Java深度学习实战:探索DL4J、Theano与Caffe
"Java深度学习书籍,由Yusuke Sugomori撰写,Packt Publishing于2016年出版,ISBN:9781785282195,涵盖主题包括数据分析。本书旨在深入浅出地介绍数据科学的未来,并教授如何使用Java构建深度学习和人工智能的核心算法。适合于数据科学家、Java开发者以及想要利用深度学习进行项目开发的机器学习用户阅读。"
在《Java Deep Learning Essentials》这本书中,作者Yusuke Sugomori引领读者超越理论,将深度学习付诸实践。本书重点在于通过Java来实现深度学习,涵盖了多种领先框架,如DL4J、Theano和Caffe。无论你是数据科学家还是Java开发者,甚至是希望在大数据环境中应用深度学习的机器学习用户,都能从中受益。
本书中,读者将学到以下内容:
1. 进行深入的机器学习和深度学习算法实践。这不仅包括了理论知识的讲解,更注重实际操作,让读者能够动手实现这些复杂的算法。
2. 实现与深度学习相关的机器学习算法。深度学习是机器学习的一个分支,书中将介绍如何在Java环境下构建这些算法,以解决实际问题。
3. 探索使用流行深度学习框架构建的神经网络。DL4J、Theano和Caffe等框架提供了构建和训练神经网络的强大工具,读者将了解到如何运用这些框架来搭建和优化模型。
4. 学习如何运用深度学习技术处理大数据环境中的问题。随着大数据时代的到来,深度学习在处理大规模数据集时的优势越来越明显,本书将指导读者在这样的环境中有效应用深度学习。
5. 逐步指导,从基础知识到高级技巧,帮助读者逐步建立深度学习项目。这将涉及数据预处理、模型训练、验证和评估,以及模型的部署和维护。
6. 了解深度学习的实际应用案例。通过具体的项目实例,读者可以更好地理解深度学习在图像识别、自然语言处理、推荐系统等领域中的应用。
《Java Deep Learning Essentials》是一本面向实践者的深度学习指南,它将帮助读者掌握深度学习的关键概念和工具,提升在Java开发中的数据科学能力。对于希望在Java环境中开展深度学习工作的专业人士来说,这是一本不可多得的参考资料。

For those of you who are interested in this field, let's look into how a machine plays chess in more detail. Let's
say a machine makes the first move as "white," and there are 20 possible moves for both "white" and "black" for
the next move. Remember the tree-like model in the preceding diagram. From the top of the tree at the start of the
game, there are 20 branches underneath as white's next possible move. Under one of these 20 branches, there's another
20 branches underneath as black's next possible movement, and so on. In this case, the tree has 20 x 20 = 400 branches
for black, depending on how white moves, 400 x 20 = 8,000 branches for white, 8,000 x 20 = 160,000 branches again
for black, and... feel free to calculate this if you like.
A machine generates this tree and evaluates every possible board position from these branches, deciding the best
arrangement in a second. How deep it goes (how many levels of the tree it generates and evaluates) is controlled
by the speed of the machine. Of course, each different piece's movement should also be considered and embedded in
a program, so the chess program is not as simple as previously thought, but we won't go into detail about this in
this book. As you can see, it's not surprising that a machine can beat a human at Chess. A machine can evaluate
and calculate massive amounts of patterns at the same time, in a much shorter time than a human could. It's not
a new story that a machine has beaten a Chess champion; a machine has won a game over a human. Because of stories
like this, people expected that AI would become a true story.
Unfortunately, reality is not that easy. We then found out that there was a big wall in front of us preventing us
from applying the search algorithm to reality. Reality is, as you know, complicated. A machine is good at processing
things at high speed based on a given set of rules, but it cannot find out how to act and what rules to apply by
itself when only a task is given. Humans unconsciously evaluate, discard many things/options that are not related
to them, and make a choice from millions of things (patterns) in the real world whenever they act. A machine cannot
make these unconscious decisions like humans can. If we create a machine that can appropriately consider a phenomenon
that happens in the real world, we can assume two possibilities:
A machine tries to accomplish its task or purpose without taking into account secondarily occurring incidents and possibilities
A machine tries to accomplish its task or purpose without taking into account irrelevant incidents and possibilities
Both of these machines would still freeze and be lost in processing before they accomplished their purpose when
humans give them a task; in particular, the latter machine would immediately freeze before even taking its first
action. This is because these elements are almost infinite and a machine can't sort them out within a realistic
time if it tries to think/search these infinite patterns. This issue is recognized as one of the important challenges
in the AI field, and it's called the frame problem.
A machine can achieve great success in the field of Chess or Shogi because the searching space, the space a machine
should be processing within, is limited (set in a certain frame) in advance. You can't write out an enormous amount
of patterns, so you can't define what the best solution is. Even if you are forced to limit the number of patterns
or to define an optimal solution, you can't get the result within an economical time frame for use due to the enormous
amounts of calculation needed. After all, the research at that time would only make a machine follow detailed rules
set by a human. As such, although this search method could succeed in a specific area, it is far from achieving
actual AI. Therefore, the first AI boom cooled down rapidly with disappointment.
The first AI boom was swept away; however, on the side, the research into AI continued. The second AI boom came
in the 1980s. This time, the movement of so-called Knowledge Representation (KR) was booming. KR intended to describe
knowledge that a machine could easily understand. If all the knowledge in the world was integrated into a machine
and a machine could understand this knowledge, it should be able to provide the right answer even if it is given
a complex task. Based on this assumption, various methods were developed for designing knowledge for a machine to
understand better. For example, the structured forms on a web page—the semantic web—is one example of an approach
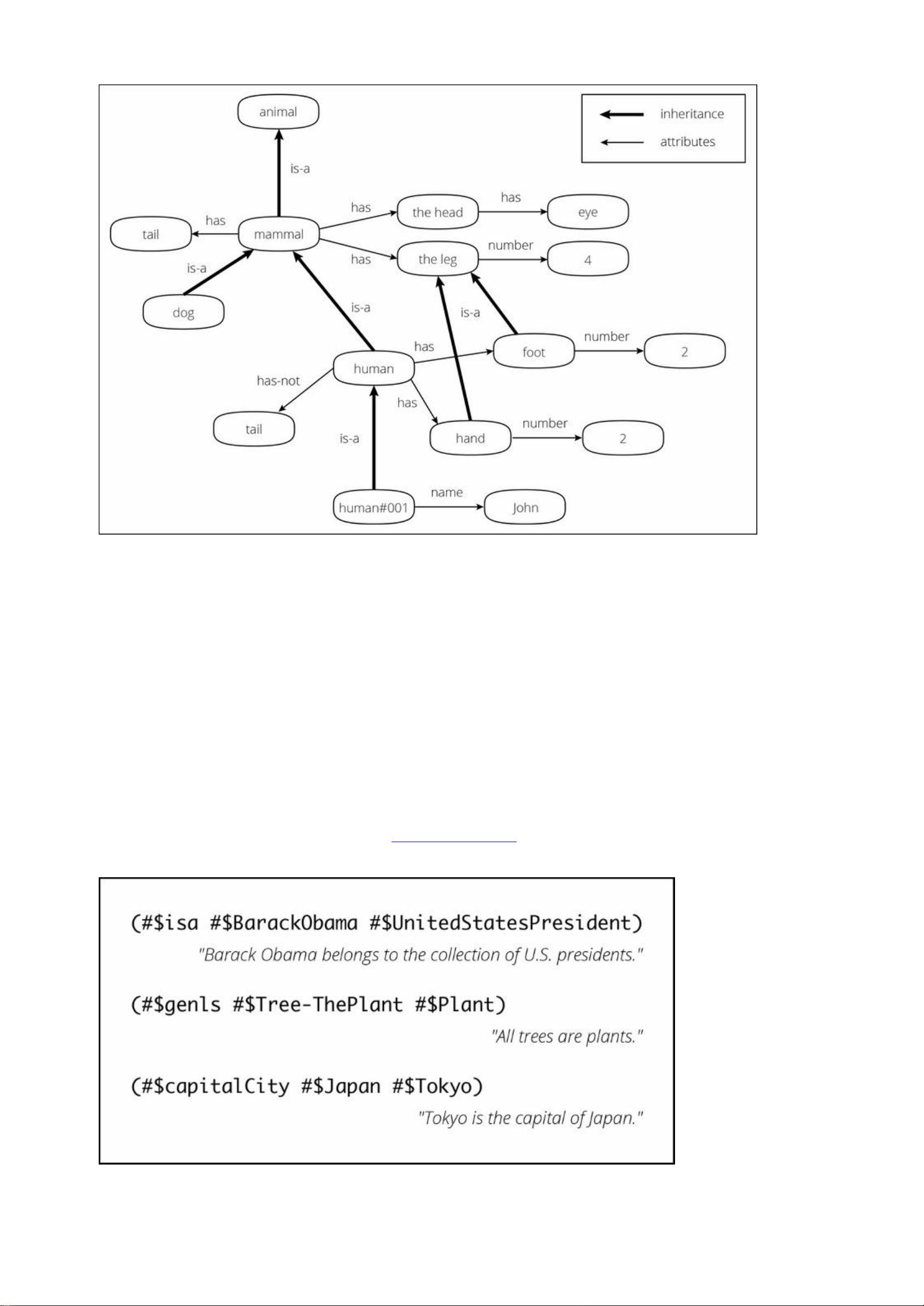
that tried to design in order for a machine to understand information easier. An example of how the semantic web
is described with KR is shown here:



剩余153页未读,继续阅读
2017-11-22 上传
2018-04-03 上传
2018-12-22 上传
2016-05-05 上传
2011-01-12 上传
2017-05-27 上传

cqiao0
- 粉丝: 5
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
