机器学习中的K-means聚类分析
需积分: 9 90 浏览量
更新于2024-07-21
收藏 224KB PPTX 举报
"聚类分析是数据挖掘中的一个重要技术,用于将相似的数据分为不同的组或簇。此PPT详细介绍了聚类分析的基本概念、层次聚类(Hierarchical Clustering)和K-means聚类方法,以及相关的算法实现。"
在机器学习和数据挖掘中,聚类分析是一种无监督学习方法,其目标是依据数据的内在特性,将数据集分割成多个群组,使得在同一群组内的数据彼此相似,而不同群组之间的数据差异较大。聚类分析可以帮助我们发现数据的隐藏结构,无需预先知道具体的类别标签。
一、简介
聚类分析主要基于数据的相似性或距离度量,通过构建簇来揭示数据的自然分组。它可以应用于各种领域,如市场细分、生物信息学、社交网络分析等。
二、Hierarchical Clustering(层次聚类)
层次聚类分为凝聚型(Agglomerative)和分裂型(Divisive)两种。凝聚型从单个数据点开始,逐步合并相似的群组;分裂型则从所有数据点构成的大群组开始,逐渐分裂成小群组。层次聚类通常生成树状结构(Dendrogram),便于可视化分析群组关系。
三、K-means聚类及扩展
1. K-means是最简单的聚类算法之一,它的基本思想是将数据分配到最近的聚类中心。K值代表期望的群组数量,需要预先设定。
2. Lloyd's Algorithm(k-means算法)包括初始化步骤、分配步骤和更新步骤。在初始化时,随机选择k个数据点作为初始聚类中心;分配步骤中,根据样本点与聚类中心的距离,将数据点分配到最近的聚类;更新步骤中,重新计算每个聚类的中心,即所有成员的均值。这个过程重复进行,直到聚类中心不再显著改变或达到预设的最大迭代次数。
3. K-means的一个挑战是需要预先设定K值,而且对初始聚类中心的选择敏感,可能导致局部最优解。为了改进,出现了Fuzzy C-Means(FCM)和并行K-means等方法。
四、K-means算法复杂度
K-means的时间复杂度为O(knpi),其中k是聚类个数,n是样本量,p是特征维度,i是迭代次数。在大数据集上,这可能会变得相当昂贵。为了提高效率,可以采用mini-batch K-means等优化策略。
五、R语言实现
R语言提供了多种实现聚类分析的包,例如`cluster`包和`fpc`包,它们包含多种聚类算法,如kmeans()函数可直接执行K-means聚类。
聚类分析是一个强大且广泛应用的数据分析工具,通过理解和掌握不同聚类方法,我们可以更好地理解和探索数据集的内在结构。在实际应用中,选择合适的聚类方法,结合业务理解,可以有效地提炼出有价值的信息。
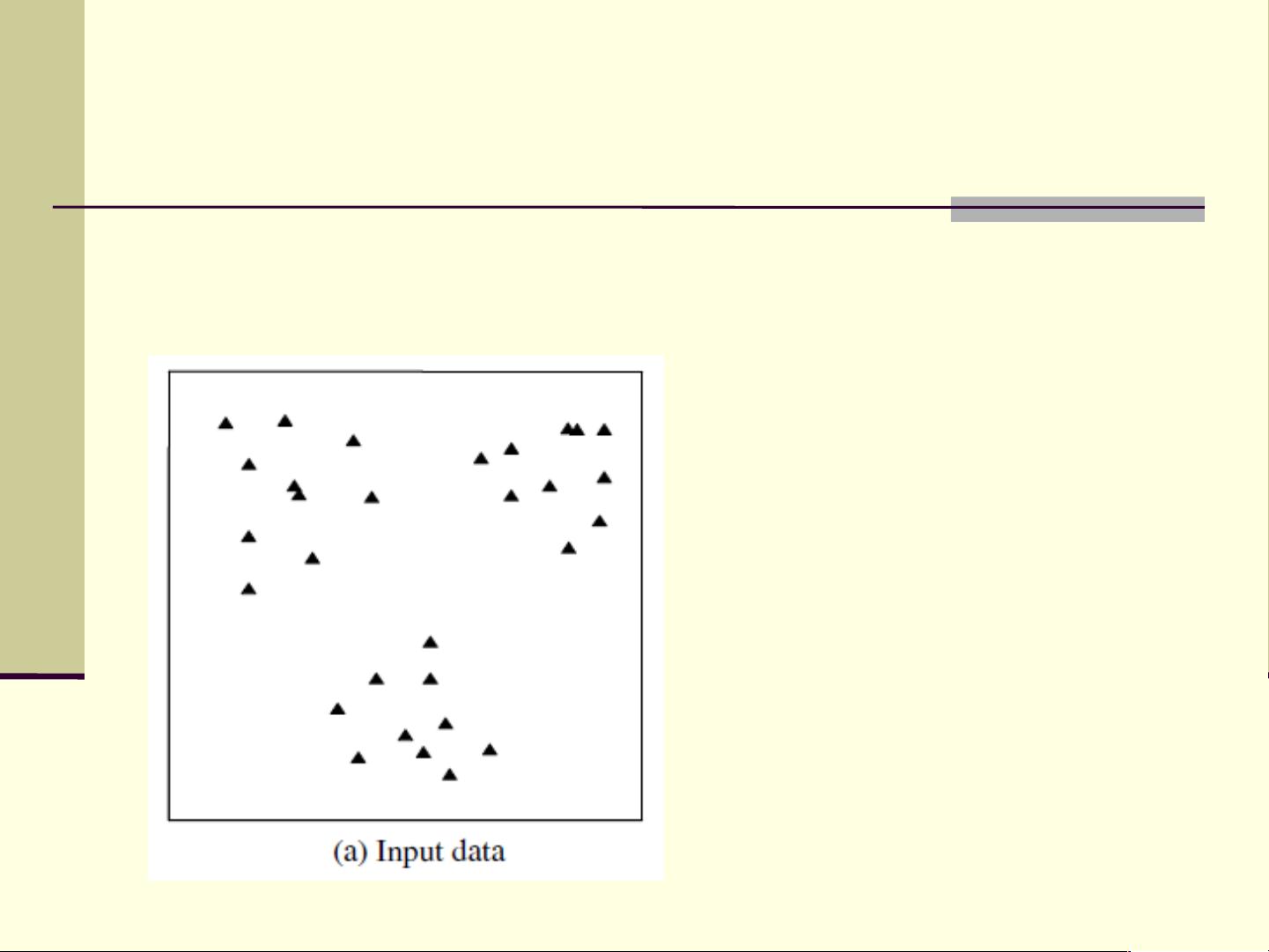
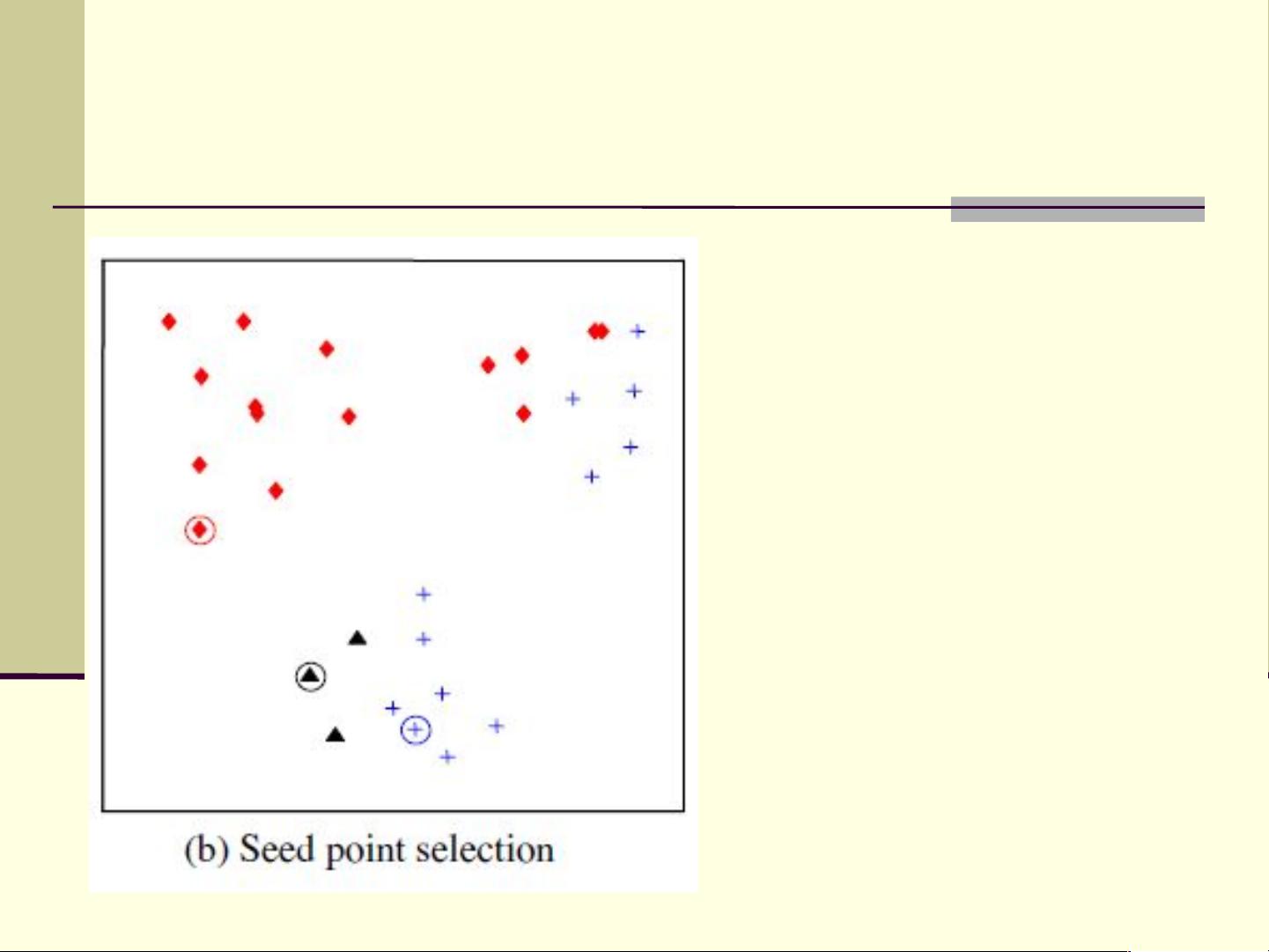
例子
原始数据 :
K-means: K=3
剩余30页未读,继续阅读
2009-07-31 上传
2009-03-16 上传
2021-10-11 上传
2021-10-04 上传
2021-05-09 上传

francismail
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- c#基础教程(pdf)
- Addison.Wesley.Modern.C++.Design-.Generic.Programming.and.Design.Patterns.Applied.pdf
- Addison.Wesley.Efficient.C++.Performance.Programming.Techniques.pdf
- JSP如何连接mysql
- cookies的注入方法和原理.doc
- Addison.Wesley.Effective.Stl.50.Specific.Ways.To.Improve.Your.Use.Of.Stl.pdf
- 2007年上半年程序员上午题
- Addison.Wesley.Concrete.Mathematics.A.Foundation.for.Computer.Science.pdf
- 《网络攻击透视与防范》上机指导书
- Addison.Wesley.Bjarne.Stroustrup.The.C++.Programming.Language.Third.Edition.pdf
- A R M 开 发 详 解
- autorun.inf文件夹如何删除
- the art of designing embedded system
- TOAD快速入门中文教程
- windows DOS命令大全
- 西门子S7-300编程手册
