机器学习入门:聚类算法深度解析
需积分: 9 164 浏览量
更新于2024-07-20
1
收藏 3.11MB PDF 举报
"该资源是一份关于聚类学习的PDF教程,由龙心尘编著,主要内容涵盖了聚类算法的基本概念、应用场景、不同类型的距离计算、聚类算法的分类以及K-means、层次聚类、混合高斯模型等具体算法的介绍,并包含实例演示和应用场景分析,如新闻聚类、图像处理、用户行为分析等。"
在机器学习领域,聚类是一种无监督学习方法,主要用于发现数据中的内在结构和模式,而不依赖于预先标注的类别信息。聚类的核心在于通过度量样本之间的相似度或距离来将数据分组成不同的簇,每个簇内的样本相似度较高,而簇与簇之间的相似度较低。
聚类的应用广泛,如新闻聚类可帮助媒体快速组织和归类大量信息,图像处理中用于识别图像的特征,基因技术中则能揭示生物序列的模式。此外,它还可用于用户行为分析,如电商网站根据用户的购买历史进行用户分群,以便推送个性化推荐;邮件分类,将邮件自动归类到不同的主题中;异常检测,识别出与其他数据点显著不同的点。
在聚类中,衡量样本相似度或距离的方式有很多种。常见的有Minkovski距离,包括欧式距离(L2)和曼哈顿距离(L1),以及余弦距离。有时还会使用核函数映射后的距离,以处理非线性可分问题。特征转换后的距离可能会影响聚类的效果,例如,使用核函数可以将数据映射到高维空间,使得原本难以分隔的数据变得容易聚类。
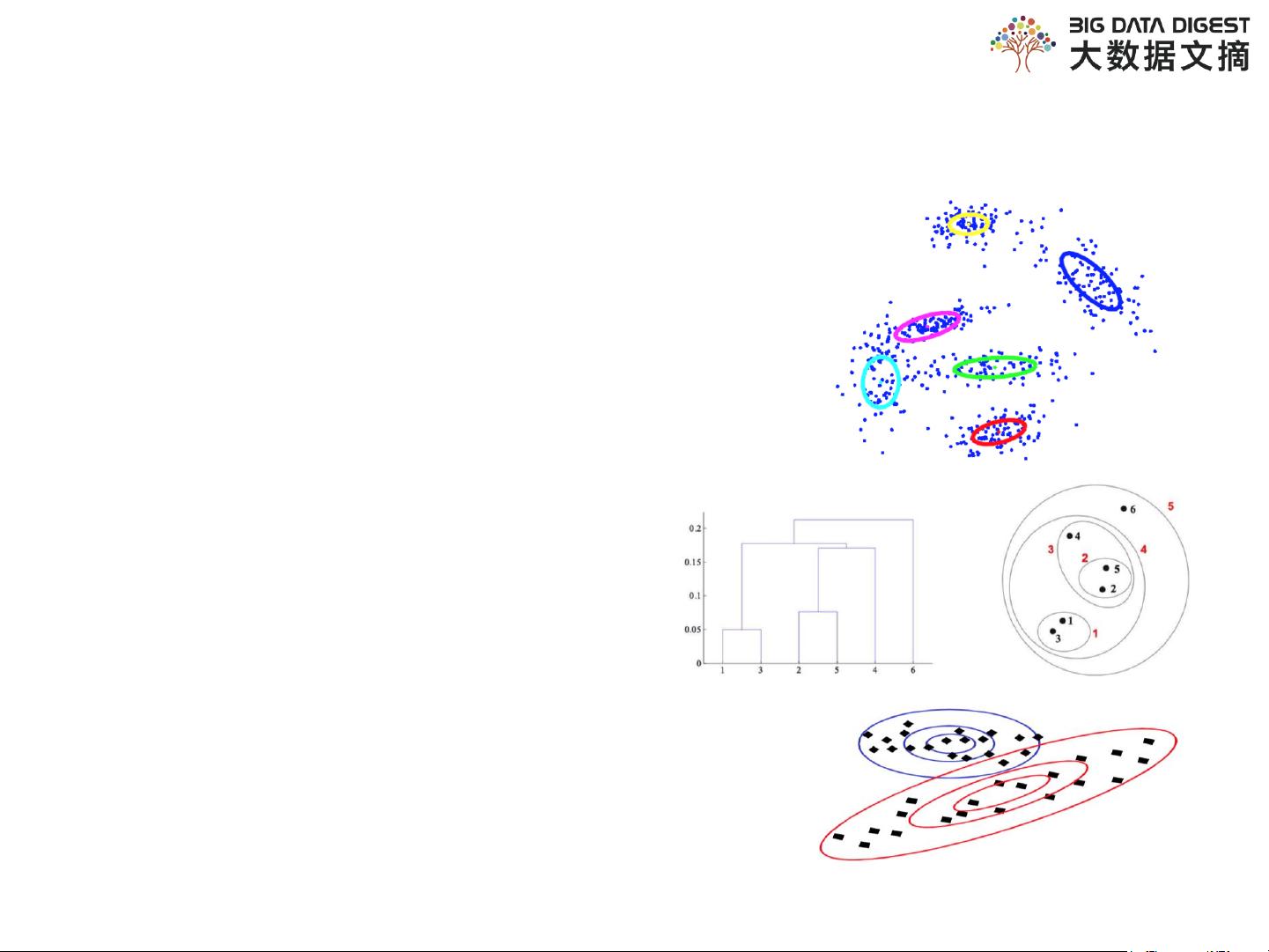
聚类算法家族庞大,其中包括基于位置的聚类算法,如K-means,这是一种迭代算法,通过寻找质心并重新分配样本至最近的质心来优化聚类。K-means的变体有k-medoids、k-modes、k-medians等,它们选择代表性的对象而非均值作为中心。层次聚类包括凝聚型(agglomerative)和分裂型(divisive),它们通过构建树状结构来形成簇。基于密度的聚类如DBSCAN,能够发现任意形状的簇,不受噪声点影响。基于网格的聚类和基于模型的聚类,如GMM(混合高斯模型),利用概率模型来描述数据分布。最后,还有一些基于神经网络的聚类方法。
K-means是最常见的聚类算法之一,它的输入包括样本集和簇的数量(k值),通过不断迭代更新质心和分配样本,直到满足停止条件(如质心不再变化、达到最大迭代次数)。然而,K-means对初始质心的选择敏感,且假设数据呈凸形分布,这限制了其在处理非凸或非球形簇时的效果。
总结来说,聚类是数据分析中的重要工具,用于无监督地探索数据的结构和规律,涉及多种距离度量和算法选择,理解并掌握这些知识对于数据科学家来说至关重要。
龙心尘|传播数据思维 普及数据文化
聚类算法分类
基于位置的聚类
比如K-means
及其变体k-medoids、k-modes、
k-medians、kernel k-means
层次聚类
agglomerative
BIRCH
基于密度的聚类
DBSCAN
基于网格的聚类
基于模型的聚类
GMM
基于神经网络模型的方法
10/56
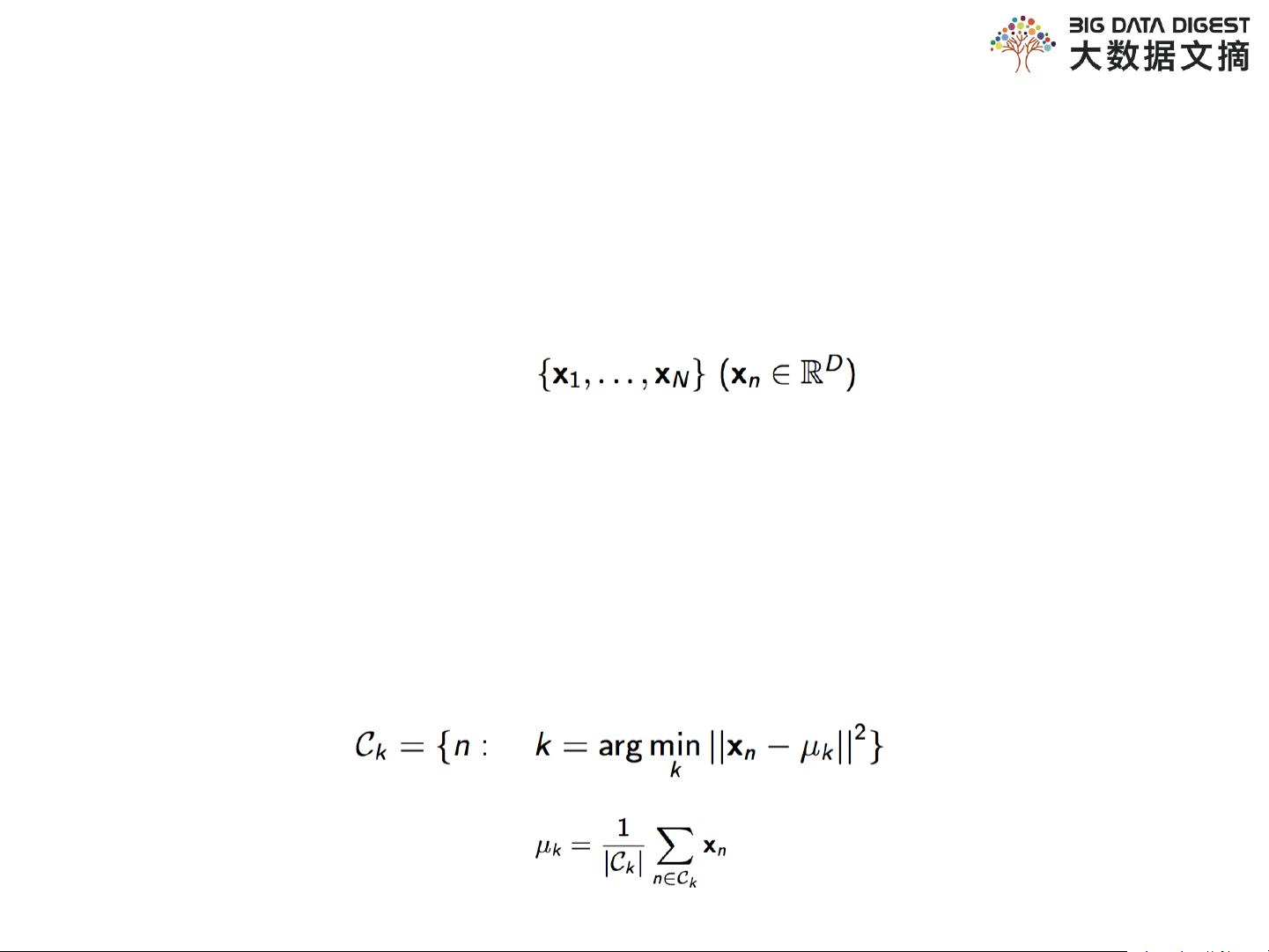
剩余55页未读,继续阅读
2023-11-25 上传
2023-11-25 上传
点击了解资源详情
2023-12-05 上传
2023-11-25 上传
2023-11-25 上传
2023-11-25 上传
2023-11-25 上传
2023-11-25 上传

loneghost
- 粉丝: 0
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
