新浪ELK集群运维与服务平台建设实践
"新浪ELK-从运维到服务之路"
这篇文档详细介绍了新浪在ELK(Elasticsearch, Logstash, Kibana)集群运维和服务构建的历程,由一位有着丰富经验的前新浪MySQL DBA和大数据工程师分享。作者强调了在运维50+节点的ELK集群中所面临的挑战与解决方案,以及如何通过架构演进来提高系统的性能和稳定性。
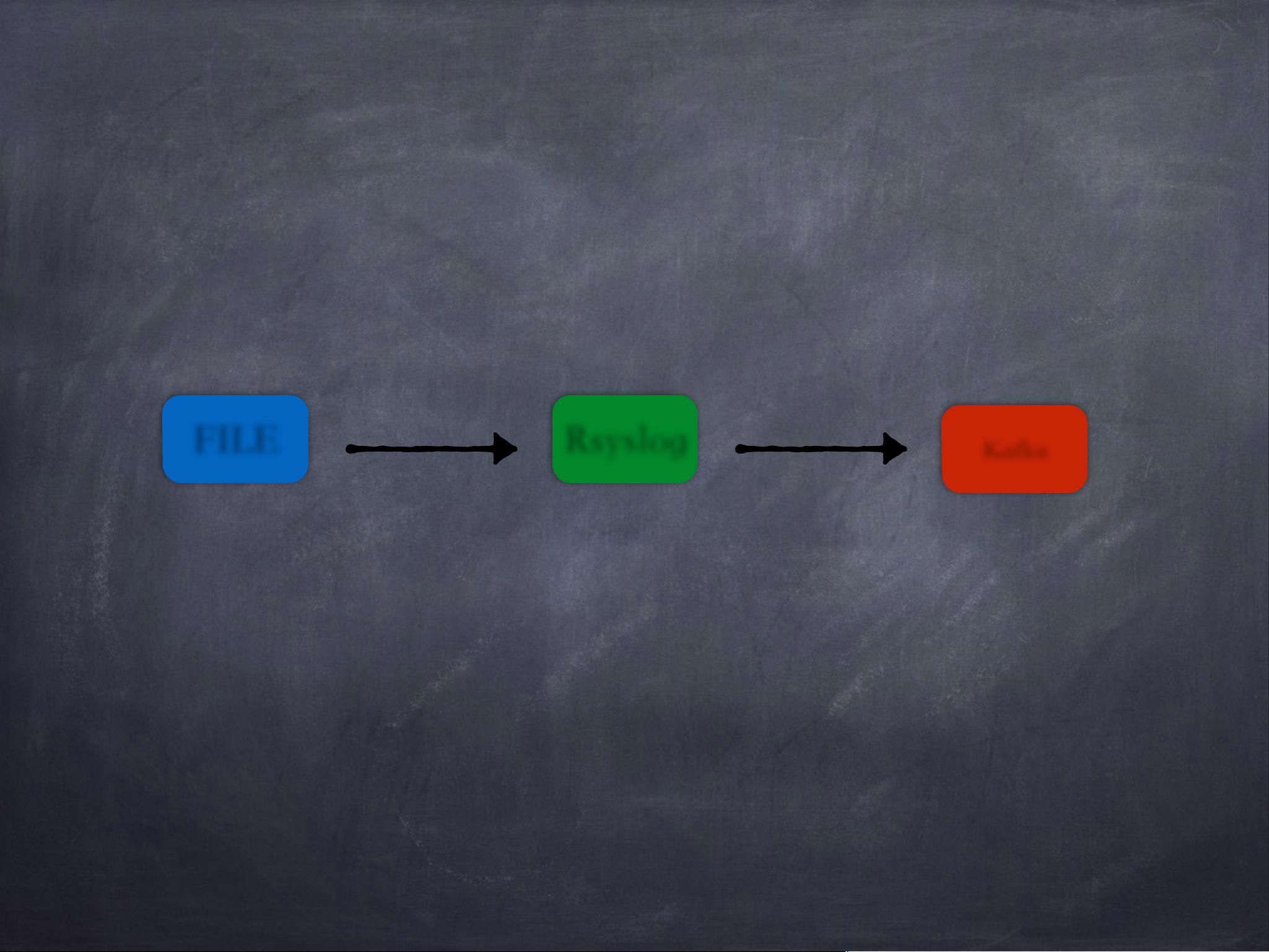
首先,文章提到了ELK集群的架构演进。早期阶段,系统依赖于Rsyslog收集日志,但随着日志量的增长,出现了高峰期上游日志堆积的问题。为了解决这个问题,他们引入了Kafka,利用其高吞吐量、基于Topic的发布/订阅模型、硬盘顺序写和Zero-Copy技术来增强系统的实时性和可扩展性。Kafka的引入不仅解决了日志堆积问题,还能够支持更丰富的计算模式,并允许预先进行固定维度的分析,提升了并发处理能力。
在工具选择和使用上,文章提到了几个关键的辅助工具,如KOPF和Bigdesk用于Elasticsearch集群的可视化管理和性能监控,Grok Debugger用于在线测试Logstash的Grok解析规则,而Curtor则是一个Elasticsearch索引管理工具,这些工具帮助运维团队提升了工作效率和问题排查能力。
随着业务的不断增长,ELK集群逐渐走向自动化和平台化。作者分享了从接入5个业务开始,逐步处理各种故障,直至规划未来服务的发展过程。这一部分强调了构建自动化流程和平台的重要性,包括整体架构设计、日志格式标准化、数据管理系统的构建、移动端日志服务的提供,以及服务的Docker化,以实现更高效、灵活的运维。
在整体架构介绍中,Kafka作为消息中间件,起到了关键的角色,连接了各个业务日志源,而Spark Stream则可能被用来进行实时流处理和数据分析。整个系统的设计目标是提升数据处理效率,同时确保服务的稳定性和可靠性。
这篇文档深入探讨了新浪在ELK运维和服务优化上的实践经验,对于理解大规模日志处理系统的架构设计、性能优化以及自动化运维策略具有很高的参考价值。

运维一个50+的ELK集群
架构演进之路
具介绍
剩余25页未读,继续阅读
2017-04-15 上传
115 浏览量
2024-02-24 上传
110 浏览量
2022-11-01 上传
点击了解资源详情

tangdong3415
- 粉丝: 147
 我的内容管理
展开
我的内容管理
展开







最新资源
- 虚幻引擎4经典FPS游戏开发包解析
- 掌握LaTeX中psfig.sty的使用技巧
- 探索X102 51学习板:深入嵌入式系统开发
- 深入理解STM32外部中断的实现与应用
- 大冶市数字高程模型(DEM)数据详细解读
- 俄罗斯方块游戏制作教程:Protues实现指南
- ASP.NET视频点播系统源代码及论文:多技术项目资源集锦
- Platzi JavaScript课程体系:全面覆盖初、中、高级
- cutespotify:跨平台MeeSpot音乐播放器兼容SailfishOS
- PictureEx类:在VC6下显示jpg与gif动图
- 基于stc89C51的数字时钟Proteus仿真设计
- MATLAB全面基础教程与实践技巧分享
- 实现双行文字向上滚动效果的js插件
- Labview温度报警系统:实时监控与声光警报
- Java官网ehcache-2.7.3实例教程
- A-Frame超级组件集:超帧的创新与应用
