抗网络
等网络结构都对基于神经网络的图像编码发展起
到了很大的推动作用,将编码优化问题从基于手
工特征和规则的局部优化推向了端到端的全局
优化,从简单拟合率失真模型推向高度非线性
复杂问题的优化建模与求解。尤其是近年来基
于生成器—判别器的对抗学习范式引发了关于
生成模型的研究热潮,此类基于生成对抗网络
的压缩方法在提升压缩重建图像主观质量方面
取得显著效果。
2.1 基于多层感知机的图像压缩
多层感知机也通常被称为人工神经网络
(artificial neural network,ANN),其主要网络结
构由稠密连接的输入层、隐含层和输出层组成。
由于其能够实现对任意连续函数以足够小的误差
进行逼近
[9]
,这为高维数据的降维和压缩提供了
基础。1988 年,Chua 等人
[12]
提出基于 ANN 的端
到端图像压缩框架,该框架主要利用了 ANN 高密
图 2 基于神经网络的图像和视频编码相关技术发展历程
2019142-3
剩余10页未读,继续阅读
171 浏览量
239 浏览量
2021-09-19 上传
2021-09-19 上传
2021-09-26 上传
132 浏览量
2024-12-26 上传
点击了解资源详情

weixin_38717574
- 粉丝: 14
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- 模糊pid_大疆_模糊pid_电机_steering_stm32f105模糊pid_
- browserify-string-to-js:使用require(...)读取CSS文件,HTML文件等
- Kotlin-PWA-starter-kit:使用100%Kotlin创建渐进式Web应用程序
- 常用jar包.zip
- firt_react_project
- mern-task-manager
- module-extract-version:(Perl)这是模块的作用
- Rabbit MQ整体搭建以及demo.rar
- NI采集卡6009数据记录软件_ni6009_波形监控_
- Windows系统网络映射工具
- walkofclaim:手机游戏的开源版本
- aleusai.github.io
- 统计资料
- CanFestival-transplanted2stm32-master.zip
- webpack-1-demo
- alkyl:基于ElixirCowboy的Etherpad后端
